 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToolTango: Common sense Generalization in Predicting Sequential Tool Interactions for Robot Plan Synthesis
Jun 18, 2022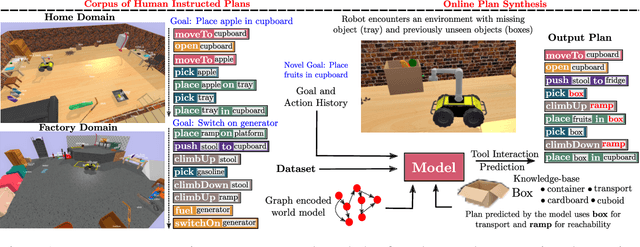
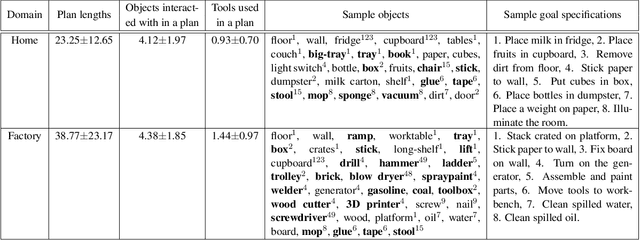
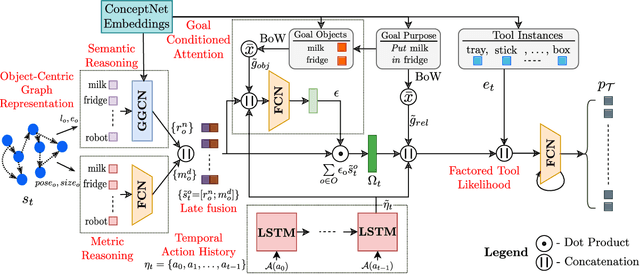

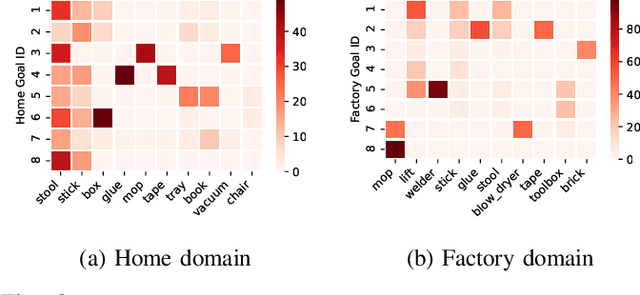
Robots assisting us in environments such as factories or homes must learn to make use of objects as tools to perform tasks, for instance using a tray to carry objects. We consider the problem of learning commonsense knowledge of when a tool may be useful and how its use may be composed with other tools to accomplish a high-level task instructed by a human. Specifically, we introduce a novel neural model, termed TOOLTANGO, that first predicts the next tool to be used, and then uses this information to predict the next action. We show that this joint model can inform learning of a fine-grained policy enabling the robot to use a particular tool in sequence and adds a significant value in making the model more accurate. TOOLTANGO encodes the world state, comprising objects and symbolic relationships between them, using a graph neural network and is trained using demonstrations from human teachers instructing a virtual robot in a physics simulator. The model learns to attend over the scene using knowledge of the goal and the action history, finally decoding the symbolic action to execute. Crucially, we address generalization to unseen environments where some known tools are missing, but alternative unseen tools are present. We show that by augmenting the representation of the environment with pre-trained embeddings derived from a knowledge-base, the model can generalize effectively to novel environments. Experimental results show at least 48.8-58.1% absolute improvement over the baselines in predicting successful symbolic plans for a simulated mobile manipulator in novel environments with unseen objects. This work takes a step in the direction of enabling robots to rapidly synthesize robust plans for complex tasks, particularly in novel settings
Learning Backward Compatible Embeddings
Jun 07, 2022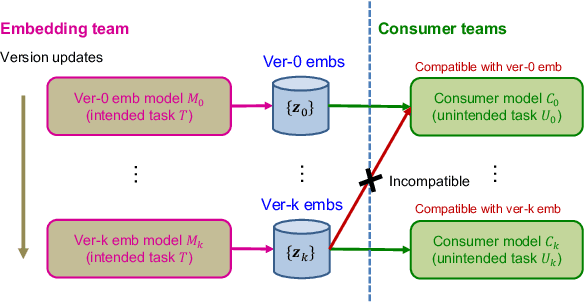
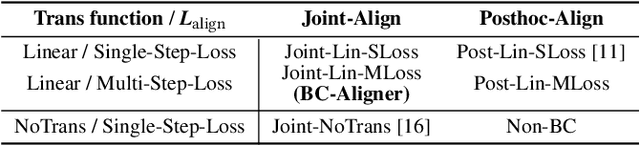
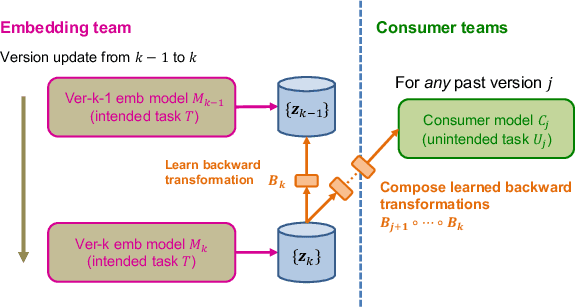

Embeddings, low-dimensional vector representation of objects, are fundamental in building modern machine learning systems. In industrial settings, there is usually an embedding team that trains an embedding model to solve intended tasks (e.g., product recommendation). The produced embeddings are then widely consumed by consumer teams to solve their unintended tasks (e.g., fraud detection). However, as the embedding model gets updated and retrained to improve performance on the intended task, the newly-generated embeddings are no longer compatible with the existing consumer models. This means that historical versions of the embeddings can never be retired or all consumer teams have to retrain their models to make them compatible with the latest version of the embeddings, both of which are extremely costly in practice. Here we study the problem of embedding version updates and their backward compatibility. We formalize the problem where the goal is for the embedding team to keep updating the embedding version, while the consumer teams do not have to retrain their models. We develop a solution based on learning backward compatible embeddings, which allows the embedding model version to be updated frequently, while also allowing the latest version of the embedding to be quickly transformed into any backward compatible historical version of it, so that consumer teams do not have to retrain their models. Under our framework, we explore six methods and systematically evaluate them on a real-world recommender system application. We show that the best method, which we call BC-Aligner, maintains backward compatibility with existing unintended tasks even after multiple model version updates. Simultaneously, BC-Aligner achieves the intended task performance similar to the embedding model that is solely optimized for the intended task.
TANGO: Commonsense Generalization in Predicting Tool Interactions for Mobile Manipulators
May 23, 2021
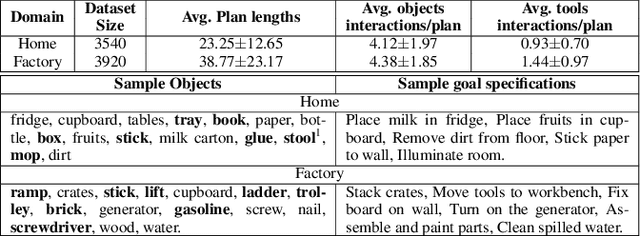
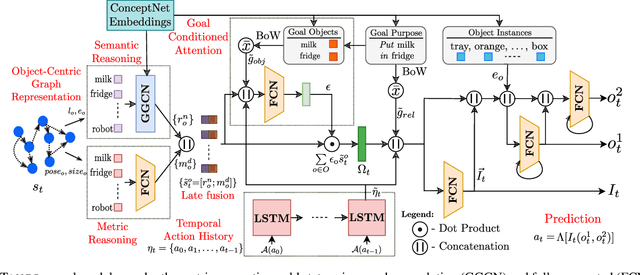
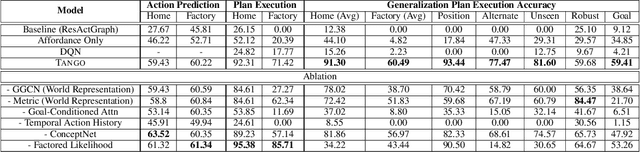
Robots assisting us in factories or homes must learn to make use of objects as tools to perform tasks, e.g., a tray for carrying objects. We consider the problem of learning commonsense knowledge of when a tool may be useful and how its use may be composed with other tools to accomplish a high-level task instructed by a human. We introduce a novel neural model, termed TANGO, for predicting task-specific tool interactions, trained using demonstrations from human teachers instructing a virtual robot. TANGO encodes the world state, comprising objects and symbolic relationships between them, using a graph neural network. The model learns to attend over the scene using knowledge of the goal and the action history, finally decoding the symbolic action to execute. Crucially, we address generalization to unseen environments where some known tools are missing, but alternative unseen tools are present. We show that by augmenting the representation of the environment with pre-trained embeddings derived from a knowledge-base, the model can generalize effectively to novel environments. Experimental results show a 60.5-78.9% absolute improvement over the baseline in predicting successful symbolic plans in unseen settings for a simulated mobile manipulator.
ToolNet: Using Commonsense Generalization for Predicting Tool Use for Robot Plan Synthesis
Jun 18, 2020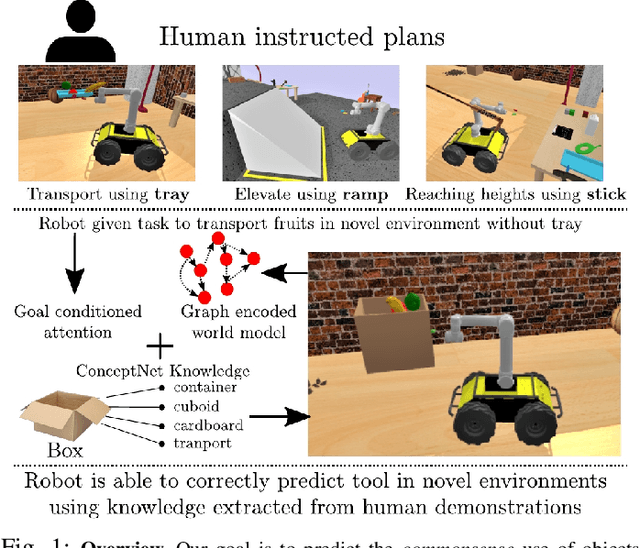

A robot working in a physical environment (like home or factory) needs to learn to use various available tools for accomplishing different tasks, for instance, a mop for cleaning and a tray for carrying objects. The number of possible tools is large and it may not be feasible to demonstrate usage of each individual tool during training. Can a robot learn commonsense knowledge and adapt to novel settings where some known tools are missing, but alternative unseen tools are present? We present a neural model that predicts the best tool from the available objects for achieving a given declarative goal. This model is trained by user demonstrations, which we crowd-source through humans instructing a robot in a physics simulator. This dataset maintains user plans involving multi-step object interactions along with symbolic state changes. Our neural model, ToolNet, combines a graph neural network to encode the current environment state, and goal-conditioned spatial attention to predict the appropriate tool. We find that providing metric and semantic properties of objects, and pre-trained object embeddings derived from a commonsense knowledge repository such as ConceptNet, significantly improves the model's ability to generalize to unseen tools. The model makes accurate and generalizable tool predictions. When compared to a graph neural network baseline, it achieves 14-27% accuracy improvement for predicting known tools from new world scenes, and 44-67% improvement in generalization for novel objects not encountered during training.