 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Graph Convolutional Neural Networks for Multihop Reasoning: A Comparative Study
Oct 13, 2022
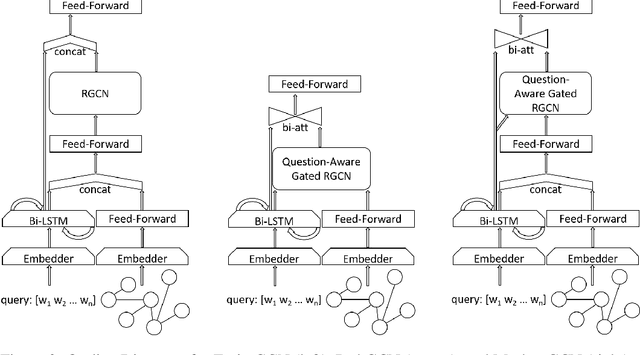


Multihop Question Answering is a complex Natural Language Processing task that requires multiple steps of reasoning to find the correct answer to a given question. Previous research has explored the use of models based on Graph Neural Networks for tackling this task. Various architectures have been proposed, including Relational Graph Convolutional Networks (RGCN). For these many node types and relations between them have been introduced, such as simple entity co-occurrences, modelling coreferences, or "reasoning paths" from questions to answers via intermediary entities. Nevertheless, a thoughtful analysis on which relations, node types, embeddings and architecture are the most beneficial for this task is still missing. In this paper we explore a number of RGCN-based Multihop QA models, graph relations, and node embeddings, and empirically explore the influence of each on Multihop QA performance on the WikiHop dataset.
Improving Commonsense Causal Reasoning by Adversarial Training and Data Augmentation
Jan 13, 2021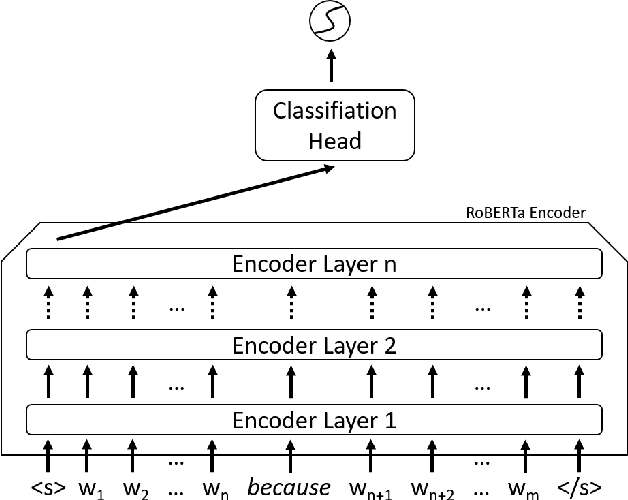
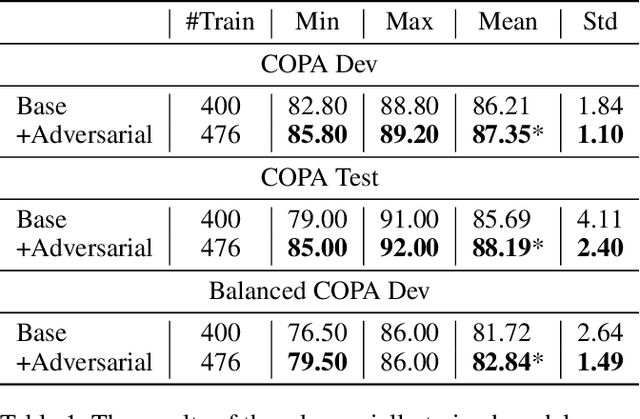
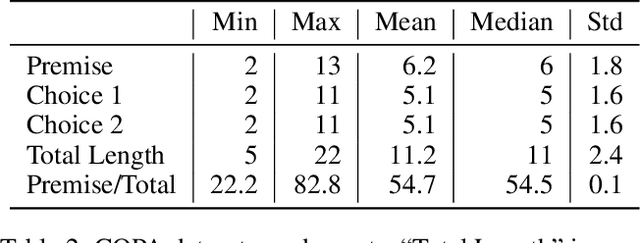
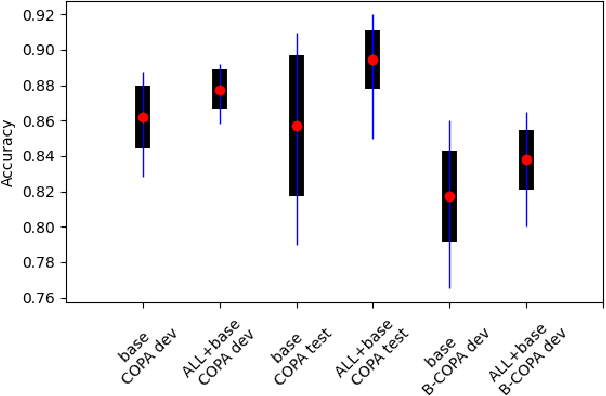
Determining the plausibility of causal relations between clauses is a commonsense reasoning task that requires complex inference ability. The general approach to this task is to train a large pretrained language model on a specific dataset. However, the available training data for the task is often scarce, which leads to instability of model training or reliance on the shallow features of the dataset. This paper presents a number of techniques for making models more robust in the domain of causal reasoning. Firstly, we perform adversarial training by generating perturbed inputs through synonym substitution. Secondly, based on a linguistic theory of discourse connectives, we perform data augmentation using a discourse parser for detecting causally linked clauses in large text, and a generative language model for generating distractors. Both methods boost model performance on the Choice of Plausible Alternatives (COPA) dataset, as well as on a Balanced COPA dataset, which is a modified version of the original data that has been developed to avoid superficial cues, leading to a more challenging benchmark. We show a statistically significant improvement in performance and robustness on both datasets, even with only a small number of additionally generated data points.
Compositional and Lexical Semantics in RoBERTa, BERT and DistilBERT: A Case Study on CoQA
Sep 17, 2020


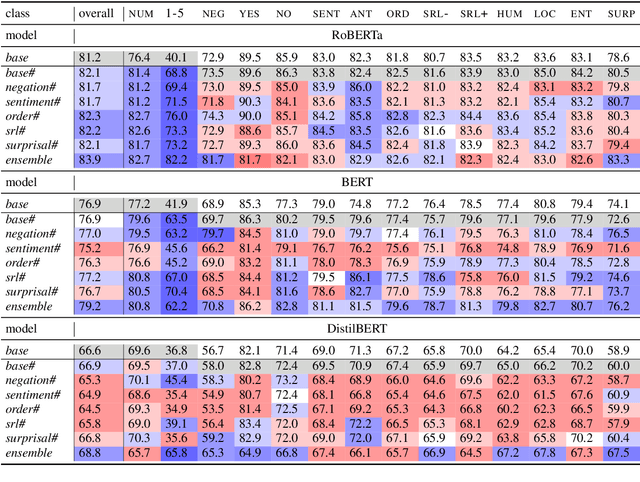
Many NLP tasks have benefited from transferring knowledge from contextualized word embeddings, however the picture of what type of knowledge is transferred is incomplete. This paper studies the types of linguistic phenomena accounted for by language models in the context of a Conversational Question Answering (CoQA) task. We identify the problematic areas for the finetuned RoBERTa, BERT and DistilBERT models through systematic error analysis - basic arithmetic (counting phrases), compositional semantics (negation and Semantic Role Labeling), and lexical semantics (surprisal and antonymy). When enhanced with the relevant linguistic knowledge through multitask learning, the models improve in performance. Ensembles of the enhanced models yield a boost between 2.2 and 2.7 points in F1 score overall, and up to 42.1 points in F1 on the hardest question classes. The results show differences in ability to represent compositional and lexical information between RoBERTa, BERT and DistilBERT.