 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMETRIK: Measurement-Efficient Randomized Controlled Trials using Transformers with Input Masking
Paper and Code
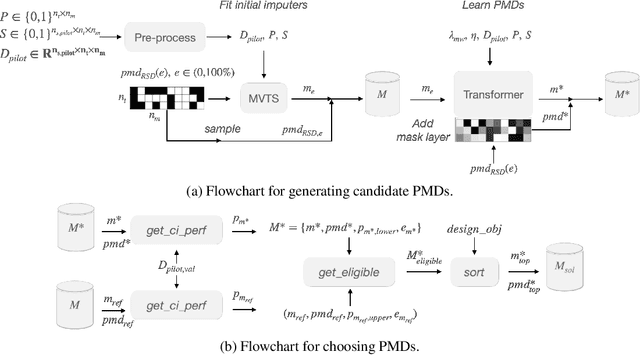

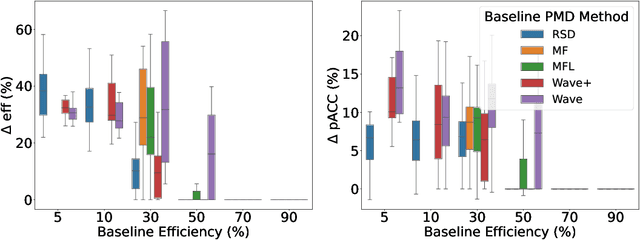
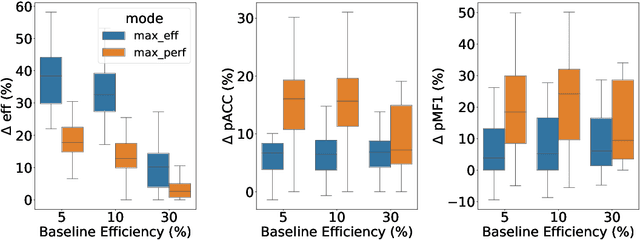
Clinical randomized controlled trials (RCTs) collect hundreds of measurements spanning various metric types (e.g., laboratory tests, cognitive/motor assessments, etc.) across 100s-1000s of subjects to evaluate the effect of a treatment, but do so at the cost of significant trial expense. To reduce the number of measurements, trial protocols can be revised to remove metrics extraneous to the study's objective, but doing so requires additional human labor and limits the set of hypotheses that can be studied with the collected data. In contrast, a planned missing design (PMD) can reduce the amount of data collected without removing any metric by imputing the unsampled data. Standard PMDs randomly sample data to leverage statistical properties of imputation algorithms, but are ad hoc, hence suboptimal. Methods that learn PMDs produce more sample-efficient PMDs, but are not suitable for RCTs because they require ample prior data (150+ subjects) to model the data distribution. Therefore, we introduce a framework called Measurement EfficienT Randomized Controlled Trials using Transformers with Input MasKing (METRIK), which, for the first time, calculates a PMD specific to the RCT from a modest amount of prior data (e.g., 60 subjects). Specifically, METRIK models the PMD as a learnable input masking layer that is optimized with a state-of-the-art imputer based on the Transformer architecture. METRIK implements a novel sampling and selection algorithm to generate a PMD that satisfies the trial designer's objective, i.e., whether to maximize sampling efficiency or imputation performance for a given sampling budget. Evaluated across five real-world clinical RCT datasets, METRIK increases the sampling efficiency of and imputation performance under the generated PMD by leveraging correlations over time and across metrics, thereby removing the need to manually remove metrics from the RCT.