 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFragility-aware Classification for Understanding Risk and Improving Generalization
Feb 18, 2025Classification models play a critical role in data-driven decision-making applications such as medical diagnosis, user profiling, recommendation systems, and default detection. Traditional performance metrics, such as accuracy, focus on overall error rates but fail to account for the confidence of incorrect predictions, thereby overlooking the risk of confident misjudgments. This risk is particularly significant in cost-sensitive and safety-critical domains like medical diagnosis and autonomous driving, where overconfident false predictions may cause severe consequences. To address this issue, we introduce the Fragility Index (FI), a novel metric that evaluates classification performance from a risk-averse perspective by explicitly capturing the tail risk of confident misjudgments. To enhance generalizability, we define FI within the robust satisficing (RS) framework, incorporating data uncertainty. We further develop a model training approach that optimizes FI while maintaining tractability for common loss functions. Specifically, we derive exact reformulations for cross-entropy loss, hinge-type loss, and Lipschitz loss, and extend the approach to deep learning models. Through synthetic experiments and real-world medical diagnosis tasks, we demonstrate that FI effectively identifies misjudgment risk and FI-based training improves model robustness and generalizability. Finally, we extend our framework to deep neural network training, further validating its effectiveness in enhancing deep learning models.
Revised Progressive-Hedging-Algorithm Based Two-layer Solution Scheme for Bayesian Reinforcement Learning
Jun 21, 2019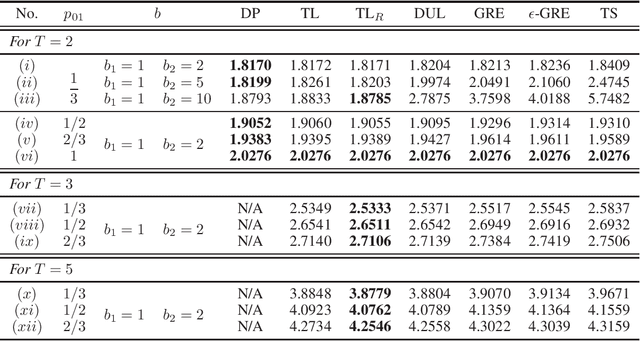
Stochastic control with both inherent random system noise and lack of knowledge on system parameters constitutes the core and fundamental topic in reinforcement learning (RL), especially under non-episodic situations where online learning is much more demanding. This challenge has been notably addressed in Bayesian RL recently where some approximation techniques have been developed to find suboptimal policies. While existing approaches mainly focus on approximating the value function, or on involving Thompson sampling, we propose a novel two-layer solution scheme in this paper to approximate the optimal policy directly, by combining the time-decomposition based dynamic programming (DP) at the lower layer and the scenario-decomposition based revised progressive hedging algorithm (PHA) at the upper layer, for a type of Bayesian RL problem. The key feature of our approach is to separate reducible system uncertainty from irreducible one at two different layers, thus decomposing and conquering. We demonstrate our solution framework more especially via the linear-quadratic-Gaussian problem with unknown gain, which, although seemingly simple, has been a notorious subject over more than half century in dual control.