 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint-Embedding Masked Autoencoder for Self-supervised Learning of Dynamic Functional Connectivity from the Human Brain
Paper and Code
Mar 11, 2024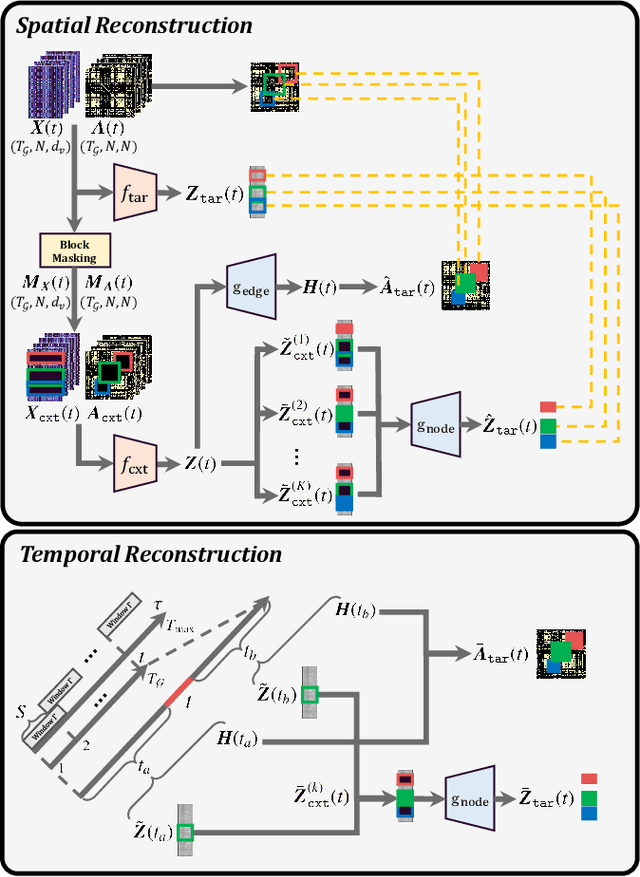
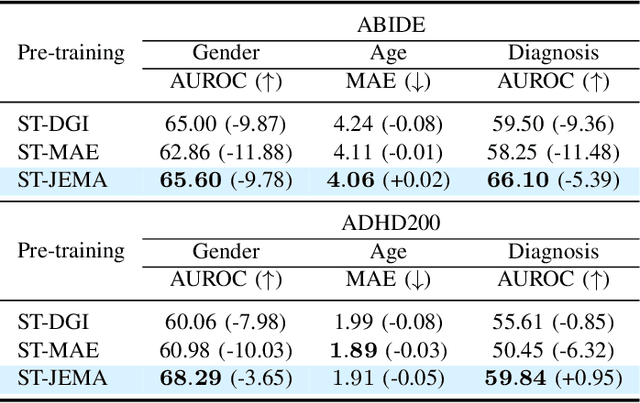
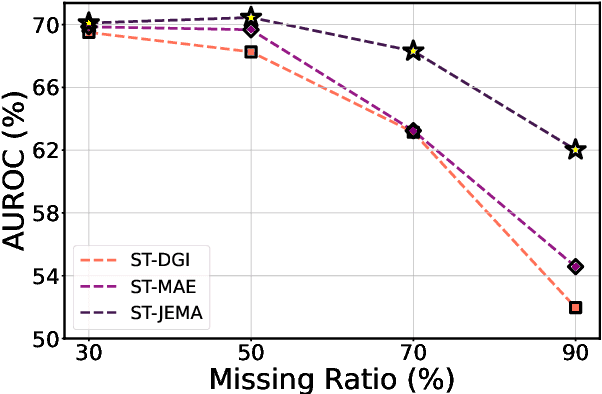
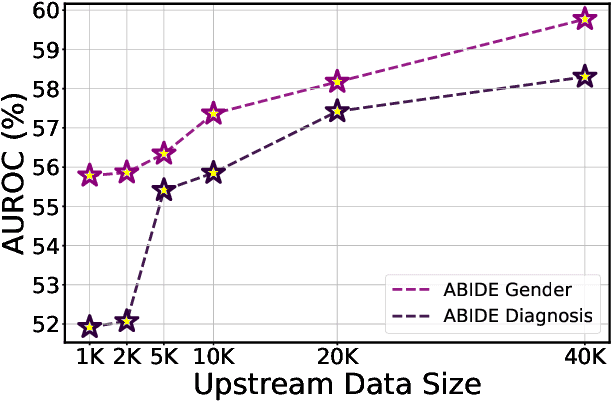
Graph Neural Networks (GNNs) have shown promise in learning dynamic functional connectivity for distinguishing phenotypes from human brain networks. However, obtaining extensive labeled clinical data for training is often resource-intensive, making practical application difficult. Leveraging unlabeled data thus becomes crucial for representation learning in a label-scarce setting. Although generative self-supervised learning techniques, especially masked autoencoders, have shown promising results in representation learning in various domains, their application to dynamic graphs for dynamic functional connectivity remains underexplored, facing challenges in capturing high-level semantic representations. Here, we introduce the Spatio-Temporal Joint Embedding Masked Autoencoder (ST-JEMA), drawing inspiration from the Joint Embedding Predictive Architecture (JEPA) in computer vision. ST-JEMA employs a JEPA-inspired strategy for reconstructing dynamic graphs, which enables the learning of higher-level semantic representations considering temporal perspectives, addressing the challenges in fMRI data representation learning. Utilizing the large-scale UK Biobank dataset for self-supervised learning, ST-JEMA shows exceptional representation learning performance on dynamic functional connectivity demonstrating superiority over previous methods in predicting phenotypes and psychiatric diagnoses across eight benchmark fMRI datasets even with limited samples and effectiveness of temporal reconstruction on missing data scenarios. These findings highlight the potential of our approach as a robust representation learning method for leveraging label-scarce fMRI data.