 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAC$^2$E: Better Understanding Large Language Model Capabilities by Dissociating Language and Cognition
Paper and Code
Feb 29, 2024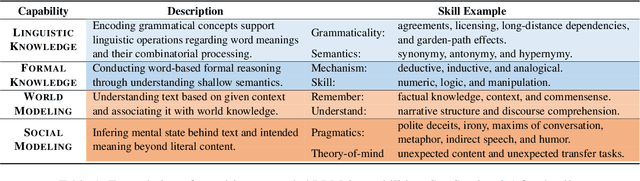

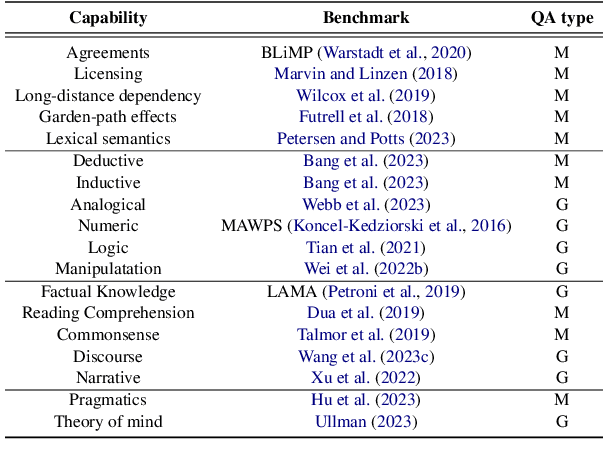
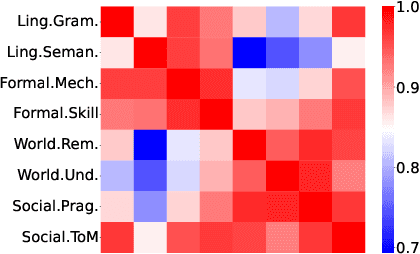
Large language models (LLMs) are primarily evaluated by overall performance on various text understanding and generation tasks. However, such a paradigm fails to comprehensively differentiate the fine-grained language and cognitive skills, rendering the lack of sufficient interpretation to LLMs' capabilities. In this paper, we present FAC$^2$E, a framework for Fine-grAined and Cognition-grounded LLMs' Capability Evaluation. Specifically, we formulate LLMs' evaluation in a multi-dimensional and explainable manner by dissociating the language-related capabilities and the cognition-related ones. Besides, through extracting the intermediate reasoning from LLMs, we further break down the process of applying a specific capability into three sub-steps: recalling relevant knowledge, utilizing knowledge, and solving problems. Finally, FAC$^2$E evaluates each sub-step of each fine-grained capability, providing a two-faceted diagnosis for LLMs. Utilizing FAC$^2$E, we identify a common shortfall in knowledge utilization among models and propose a straightforward, knowledge-enhanced method to mitigate this issue. Our results not only showcase promising performance enhancements but also highlight a direction for future LLM advancements.