 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXeroAlign: Zero-Shot Cross-lingual Transformer Alignment
Paper and Code


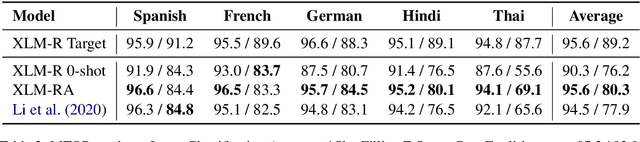

The introduction of pretrained cross-lingual language models brought decisive improvements to multilingual NLP tasks. However, the lack of labelled task data necessitates a variety of methods aiming to close the gap to high-resource languages. Zero-shot methods in particular, often use translated task data as a training signal to bridge the performance gap between the source and target language(s). We introduce XeroAlign, a simple method for task-specific alignment of cross-lingual pretrained transformers such as XLM-R. XeroAlign uses translated task data to encourage the model to generate similar sentence embeddings for different languages. The XeroAligned XLM-R, called XLM-RA, shows strong improvements over the baseline models to achieve state-of-the-art zero-shot results on three multilingual natural language understanding tasks. XLM-RA's text classification accuracy exceeds that of XLM-R trained with labelled data and performs on par with state-of-the-art models on a cross-lingual adversarial paraphrasing task.