 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMProto: Multi-Prototype Network with Denoised Optimal Transport for Distantly Supervised Named Entity Recognition
Oct 12, 2023Distantly supervised named entity recognition (DS-NER) aims to locate entity mentions and classify their types with only knowledge bases or gazetteers and unlabeled corpus. However, distant annotations are noisy and degrade the performance of NER models. In this paper, we propose a noise-robust prototype network named MProto for the DS-NER task. Different from previous prototype-based NER methods, MProto represents each entity type with multiple prototypes to characterize the intra-class variance among entity representations. To optimize the classifier, each token should be assigned an appropriate ground-truth prototype and we consider such token-prototype assignment as an optimal transport (OT) problem. Furthermore, to mitigate the noise from incomplete labeling, we propose a novel denoised optimal transport (DOT) algorithm. Specifically, we utilize the assignment result between Other class tokens and all prototypes to distinguish unlabeled entity tokens from true negatives. Experiments on several DS-NER benchmarks demonstrate that our MProto achieves state-of-the-art performance. The source code is now available on Github.
Taxonomy Completion with Probabilistic Scorer via Box Embedding
May 19, 2023

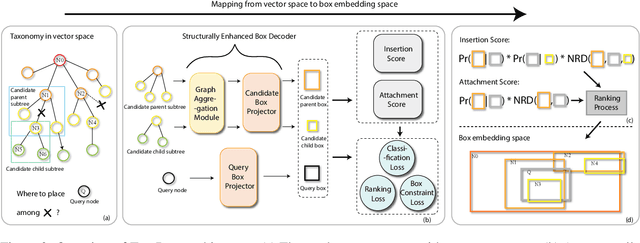
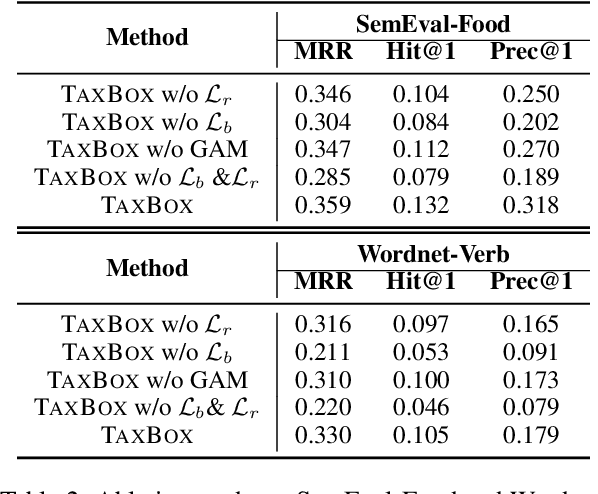
Taxonomy completion, a task aimed at automatically enriching an existing taxonomy with new concepts, has gained significant interest in recent years. Previous works have introduced complex modules, external information, and pseudo-leaves to enrich the representation and unify the matching process of attachment and insertion. While they have achieved good performance, these introductions may have brought noise and unfairness during training and scoring. In this paper, we present TaxBox, a novel framework for taxonomy completion that maps taxonomy concepts to box embeddings and employs two probabilistic scorers for concept attachment and insertion, avoiding the need for pseudo-leaves. Specifically, TaxBox consists of three components: (1) a graph aggregation module to leverage the structural information of the taxonomy and two lightweight decoders that map features to box embedding and capture complex relationships between concepts; (2) two probabilistic scorers that correspond to attachment and insertion operations and ensure the avoidance of pseudo-leaves; and (3) three learning objectives that assist the model in mapping concepts more granularly onto the box embedding space. Experimental results on four real-world datasets suggest that TaxBox outperforms baseline methods by a considerable margin and surpasses previous state-of-art methods to a certain extent.