 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVintern-1B: An Efficient Multimodal Large Language Model for Vietnamese
Aug 22, 2024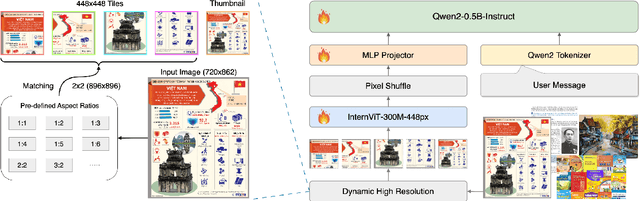



In this report, we introduce Vintern-1B, a reliable 1-billion-parameters multimodal large language model (MLLM) for Vietnamese language tasks. By integrating the Qwen2-0.5B-Instruct language model with the InternViT-300M-448px visual model, Vintern-1B is optimized for a range of applications, including optical character recognition (OCR), document extraction, and general question-answering in Vietnamese context. The model is fine-tuned on an extensive dataset of over 3 million image-question-answer pairs, achieving robust performance and reliable results across multiple Vietnamese language benchmarks like OpenViVQA and ViTextVQA. Vintern-1B is small enough to fit into various on-device applications easily. Additionally, we have open-sourced several Vietnamese vision question answering (VQA) datasets for text and diagrams, created with Gemini 1.5 Flash. Our models are available at: https://huggingface.co/5CD-AI/Vintern-1B-v2.