 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVintern-1B: An Efficient Multimodal Large Language Model for Vietnamese
Aug 22, 2024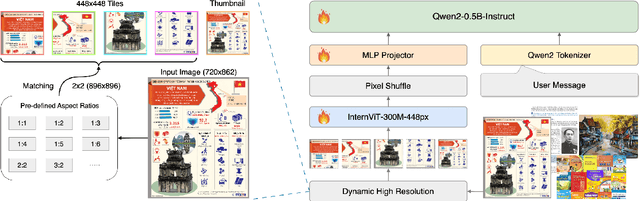



In this report, we introduce Vintern-1B, a reliable 1-billion-parameters multimodal large language model (MLLM) for Vietnamese language tasks. By integrating the Qwen2-0.5B-Instruct language model with the InternViT-300M-448px visual model, Vintern-1B is optimized for a range of applications, including optical character recognition (OCR), document extraction, and general question-answering in Vietnamese context. The model is fine-tuned on an extensive dataset of over 3 million image-question-answer pairs, achieving robust performance and reliable results across multiple Vietnamese language benchmarks like OpenViVQA and ViTextVQA. Vintern-1B is small enough to fit into various on-device applications easily. Additionally, we have open-sourced several Vietnamese vision question answering (VQA) datasets for text and diagrams, created with Gemini 1.5 Flash. Our models are available at: https://huggingface.co/5CD-AI/Vintern-1B-v2.
TabularFM: An Open Framework For Tabular Foundational Models
Jun 18, 2024Foundational models (FMs), pretrained on extensive datasets using self-supervised techniques, are capable of learning generalized patterns from large amounts of data. This reduces the need for extensive labeled datasets for each new task, saving both time and resources by leveraging the broad knowledge base established during pretraining. Most research on FMs has primarily focused on unstructured data, such as text and images, or semi-structured data, like time-series. However, there has been limited attention to structured data, such as tabular data, which, despite its prevalence, remains under-studied due to a lack of clean datasets and insufficient research on the transferability of FMs for various tabular data tasks. In response to this gap, we introduce a framework called TabularFM, which incorporates state-of-the-art methods for developing FMs specifically for tabular data. This includes variations of neural architectures such as GANs, VAEs, and Transformers. We have curated a million of tabular datasets and released cleaned versions to facilitate the development of tabular FMs. We pretrained FMs on this curated data, benchmarked various learning methods on these datasets, and released the pretrained models along with leaderboards for future comparative studies. Our fully open-sourced system provides a comprehensive analysis of the transferability of tabular FMs. By releasing these datasets, pretrained models, and leaderboards, we aim to enhance the validity and usability of tabular FMs in the near future.
An Efficient Model for Sentiment Analysis of Electronic Product Reviews in Vietnamese
Oct 29, 2019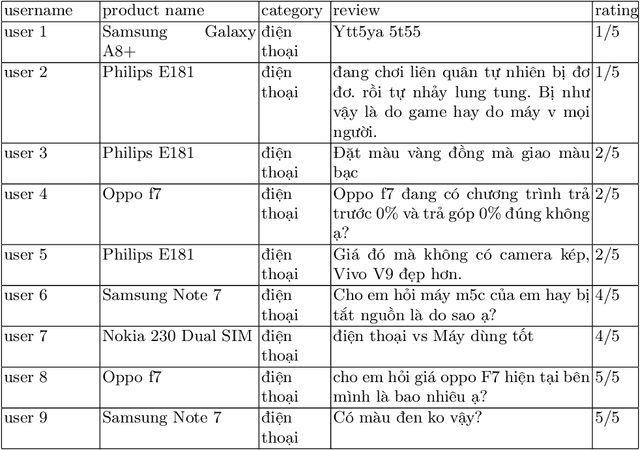
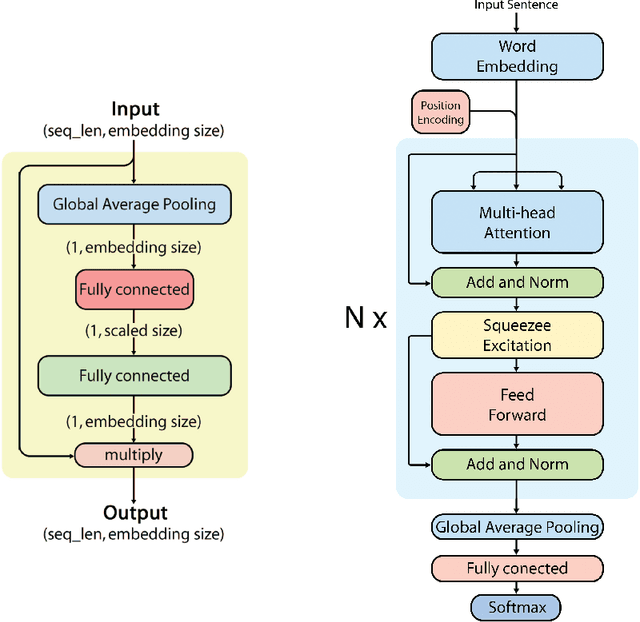
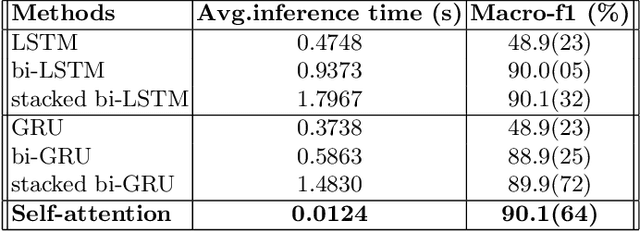
In the past few years, the growth of e-commerce and digital marketing in Vietnam has generated a huge volume of opinionated data. Analyzing those data would provide enterprises with insight for better business decisions. In this work, as part of the Advosights project, we study sentiment analysis of product reviews in Vietnamese. The final solution is based on Self-attention neural networks, a flexible architecture for text classification task with about 90.16% of accuracy in 0.0124 second, a very fast inference time.