 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Segment Liquids in Real-world Images
Jan 02, 2026Different types of liquids such as water, wine and medicine appear in all aspects of daily life. However, limited attention has been given to the task, hindering the ability of robots to avoid or interact with liquids safely. The segmentation of liquids is difficult because liquids come in diverse appearances and shapes; moreover, they can be both transparent or reflective, taking on arbitrary objects and scenes from the background or surroundings. To take on this challenge, we construct a large-scale dataset of liquids named LQDS consisting of 5000 real-world images annotated into 14 distinct classes, and design a novel liquid detection model named LQDM, which leverages cross-attention between a dedicated boundary branch and the main segmentation branch to enhance segmentation predictions. Extensive experiments demonstrate the effectiveness of LQDM on the test set of LQDS, outperforming state-of-the-art methods and establishing a strong baseline for the semantic segmentation of liquids.
LaMOT: Language-Guided Multi-Object Tracking
Jun 12, 2024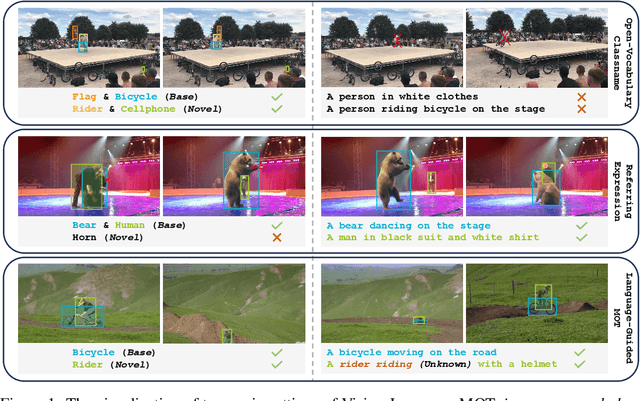
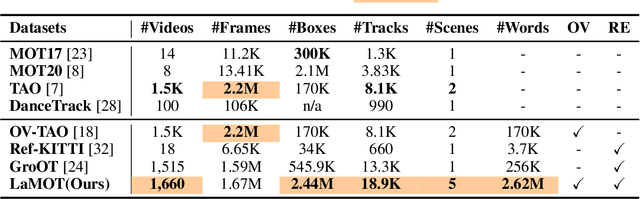
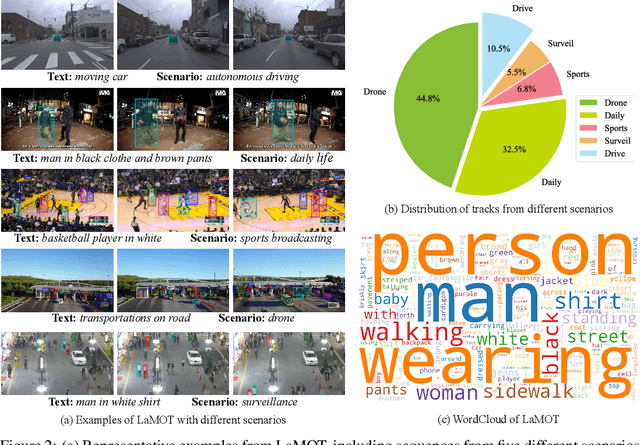
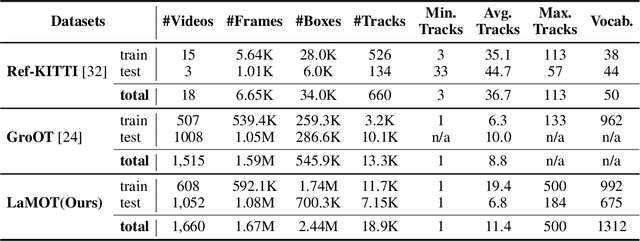
Vision-Language MOT is a crucial tracking problem and has drawn increasing attention recently. It aims to track objects based on human language commands, replacing the traditional use of templates or pre-set information from training sets in conventional tracking tasks. Despite various efforts, a key challenge lies in the lack of a clear understanding of why language is used for tracking, which hinders further development in this field. In this paper, we address this challenge by introducing Language-Guided MOT, a unified task framework, along with a corresponding large-scale benchmark, termed LaMOT, which encompasses diverse scenarios and language descriptions. Specially, LaMOT comprises 1,660 sequences from 4 different datasets and aims to unify various Vision-Language MOT tasks while providing a standardized evaluation platform. To ensure high-quality annotations, we manually assign appropriate descriptive texts to each target in every video and conduct careful inspection and correction. To the best of our knowledge, LaMOT is the first benchmark dedicated to Language-Guided MOT. Additionally, we propose a simple yet effective tracker, termed LaMOTer. By establishing a unified task framework, providing challenging benchmarks, and offering insights for future algorithm design and evaluation, we expect to contribute to the advancement of research in Vision-Language MOT. We will release the data at https://github.com/Nathan-Li123/LaMOT.
Compositional Program Generation for Systematic Generalization
Sep 28, 2023
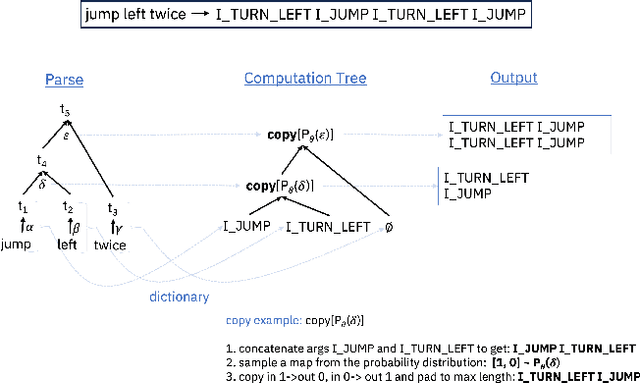
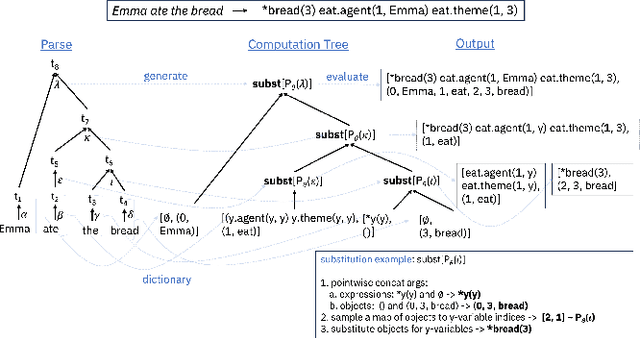

Compositional generalization is a key ability of humans that enables us to learn new concepts from only a handful examples. Machine learning models, including the now ubiquitous transformers, struggle to generalize in this way, and typically require thousands of examples of a concept during training in order to generalize meaningfully. This difference in ability between humans and artificial neural architectures, motivates this study on a neuro-symbolic architecture called the Compositional Program Generator (CPG). CPG has three key features: modularity, type abstraction, and recursive composition, that enable it to generalize both systematically to new concepts in a few-shot manner, as well as productively by length on various sequence-to-sequence language tasks. For each input, CPG uses a grammar of the input domain and a parser to generate a type hierarchy in which each grammar rule is assigned its own unique semantic module, a probabilistic copy or substitution program. Instances with the same hierarchy are processed with the same composed program, while those with different hierarchies may be processed with different programs. CPG learns parameters for the semantic modules and is able to learn the semantics for new types incrementally. Given a context-free grammar of the input language and a dictionary mapping each word in the source language to its interpretation in the output language, CPG can achieve perfect generalization on the SCAN and COGS benchmarks, in both standard and extreme few-shot settings.