 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMProto: Multi-Prototype Network with Denoised Optimal Transport for Distantly Supervised Named Entity Recognition
Oct 12, 2023Distantly supervised named entity recognition (DS-NER) aims to locate entity mentions and classify their types with only knowledge bases or gazetteers and unlabeled corpus. However, distant annotations are noisy and degrade the performance of NER models. In this paper, we propose a noise-robust prototype network named MProto for the DS-NER task. Different from previous prototype-based NER methods, MProto represents each entity type with multiple prototypes to characterize the intra-class variance among entity representations. To optimize the classifier, each token should be assigned an appropriate ground-truth prototype and we consider such token-prototype assignment as an optimal transport (OT) problem. Furthermore, to mitigate the noise from incomplete labeling, we propose a novel denoised optimal transport (DOT) algorithm. Specifically, we utilize the assignment result between Other class tokens and all prototypes to distinguish unlabeled entity tokens from true negatives. Experiments on several DS-NER benchmarks demonstrate that our MProto achieves state-of-the-art performance. The source code is now available on Github.
PUMGPT: A Large Vision-Language Model for Product Understanding
Aug 18, 2023Recent developments of multi-modal large language models have demonstrated its strong ability in solving vision-language tasks. In this paper, we focus on the product understanding task, which plays an essential role in enhancing online shopping experience. Product understanding task includes a variety of sub-tasks, which require models to respond diverse queries based on multi-modal product information. Traditional methods design distinct model architectures for each sub-task. On the contrary, we present PUMGPT, a large vision-language model aims at unifying all product understanding tasks under a singular model structure. To bridge the gap between vision and text representations, we propose Layer-wise Adapters (LA), an approach that provides enhanced alignment with fewer visual tokens and enables parameter-efficient fine-tuning. Moreover, the inherent parameter-efficient fine-tuning ability allows PUMGPT to be readily adapted to new product understanding tasks and emerging products. We design instruction templates to generate diverse product instruction datasets. Simultaneously, we utilize open-domain datasets during training to improve the performance of PUMGPT and its generalization ability. Through extensive evaluations, PUMGPT demonstrates its superior performance across multiple product understanding tasks, including product captioning, category question-answering, attribute extraction, attribute question-answering, and even free-form question-answering about products.
PromptNER: Prompt Locating and Typing for Named Entity Recognition
May 26, 2023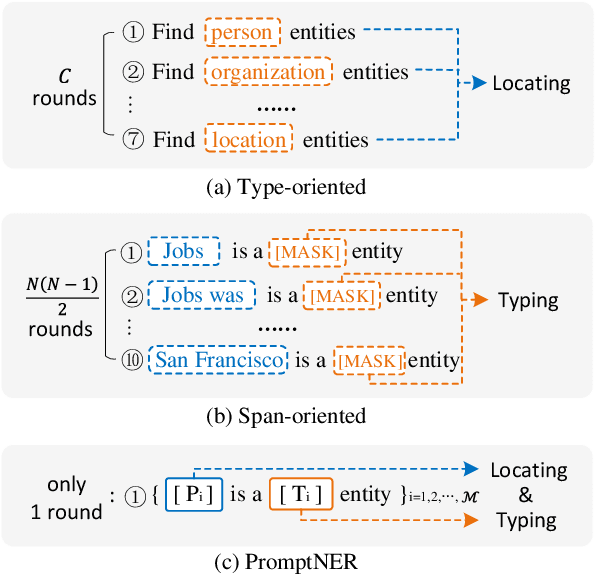
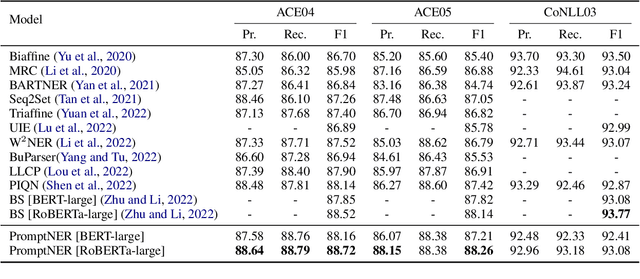
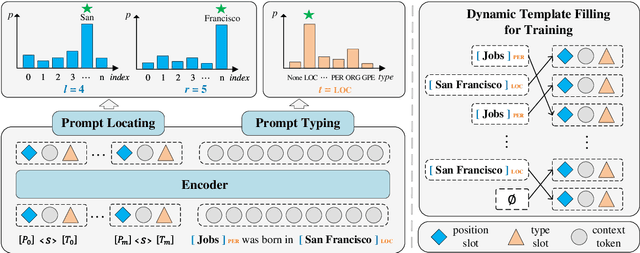
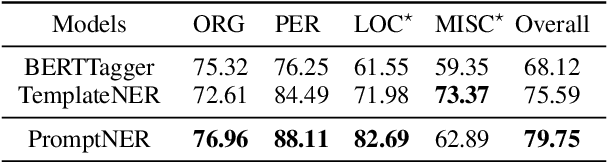
Prompt learning is a new paradigm for utilizing pre-trained language models and has achieved great success in many tasks. To adopt prompt learning in the NER task, two kinds of methods have been explored from a pair of symmetric perspectives, populating the template by enumerating spans to predict their entity types or constructing type-specific prompts to locate entities. However, these methods not only require a multi-round prompting manner with a high time overhead and computational cost, but also require elaborate prompt templates, that are difficult to apply in practical scenarios. In this paper, we unify entity locating and entity typing into prompt learning, and design a dual-slot multi-prompt template with the position slot and type slot to prompt locating and typing respectively. Multiple prompts can be input to the model simultaneously, and then the model extracts all entities by parallel predictions on the slots. To assign labels for the slots during training, we design a dynamic template filling mechanism that uses the extended bipartite graph matching between prompts and the ground-truth entities. We conduct experiments in various settings, including resource-rich flat and nested NER datasets and low-resource in-domain and cross-domain datasets. Experimental results show that the proposed model achieves a significant performance improvement, especially in the cross-domain few-shot setting, which outperforms the state-of-the-art model by +7.7% on average.
Propose-and-Refine: A Two-Stage Set Prediction Network for Nested Named Entity Recognition
Apr 27, 2022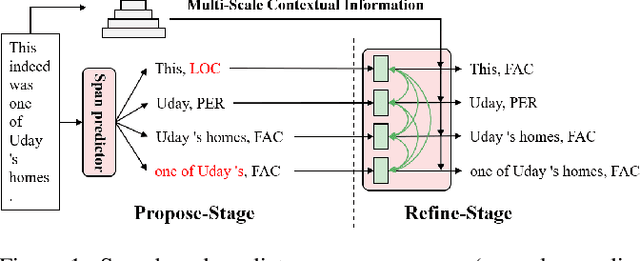
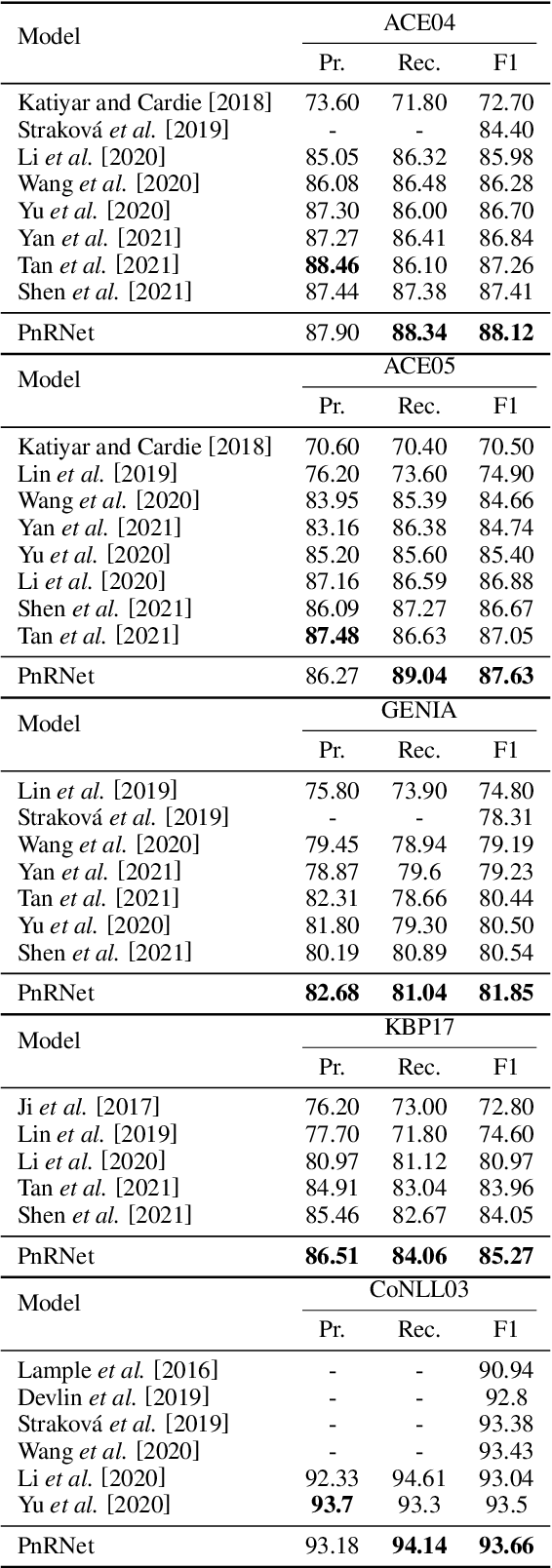
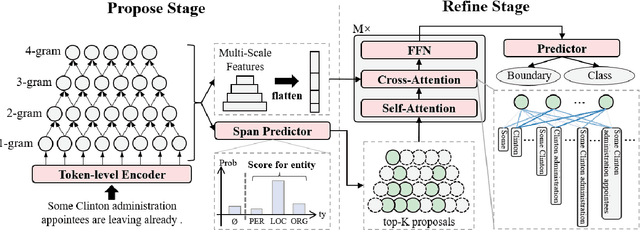

Nested named entity recognition (nested NER) is a fundamental task in natural language processing. Various span-based methods have been proposed to detect nested entities with span representations. However, span-based methods do not consider the relationship between a span and other entities or phrases, which is helpful in the NER task. Besides, span-based methods have trouble predicting long entities due to limited span enumeration length. To mitigate these issues, we present the Propose-and-Refine Network (PnRNet), a two-stage set prediction network for nested NER. In the propose stage, we use a span-based predictor to generate some coarse entity predictions as entity proposals. In the refine stage, proposals interact with each other, and richer contextual information is incorporated into the proposal representations. The refined proposal representations are used to re-predict entity boundaries and classes. In this way, errors in coarse proposals can be eliminated, and the boundary prediction is no longer constrained by the span enumeration length limitation. Additionally, we build multi-scale sentence representations, which better model the hierarchical structure of sentences and provide richer contextual information than token-level representations. Experiments show that PnRNet achieves state-of-the-art performance on four nested NER datasets and one flat NER dataset.