 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Lower Bounds for Simple Policy Iteration
Paper and Code
Nov 28, 2019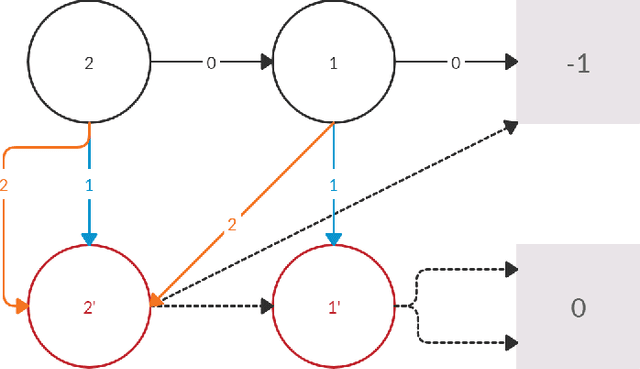
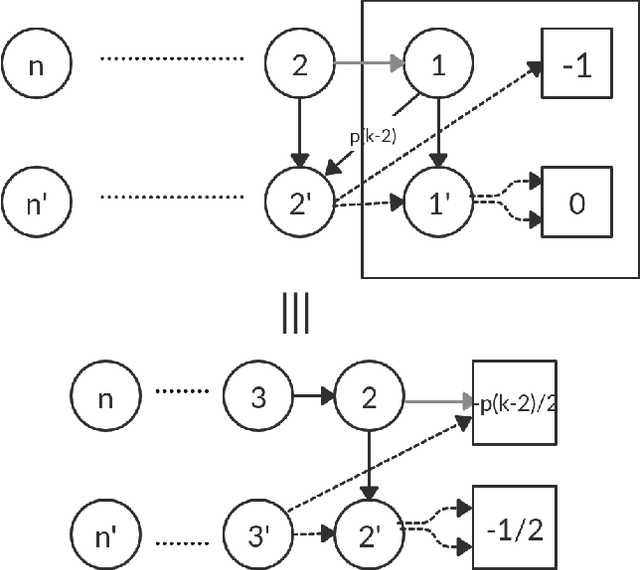
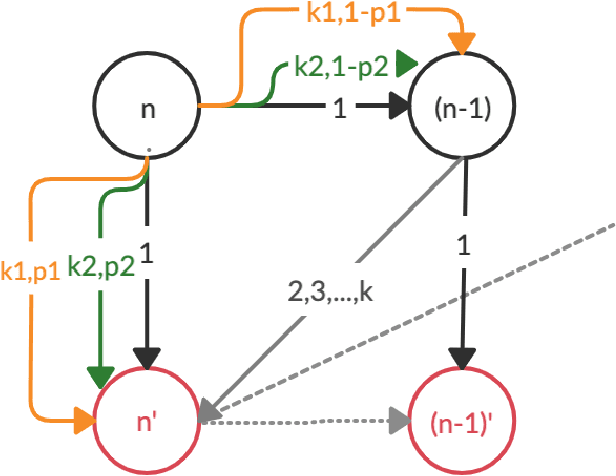
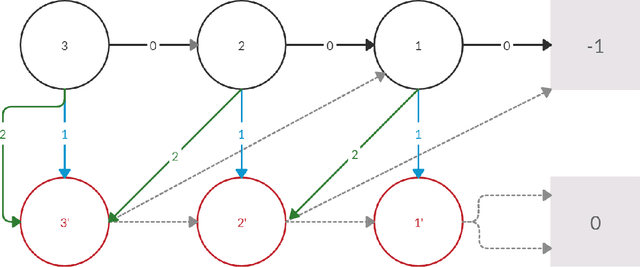
Policy iteration is a family of algorithms that are used to find an optimal policy for a given Markov Decision Problem (MDP). Simple Policy iteration (SPI) is a type of policy iteration where the strategy is to change the policy at exactly one improvable state at every step. Melekopoglou and Condon [1990] showed an exponential lower bound on the number of iterations taken by SPI for a 2 action MDP. The results have not been generalized to $k-$action MDP since. In this paper, we revisit the algorithm and the analysis done by Melekopoglou and Condon. We generalize the previous result and prove a novel exponential lower bound on the number of iterations taken by policy iteration for $N-$state, $k-$action MDPs. We construct a family of MDPs and give an index-based switching rule that yields a strong lower bound of $\mathcal{O}\big((3+k)2^{N/2-3}\big)$.