 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOP: A Scalable Online Post-Training System for Vision-Language-Action Models
Jan 06, 2026Vision-language-action (VLA) models achieve strong generalization through large-scale pre-training, but real-world deployment requires expert-level task proficiency in addition to broad generality. Existing post-training approaches for VLA models are typically offline, single-robot, or task-specific, limiting effective on-policy adaptation and scalable learning from real-world interaction. We introduce a Scalable Online Post-training (SOP) system that enables online, distributed, multi-task post-training of generalist VLA models directly in the physical world. SOP tightly couples execution and learning through a closed-loop architecture in which a fleet of robots continuously streams on-policy experience and human intervention signals to a centralized cloud learner, and asynchronously receives updated policies. This design supports prompt on-policy correction, scales experience collection through parallel deployment, and preserves generality during adaptation. SOP is agnostic to the choice of post-training algorithm; we instantiate it with both interactive imitation learning (HG-DAgger) and reinforcement learning (RECAP). Across a range of real-world manipulation tasks including cloth folding, box assembly, and grocery restocking, we show that SOP substantially improves the performance of large pretrained VLA models while maintaining a single shared policy across tasks. Effective post-training can be achieved within hours of real-world interaction, and performance scales near-linearly with the number of robots in the fleet. These results suggest that tightly coupling online learning with fleet-scale deployment is instrumental to enabling efficient, reliable, and scalable post-training of generalist robot policies in the physical world.
IDEAL: Data Equilibrium Adaptation for Multi-Capability Language Model Alignment
May 19, 2025



Large Language Models (LLMs) have achieved impressive performance through Supervised Fine-tuning (SFT) on diverse instructional datasets. When training on multiple capabilities simultaneously, the mixture training dataset, governed by volumes of data from different domains, is a critical factor that directly impacts the final model's performance. Unlike many studies that focus on enhancing the quality of training datasets through data selection methods, few works explore the intricate relationship between the compositional quantity of mixture training datasets and the emergent capabilities of LLMs. Given the availability of a high-quality multi-domain training dataset, understanding the impact of data from each domain on the model's overall capabilities is crucial for preparing SFT data and training a well-balanced model that performs effectively across diverse domains. In this work, we introduce IDEAL, an innovative data equilibrium adaptation framework designed to effectively optimize volumes of data from different domains within mixture SFT datasets, thereby enhancing the model's alignment and performance across multiple capabilities. IDEAL employs a gradient-based approach to iteratively refine the training data distribution, dynamically adjusting the volumes of domain-specific data based on their impact on downstream task performance. By leveraging this adaptive mechanism, IDEAL ensures a balanced dataset composition, enabling the model to achieve robust generalization and consistent proficiency across diverse tasks. Experiments across different capabilities demonstrate that IDEAL outperforms conventional uniform data allocation strategies, achieving a comprehensive improvement of approximately 7% in multi-task evaluation scores.
Inverse Reinforcement Learning with Unknown Reward Model based on Structural Risk Minimization
Dec 27, 2023Inverse reinforcement learning (IRL) usually assumes the model of the reward function is pre-specified and estimates the parameter only. However, how to determine a proper reward model is nontrivial. A simplistic model is less likely to contain the real reward function, while a model with high complexity leads to substantial computation cost and risks overfitting. This paper addresses this trade-off in IRL model selection by introducing the structural risk minimization (SRM) method from statistical learning. SRM selects an optimal reward function class from a hypothesis set minimizing both estimation error and model complexity. To formulate an SRM scheme for IRL, we estimate policy gradient by demonstration serving as empirical risk and establish the upper bound of Rademacher complexity of hypothesis classes as model penalty. The learning guarantee is further presented. In particular, we provide explicit SRM for the common linear weighted sum setting in IRL. Simulations demonstrate the performance and efficiency of our scheme.
Control Input Inference of Mobile Agents under Unknown Objective
Jul 20, 2023Trajectory and control secrecy is an important issue in robotics security. This paper proposes a novel algorithm for the control input inference of a mobile agent without knowing its control objective. Specifically, the algorithm first estimates the target state by applying external perturbations. Then we identify the objective function based on the inverse optimal control, providing the well-posedness proof and the identifiability analysis. Next, we obtain the optimal estimate of the control horizon using binary search. Finally, the agent's control optimization problem is reconstructed and solved to predict its input. Simulation illustrates the efficiency and the performance of the algorithm.
Moving Target Interception Considering Dynamic Environment
May 16, 2022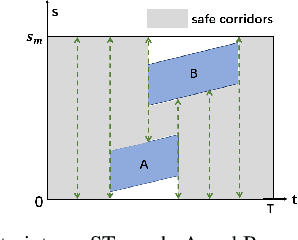

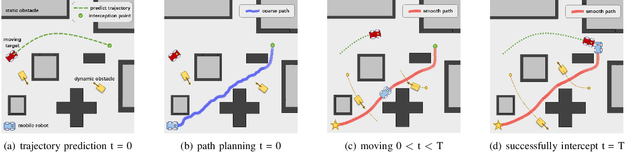
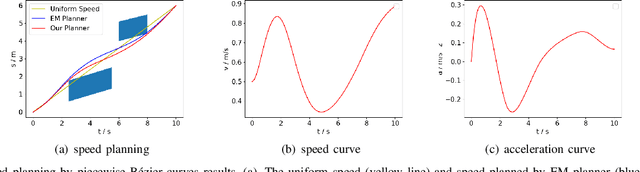
The interception of moving targets is a widely studied issue. In this paper, we propose an algorithm of intercepting the moving target with a wheeled mobile robot in a dynamic environment. We first predict the future position of the target through polynomial fitting. The algorithm then generates an interception trajectory with path and speed decoupling. We use Hybrid A* search to plan a path and optimize it via gradient decent method. To avoid the dynamic obstacles in the environment, we introduce ST graph for speed planning. The speed curve is represented by piecewise B\'ezier curves for further optimization. Compared with other interception algorithms, we consider a dynamic environment and plan a safety trajectory which satisfies the kinematic characteristics of the wheeled robot while ensuring the accuracy of interception. Simulation illustrates that the algorithm successfully achieves the interception tasks and has high computational efficiency.