 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimism is All You Need: Model-Based Imitation Learning From Observation Alone
Paper and Code
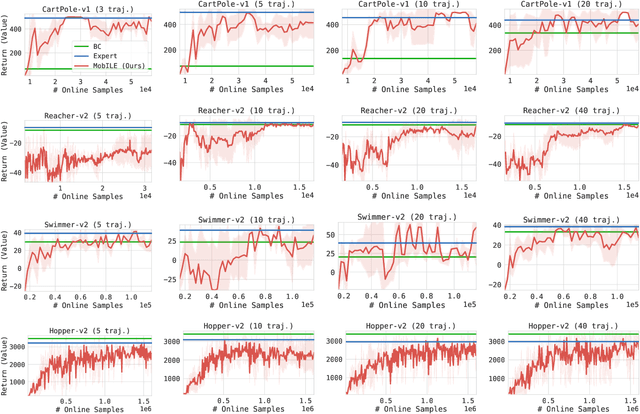
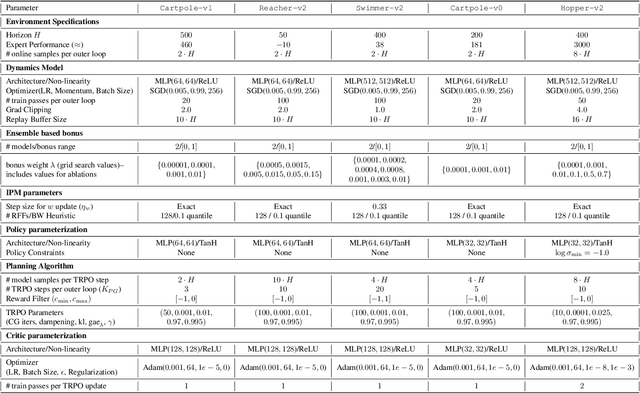

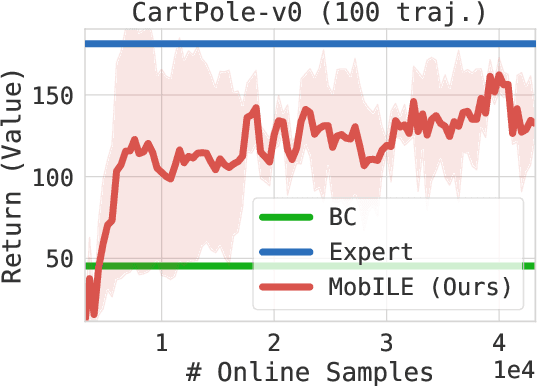
This paper studies Imitation Learning from Observations alone (ILFO) where the learner is presented with expert demonstrations that only consist of states encountered by an expert (without access to actions taken by the expert). We present a provably efficient model-based framework MobILE to solve the ILFO problem. MobILE involves carefully trading off exploration against imitation - this is achieved by integrating the idea of optimism in the face of uncertainty into the distribution matching imitation learning (IL) framework. We provide a unified analysis for MobILE, and demonstrate that MobILE enjoys strong performance guarantees for classes of MDP dynamics that satisfy certain well studied notions of complexity. We also show that the ILFO problem is strictly harder than the standard IL problem by reducing ILFO to a multi-armed bandit problem indicating that exploration is necessary for ILFO. We complement these theoretical results with experimental simulations on benchmark OpenAI Gym tasks that indicate the efficacy of MobILE.