 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIFFA-2: A Practical Diffusion Large Language Model for General Audio Understanding
Jan 30, 2026Autoregressive (AR) large audio language models (LALMs) such as Qwen-2.5-Omni have achieved strong performance on audio understanding and interaction, but scaling them remains costly in data and computation, and strictly sequential decoding limits inference efficiency. Diffusion large language models (dLLMs) have recently been shown to make effective use of limited training data, and prior work on DIFFA indicates that replacing an AR backbone with a diffusion counterpart can substantially improve audio understanding under matched settings, albeit at a proof-of-concept scale without large-scale instruction tuning, preference alignment, or practical decoding schemes. We introduce DIFFA-2, a practical diffusion-based LALM for general audio understanding. DIFFA-2 upgrades the speech encoder, employs dual semantic and acoustic adapters, and is trained with a four-stage curriculum that combines semantic and acoustic alignment, large-scale supervised fine-tuning, and variance-reduced preference optimization, using only fully open-source corpora. Experiments on MMSU, MMAU, and MMAR show that DIFFA-2 consistently improves over DIFFA and is competitive to strong AR LALMs under practical training budgets, supporting diffusion-based modeling is a viable backbone for large-scale audio understanding. Our code is available at https://github.com/NKU-HLT/DIFFA.git.
Reflecting Twice before Speaking with Empathy: Self-Reflective Alternating Inference for Empathy-Aware End-to-End Spoken Dialogue
Jan 26, 2026End-to-end Spoken Language Models (SLMs) hold great potential for paralinguistic perception, and numerous studies have aimed to enhance their capabilities, particularly for empathetic dialogue. However, current approaches largely depend on rigid supervised signals, such as ground-truth response in supervised fine-tuning or preference scores in reinforcement learning. Such reliance is fundamentally limited for modeling complex empathy, as there is no single "correct" response and a simple numerical score cannot fully capture the nuances of emotional expression or the appropriateness of empathetic behavior. To address these limitations, we sequentially introduce EmpathyEval, a descriptive natural-language-based evaluation model for assessing empathetic quality in spoken dialogues. Building upon EmpathyEval, we propose ReEmpathy, an end-to-end SLM that enhances empathetic dialogue through a novel Empathetic Self-Reflective Alternating Inference mechanism, which interleaves spoken response generation with free-form, empathy-related reflective reasoning. Extensive experiments demonstrate that ReEmpathy substantially improves empathy-sensitive spoken dialogue by enabling reflective reasoning, offering a promising approach toward more emotionally intelligent and empathy-aware human-computer interactions.
Cross-Modal Knowledge Distillation for Speech Large Language Models
Sep 18, 2025In this work, we present the first systematic evaluation of catastrophic forgetting and modality inequivalence in speech large language models, showing that introducing speech capabilities can degrade knowledge and reasoning even when inputs remain textual, and performance further decreases with spoken queries. To address these challenges, we propose a cross-modal knowledge distillation framework that leverages both text-to-text and speech-to-text channels to transfer knowledge from a text-based teacher model to a speech LLM. Extensive experiments on dialogue and audio understanding tasks validate the effectiveness of our approach in preserving textual knowledge, improving cross-modal alignment, and enhancing reasoning in speech-based interactions.
Chinese-LiPS: A Chinese audio-visual speech recognition dataset with Lip-reading and Presentation Slides
Apr 21, 2025Incorporating visual modalities to assist Automatic Speech Recognition (ASR) tasks has led to significant improvements. However, existing Audio-Visual Speech Recognition (AVSR) datasets and methods typically rely solely on lip-reading information or speaking contextual video, neglecting the potential of combining these different valuable visual cues within the speaking context. In this paper, we release a multimodal Chinese AVSR dataset, Chinese-LiPS, comprising 100 hours of speech, video, and corresponding manual transcription, with the visual modality encompassing both lip-reading information and the presentation slides used by the speaker. Based on Chinese-LiPS, we develop a simple yet effective pipeline, LiPS-AVSR, which leverages both lip-reading and presentation slide information as visual modalities for AVSR tasks. Experiments show that lip-reading and presentation slide information improve ASR performance by approximately 8\% and 25\%, respectively, with a combined performance improvement of about 35\%. The dataset is available at https://kiri0824.github.io/Chinese-LiPS/
Enhancing Gradient-based Discrete Sampling via Parallel Tempering
Feb 26, 2025While gradient-based discrete samplers are effective in sampling from complex distributions, they are susceptible to getting trapped in local minima, particularly in high-dimensional, multimodal discrete distributions, owing to the discontinuities inherent in these landscapes. To circumvent this issue, we combine parallel tempering, also known as replica exchange, with the discrete Langevin proposal and develop the Parallel Tempering enhanced Discrete Langevin Proposal (PTDLP), which are simulated at a series of temperatures. Significant energy differences prompt sample swaps, which are governed by a Metropolis criterion specifically designed for discrete sampling to ensure detailed balance is maintained. Additionally, we introduce an automatic scheme to determine the optimal temperature schedule and the number of chains, ensuring adaptability across diverse tasks with minimal tuning. Theoretically, we establish that our algorithm converges non-asymptotically to the target energy and exhibits faster mixing compared to a single chain. Empirical results further emphasize the superiority of our method in sampling from complex, multimodal discrete distributions, including synthetic problems, restricted Boltzmann machines, and deep energy-based models.
Statistical Device Activity Detection for OFDM-based Massive Grant-Free Access
Dec 31, 2021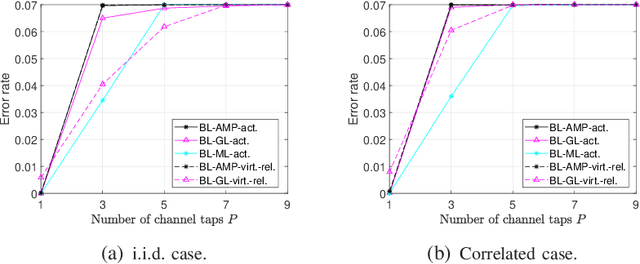

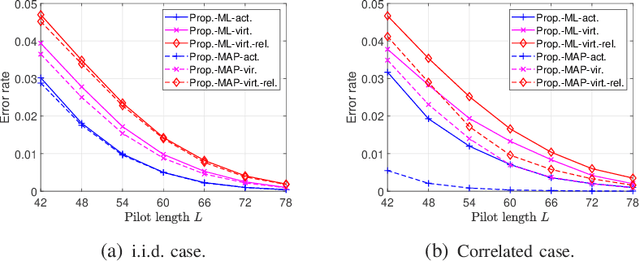
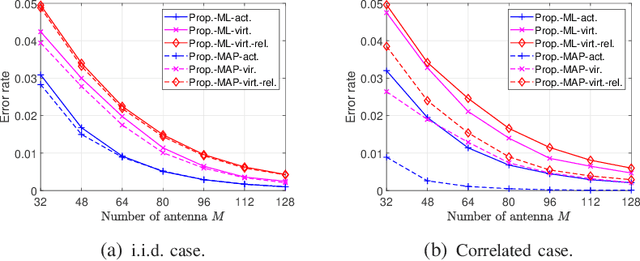
Existing works on grant-free access, proposed to support massive machine-type communication (mMTC) for the Internet of things (IoT), mainly concentrate on narrow band systems under flat fading. However, little is known about massive grant-free access for wideband systems under frequency-selective fading. This paper investigates massive grant-free access in a wideband system under frequency-selective fading. First, we present an orthogonal frequency division multiplexing (OFDM)-based massive grant-free access scheme. Then, we propose two different but equivalent models for the received pilot signal, which are essential for designing various device activity detection and channel estimation methods for OFDM-based massive grant-free access. One directly models the received signal for actual devices, whereas the other can be interpreted as a signal model for virtual devices. Next, we investigate statistical device activity detection under frequency-selective Rayleigh fading based on the two signal models. We first model device activities as unknown deterministic quantities and propose three maximum likelihood (ML) estimation-based device activity detection methods with different detection accuracies and computation times. We also model device activities as random variables with a known joint distribution and propose three maximum a posterior probability (MAP) estimation-based device activity methods, which further enhance the accuracies of the corresponding ML estimation-based methods. Optimization techniques and matrix analysis are applied in designing and analyzing these methods. Finally, numerical results show that the proposed statistical device activity detection methods outperform existing state-of-the-art device activity detection methods under frequency-selective Rayleigh fading.