 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional and Lexical Semantics in RoBERTa, BERT and DistilBERT: A Case Study on CoQA
Paper and Code



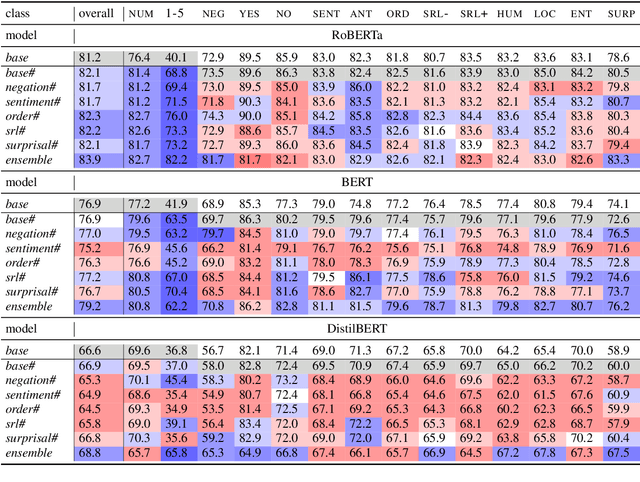
Many NLP tasks have benefited from transferring knowledge from contextualized word embeddings, however the picture of what type of knowledge is transferred is incomplete. This paper studies the types of linguistic phenomena accounted for by language models in the context of a Conversational Question Answering (CoQA) task. We identify the problematic areas for the finetuned RoBERTa, BERT and DistilBERT models through systematic error analysis - basic arithmetic (counting phrases), compositional semantics (negation and Semantic Role Labeling), and lexical semantics (surprisal and antonymy). When enhanced with the relevant linguistic knowledge through multitask learning, the models improve in performance. Ensembles of the enhanced models yield a boost between 2.2 and 2.7 points in F1 score overall, and up to 42.1 points in F1 on the hardest question classes. The results show differences in ability to represent compositional and lexical information between RoBERTa, BERT and DistilBERT.