 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Optimization with Logged Bandit Data
Apr 03, 2025We study how to use naturally available user feedback, such as clicks, to optimize large language model (LLM) pipelines for generating personalized sentences using prompts. Naive approaches, which estimate the policy gradient in the prompt space, suffer either from variance caused by the large action space of prompts or bias caused by inaccurate reward predictions. To circumvent these challenges, we propose a novel kernel-based off-policy gradient method, which estimates the policy gradient by leveraging similarity among generated sentences, substantially reducing variance while suppressing the bias. Empirical results on our newly established suite of benchmarks demonstrate the effectiveness of the proposed approach in generating personalized descriptions for movie recommendations, particularly when the number of candidate prompts is large.
Efficiently Escaping Saddle Points under Generalized Smoothness via Self-Bounding Regularity
Mar 06, 2025

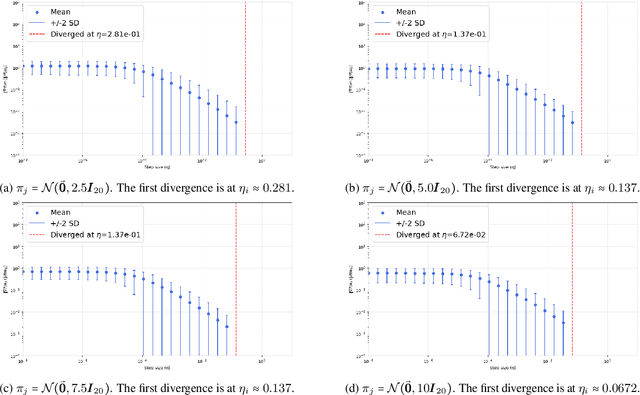

In this paper, we study the problem of non-convex optimization on functions that are not necessarily smooth using first order methods. Smoothness (functions whose gradient and/or Hessian are Lipschitz) is not satisfied by many machine learning problems in both theory and practice, motivating a recent line of work studying the convergence of first order methods to first order stationary points under appropriate generalizations of smoothness. We develop a novel framework to study convergence of first order methods to first and \textit{second} order stationary points under generalized smoothness, under more general smoothness assumptions than the literature. Using our framework, we show appropriate variants of GD and SGD (e.g. with appropriate perturbations) can converge not just to first order but also \textit{second order stationary points} in runtime polylogarithmic in the dimension. To our knowledge, our work contains the first such result, as well as the first 'non-textbook' rate for non-convex optimization under generalized smoothness. We demonstrate that several canonical non-convex optimization problems fall under our setting and framework.
Gradient Descent on Logistic Regression with Non-Separable Data and Large Step Sizes
Jun 07, 2024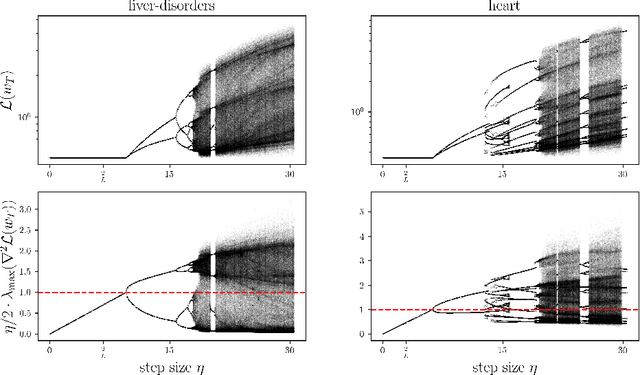
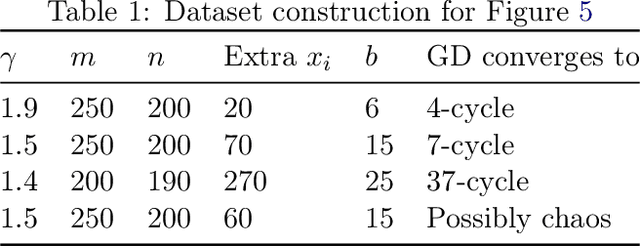
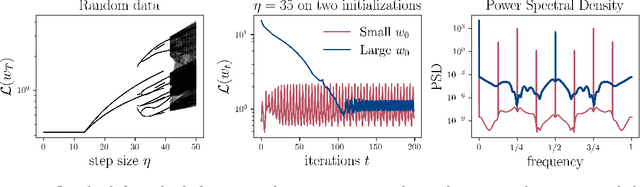
We study gradient descent (GD) dynamics on logistic regression problems with large, constant step sizes. For linearly-separable data, it is known that GD converges to the minimizer with arbitrarily large step sizes, a property which no longer holds when the problem is not separable. In fact, the behaviour can be much more complex -- a sequence of period-doubling bifurcations begins at the critical step size $2/\lambda$, where $\lambda$ is the largest eigenvalue of the Hessian at the solution. Using a smaller-than-critical step size guarantees convergence if initialized nearby the solution: but does this suffice globally? In one dimension, we show that a step size less than $1/\lambda$ suffices for global convergence. However, for all step sizes between $1/\lambda$ and the critical step size $2/\lambda$, one can construct a dataset such that GD converges to a stable cycle. In higher dimensions, this is actually possible even for step sizes less than $1/\lambda$. Our results show that although local convergence is guaranteed for all step sizes less than the critical step size, global convergence is not, and GD may instead converge to a cycle depending on the initialization.