 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Multimodal Conversational Agents with Coverage-Enhanced Latent Actions
Jan 12, 2026Vision-language models are increasingly employed as multimodal conversational agents (MCAs) for diverse conversational tasks. Recently, reinforcement learning (RL) has been widely explored for adapting MCAs to various human-AI interaction scenarios. Despite showing great enhancement in generalization performance, fine-tuning MCAs via RL still faces challenges in handling the extremely large text token space. To address this, we learn a compact latent action space for RL fine-tuning instead. Specifically, we adopt the learning from observation mechanism to construct the codebook for the latent action space, where future observations are leveraged to estimate current latent actions that could further be used to reconstruct future observations. However, the scarcity of paired image-text data hinders learning a codebook with sufficient coverage. Thus, we leverage both paired image-text data and text-only data to construct the latent action space, using a cross-modal projector for transforming text embeddings into image-text embeddings. We initialize the cross-modal projector on paired image-text data, and further train it on massive text-only data with a novel cycle consistency loss to enhance its robustness. We show that our latent action based method outperforms competitive baselines on two conversation tasks across various RL algorithms.
Understanding Generalization in Role-Playing Models via Information Theory
Dec 19, 2025Role-playing models (RPMs) are widely used in real-world applications but underperform when deployed in the wild. This degradation can be attributed to distribution shifts, including user, character, and dialogue compositional shifts. Existing methods like LLM-as-a-judge fall short in providing a fine-grained diagnosis of how these shifts affect RPM generalization, and thus there lack formal frameworks to characterize RPM generalization behaviors. To bridge these gaps, we introduce an information-theoretic metric, named reasoning-based effective mutual information difference (R-EMID), to measure RPM performance degradation in an interpretable way. We also derive an upper bound on R-EMID to predict the worst-case generalization performance of RPMs and theoretically reveal how various shifts contribute to the RPM performance degradation. Moreover, we propose a co-evolving reinforcement learning framework to adaptively model the connection among user, character, and dialogue context and thus enhance the estimation of dialogue response generation probability, which is critical for calculating R-EMID. Finally, we evaluate the generalization performance of various RPMs using R-EMID, finding that user shift poses the highest risk among all shifts and reinforcement learning is the most effective approach for enhancing RPM generalization.
Selective Weak-to-Strong Generalization
Nov 18, 2025Future superhuman models will surpass the ability of humans and humans will only be able to \textit{weakly} supervise superhuman models. To alleviate the issue of lacking high-quality data for model alignment, some works on weak-to-strong generalization (W2SG) finetune a strong pretrained model with a weak supervisor so that it can generalize beyond weak supervision. However, the invariable use of weak supervision in existing methods exposes issues in robustness, with a proportion of weak labels proving harmful to models. In this paper, we propose a selective W2SG framework to avoid using weak supervision when unnecessary. We train a binary classifier P(IK) to identify questions that a strong model can answer and use its self-generated labels for alignment. We further refine weak labels with a graph smoothing method. Extensive experiments on three benchmarks show that our method consistently outperforms competitive baselines. Further analyses show that P(IK) can generalize across tasks and difficulties, which indicates selective W2SG can help superalignment.
Scaling Data Diversity for Fine-Tuning Language Models in Human Alignment
Mar 30, 2024


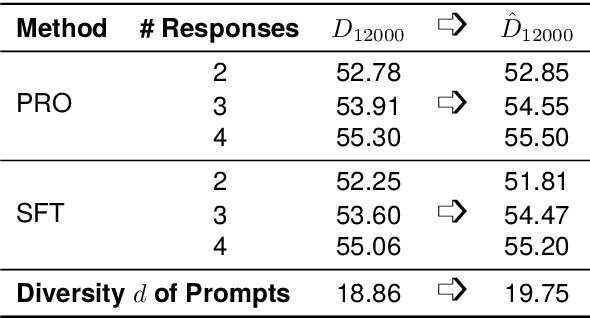
Alignment with human preference prevents large language models (LLMs) from generating misleading or toxic content while requiring high-cost human feedback. Assuming resources of human annotation are limited, there are two different ways of allocating considered: more diverse PROMPTS or more diverse RESPONSES to be labeled. Nonetheless, a straightforward comparison between their impact is absent. In this work, we first control the diversity of both sides according to the number of samples for fine-tuning, which can directly reflect their influence. We find that instead of numerous prompts, more responses but fewer prompts better trigger LLMs for human alignment. Additionally, the concept of diversity for prompts can be more complex than responses that are typically quantified by single digits. Consequently, a new formulation of prompt diversity is proposed, further implying a linear correlation with the final performance of LLMs after fine-tuning. We also leverage it on data augmentation and conduct experiments to show its effect on different algorithms.
Fine-Tuning Language Models with Reward Learning on Policy
Mar 28, 2024Reinforcement learning from human feedback (RLHF) has emerged as an effective approach to aligning large language models (LLMs) to human preferences. RLHF contains three steps, i.e., human preference collecting, reward learning, and policy optimization, which are usually performed serially. Despite its popularity, however, (fixed) reward models may suffer from inaccurate off-distribution, since policy optimization continuously shifts LLMs' data distribution. Repeatedly collecting new preference data from the latest LLMs may alleviate this issue, which unfortunately makes the resulting system more complicated and difficult to optimize. In this paper, we propose reward learning on policy (RLP), an unsupervised framework that refines a reward model using policy samples to keep it on-distribution. Specifically, an unsupervised multi-view learning method is introduced to learn robust representations of policy samples. Meanwhile, a synthetic preference generation approach is developed to simulate high-quality preference data with policy outputs. Extensive experiments on three benchmark datasets show that RLP consistently outperforms the state-of-the-art. Our code is available at \url{https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/rlp}.
Exploring Large Language Models for Multi-Modal Out-of-Distribution Detection
Oct 12, 2023Out-of-distribution (OOD) detection is essential for reliable and trustworthy machine learning. Recent multi-modal OOD detection leverages textual information from in-distribution (ID) class names for visual OOD detection, yet it currently neglects the rich contextual information of ID classes. Large language models (LLMs) encode a wealth of world knowledge and can be prompted to generate descriptive features for each class. Indiscriminately using such knowledge causes catastrophic damage to OOD detection due to LLMs' hallucinations, as is observed by our analysis. In this paper, we propose to apply world knowledge to enhance OOD detection performance through selective generation from LLMs. Specifically, we introduce a consistency-based uncertainty calibration method to estimate the confidence score of each generation. We further extract visual objects from each image to fully capitalize on the aforementioned world knowledge. Extensive experiments demonstrate that our method consistently outperforms the state-of-the-art.
Long-Tailed Question Answering in an Open World
May 11, 2023Real-world data often have an open long-tailed distribution, and building a unified QA model supporting various tasks is vital for practical QA applications. However, it is non-trivial to extend previous QA approaches since they either require access to seen tasks of adequate samples or do not explicitly model samples from unseen tasks. In this paper, we define Open Long-Tailed QA (OLTQA) as learning from long-tailed distributed data and optimizing performance over seen and unseen QA tasks. We propose an OLTQA model that encourages knowledge sharing between head, tail and unseen tasks, and explicitly mines knowledge from a large pre-trained language model (LM). Specifically, we organize our model through a pool of fine-grained components and dynamically combine these components for an input to facilitate knowledge sharing. A retrieve-then-rerank frame is further introduced to select in-context examples, which guild the LM to generate text that express knowledge for QA tasks. Moreover, a two-stage training approach is introduced to pre-train the framework by knowledge distillation (KD) from the LM and then jointly train the frame and a QA model through an adaptive mutual KD method. On a large-scale OLTQA dataset we curate from 43 existing QA datasets, our model consistently outperforms the state-of-the-art. We release the code and data at \url{https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/oltqa}.
Domain Incremental Lifelong Learning in an Open World
May 11, 2023Lifelong learning (LL) is an important ability for NLP models to learn new tasks continuously. Architecture-based approaches are reported to be effective implementations for LL models. However, it is non-trivial to extend previous approaches to domain incremental LL scenarios since they either require access to task identities in the testing phase or cannot handle samples from unseen tasks. In this paper, we propose \textbf{Diana}: a \underline{d}ynam\underline{i}c \underline{a}rchitecture-based lifelo\underline{n}g le\underline{a}rning model that tries to learn a sequence of tasks with a prompt-enhanced language model. Four types of hierarchically organized prompts are used in Diana to capture knowledge from different granularities. Specifically, we dedicate task-level prompts to capture task-specific knowledge to retain high LL performances and maintain instance-level prompts to learn knowledge shared across input samples to improve the model's generalization performance. Moreover, we dedicate separate prompts to explicitly model unseen tasks and introduce a set of prompt key vectors to facilitate knowledge sharing between tasks. Extensive experiments demonstrate that Diana outperforms state-of-the-art LL models, especially in handling unseen tasks. We release the code and data at \url{https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/diana}.
Out-of-Domain Intent Detection Considering Multi-turn Dialogue Contexts
May 05, 2023



Out-of-Domain (OOD) intent detection is vital for practical dialogue systems, and it usually requires considering multi-turn dialogue contexts. However, most previous OOD intent detection approaches are limited to single dialogue turns. In this paper, we introduce a context-aware OOD intent detection (Caro) framework to model multi-turn contexts in OOD intent detection tasks. Specifically, we follow the information bottleneck principle to extract robust representations from multi-turn dialogue contexts. Two different views are constructed for each input sample and the superfluous information not related to intent detection is removed using a multi-view information bottleneck loss. Moreover, we also explore utilizing unlabeled data in Caro. A two-stage training process is introduced to mine OOD samples from these unlabeled data, and these OOD samples are used to train the resulting model with a bootstrapping approach. Comprehensive experiments demonstrate that Caro establishes state-of-the-art performances on multi-turn OOD detection tasks by improving the F1-OOD score of over $29\%$ compared to the previous best method.
A Survey on Out-of-Distribution Detection in NLP
May 05, 2023Out-of-distribution (OOD) detection is essential for the reliable and safe deployment of machine learning systems in the real world. Great progress has been made over the past years. This paper presents the first review of recent advances in OOD detection with a particular focus on natural language processing approaches. First, we provide a formal definition of OOD detection and discuss several related fields. We then categorize recent algorithms into three classes according to the data they used: (1) OOD data available, (2) OOD data unavailable + in-distribution (ID) label available, and (3) OOD data unavailable + ID label unavailable. Third, we introduce datasets, applications, and metrics. Finally, we summarize existing work and present potential future research topics.