 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoalNet: Inferring Conjunctive Goal Predicates from Human Plan Demonstrations for Robot Instruction Following
May 14, 2022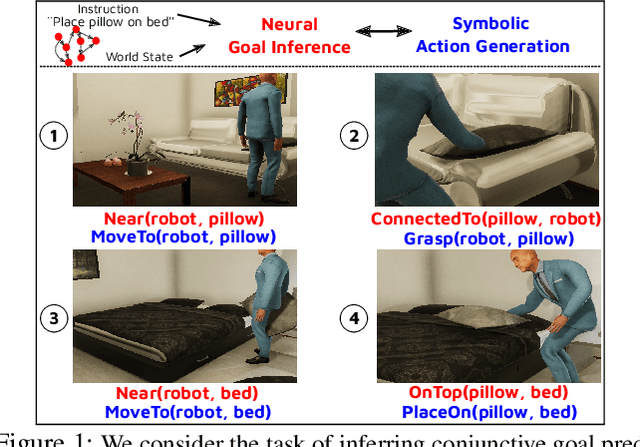

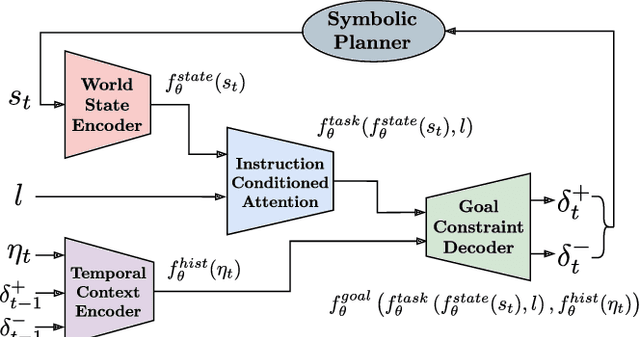
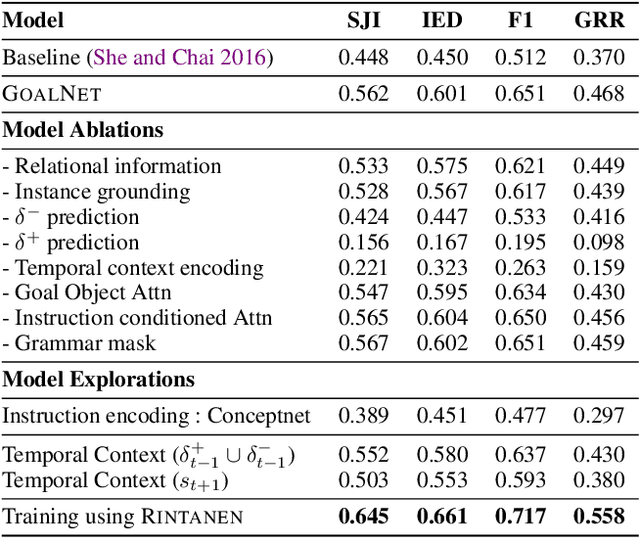
Our goal is to enable a robot to learn how to sequence its actions to perform tasks specified as natural language instructions, given successful demonstrations from a human partner. The ability to plan high-level tasks can be factored as (i) inferring specific goal predicates that characterize the task implied by a language instruction for a given world state and (ii) synthesizing a feasible goal-reaching action-sequence with such predicates. For the former, we leverage a neural network prediction model, while utilizing a symbolic planner for the latter. We introduce a novel neuro-symbolic model, GoalNet, for contextual and task dependent inference of goal predicates from human demonstrations and linguistic task descriptions. GoalNet combines (i) learning, where dense representations are acquired for language instruction and the world state that enables generalization to novel settings and (ii) planning, where the cause-effect modeling by the symbolic planner eschews irrelevant predicates facilitating multi-stage decision making in large domains. GoalNet demonstrates a significant improvement (51%) in the task completion rate in comparison to a state-of-the-art rule-based approach on a benchmark data set displaying linguistic variations, particularly for multi-stage instructions.
A Variational Information Bottleneck Based Method to Compress Sequential Networks for Human Action Recognition
Oct 03, 2020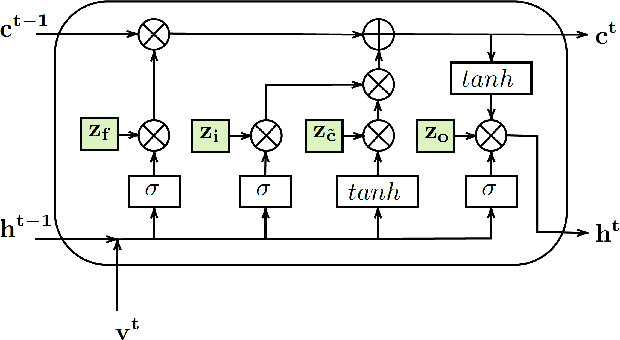
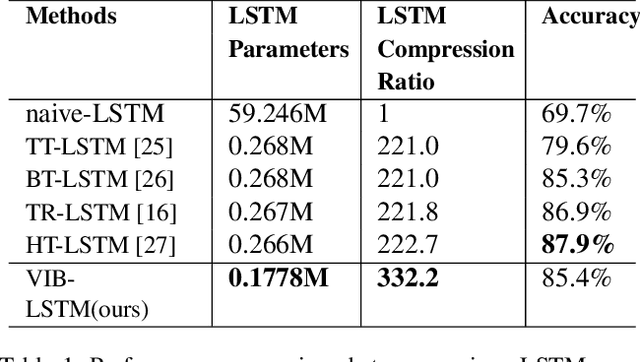

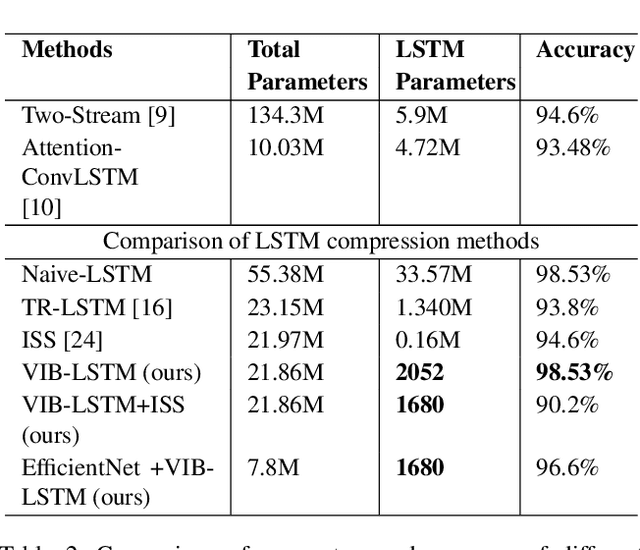
In the last few years, compression of deep neural networks has become an important strand of machine learning and computer vision research. Deep models require sizeable computational complexity and storage, when used for instance for Human Action Recognition (HAR) from videos, making them unsuitable to be deployed on edge devices. In this paper, we address this issue and propose a method to effectively compress Recurrent Neural Networks (RNNs) such as Gated Recurrent Units (GRUs) and Long-Short-Term-Memory Units (LSTMs) that are used for HAR. We use a Variational Information Bottleneck (VIB) theory-based pruning approach to limit the information flow through the sequential cells of RNNs to a small subset. Further, we combine our pruning method with a specific group-lasso regularization technique that significantly improves compression. The proposed techniques reduce model parameters and memory footprint from latent representations, with little or no reduction in the validation accuracy while increasing the inference speed several-fold. We perform experiments on the three widely used Action Recognition datasets, viz. UCF11, HMDB51, and UCF101, to validate our approach. It is shown that our method achieves over 70 times greater compression than the nearest competitor with comparable accuracy for the task of action recognition on UCF11.