 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaMOT: Language-Guided Multi-Object Tracking
Paper and Code
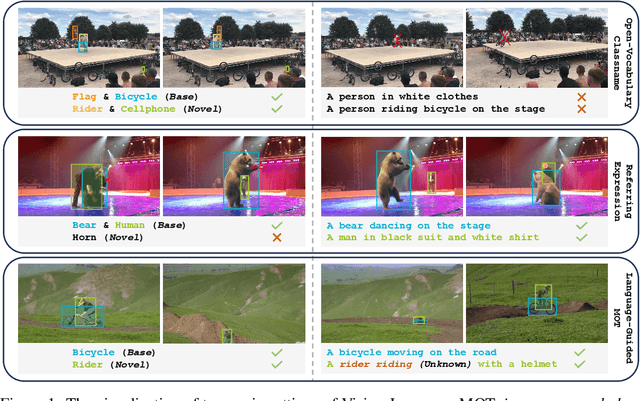
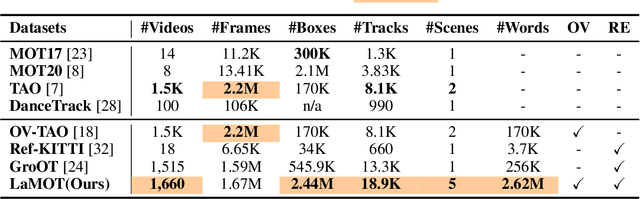
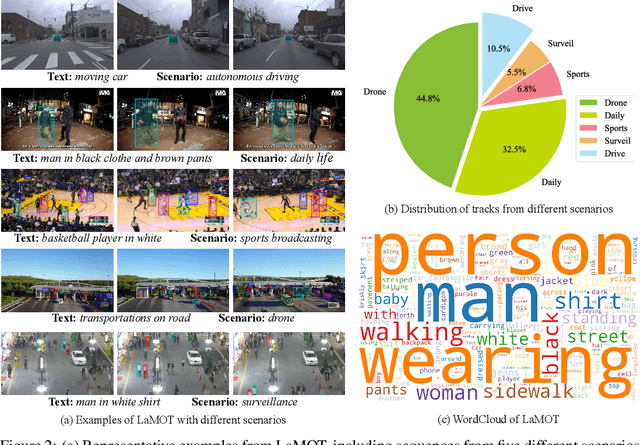
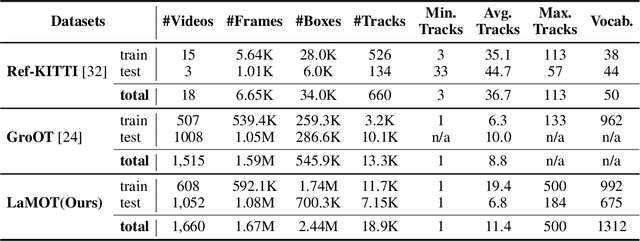
Vision-Language MOT is a crucial tracking problem and has drawn increasing attention recently. It aims to track objects based on human language commands, replacing the traditional use of templates or pre-set information from training sets in conventional tracking tasks. Despite various efforts, a key challenge lies in the lack of a clear understanding of why language is used for tracking, which hinders further development in this field. In this paper, we address this challenge by introducing Language-Guided MOT, a unified task framework, along with a corresponding large-scale benchmark, termed LaMOT, which encompasses diverse scenarios and language descriptions. Specially, LaMOT comprises 1,660 sequences from 4 different datasets and aims to unify various Vision-Language MOT tasks while providing a standardized evaluation platform. To ensure high-quality annotations, we manually assign appropriate descriptive texts to each target in every video and conduct careful inspection and correction. To the best of our knowledge, LaMOT is the first benchmark dedicated to Language-Guided MOT. Additionally, we propose a simple yet effective tracker, termed LaMOTer. By establishing a unified task framework, providing challenging benchmarks, and offering insights for future algorithm design and evaluation, we expect to contribute to the advancement of research in Vision-Language MOT. We will release the data at https://github.com/Nathan-Li123/LaMOT.