Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI-Tuning: Tuning Language Models with Image for Caption Generation
Paper and Code
Feb 14, 2022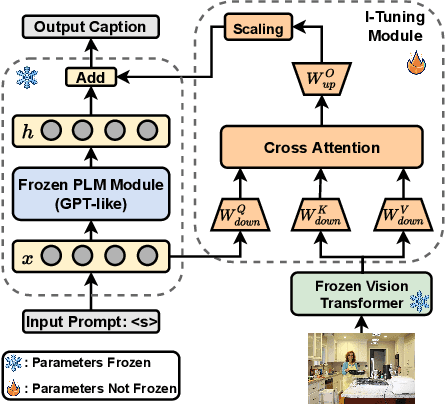
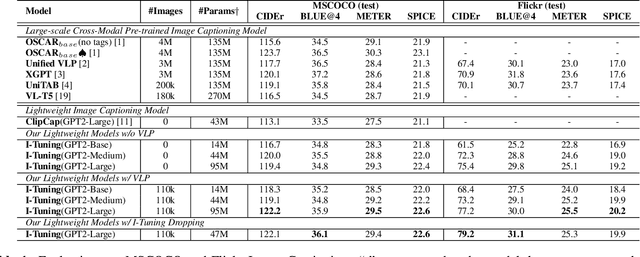
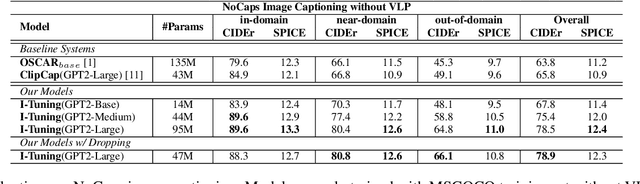

Recently, tuning the pre-trained language model (PLM) in a parameter-efficient manner becomes a popular topic in the natural language processing area. However, most of them focus on tuning the PLM with the text-only information. In this work, we propose a new perspective to tune the frozen PLM with images for caption generation. We denote our method as I-Tuning, which can automatically filter the vision information from images to adjust the output hidden states of PLM. Evaluating on the image captioning tasks (MSCOCO and Flickr30k Captioning), our method achieves comparable or even better performance than the previous models which have 2-4 times more trainable parameters and/or consume a large amount of cross-modal pre-training data.
* Work in progress
View paper on