 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the relative composition of EEG signals using pairwise relative shift pretraining
Nov 14, 2025Self-supervised learning (SSL) offers a promising approach for learning electroencephalography (EEG) representations from unlabeled data, reducing the need for expensive annotations for clinical applications like sleep staging and seizure detection. While current EEG SSL methods predominantly use masked reconstruction strategies like masked autoencoders (MAE) that capture local temporal patterns, position prediction pretraining remains underexplored despite its potential to learn long-range dependencies in neural signals. We introduce PAirwise Relative Shift or PARS pretraining, a novel pretext task that predicts relative temporal shifts between randomly sampled EEG window pairs. Unlike reconstruction-based methods that focus on local pattern recovery, PARS encourages encoders to capture relative temporal composition and long-range dependencies inherent in neural signals. Through comprehensive evaluation on various EEG decoding tasks, we demonstrate that PARS-pretrained transformers consistently outperform existing pretraining strategies in label-efficient and transfer learning settings, establishing a new paradigm for self-supervised EEG representation learning.
METRIK: Measurement-Efficient Randomized Controlled Trials using Transformers with Input Masking
Jun 24, 2024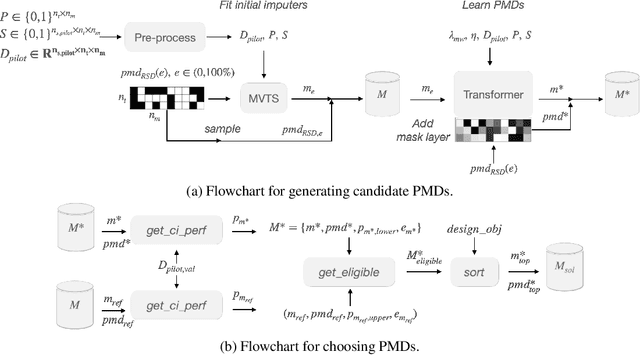

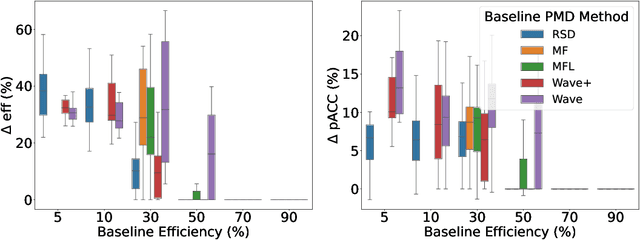
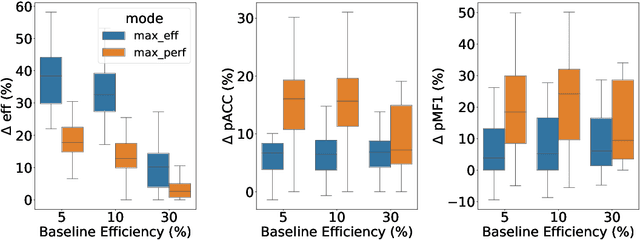
Clinical randomized controlled trials (RCTs) collect hundreds of measurements spanning various metric types (e.g., laboratory tests, cognitive/motor assessments, etc.) across 100s-1000s of subjects to evaluate the effect of a treatment, but do so at the cost of significant trial expense. To reduce the number of measurements, trial protocols can be revised to remove metrics extraneous to the study's objective, but doing so requires additional human labor and limits the set of hypotheses that can be studied with the collected data. In contrast, a planned missing design (PMD) can reduce the amount of data collected without removing any metric by imputing the unsampled data. Standard PMDs randomly sample data to leverage statistical properties of imputation algorithms, but are ad hoc, hence suboptimal. Methods that learn PMDs produce more sample-efficient PMDs, but are not suitable for RCTs because they require ample prior data (150+ subjects) to model the data distribution. Therefore, we introduce a framework called Measurement EfficienT Randomized Controlled Trials using Transformers with Input MasKing (METRIK), which, for the first time, calculates a PMD specific to the RCT from a modest amount of prior data (e.g., 60 subjects). Specifically, METRIK models the PMD as a learnable input masking layer that is optimized with a state-of-the-art imputer based on the Transformer architecture. METRIK implements a novel sampling and selection algorithm to generate a PMD that satisfies the trial designer's objective, i.e., whether to maximize sampling efficiency or imputation performance for a given sampling budget. Evaluated across five real-world clinical RCT datasets, METRIK increases the sampling efficiency of and imputation performance under the generated PMD by leveraging correlations over time and across metrics, thereby removing the need to manually remove metrics from the RCT.
CONFINE: Conformal Prediction for Interpretable Neural Networks
Jun 01, 2024



Deep neural networks exhibit remarkable performance, yet their black-box nature limits their utility in fields like healthcare where interpretability is crucial. Existing explainability approaches often sacrifice accuracy and lack quantifiable measures of prediction uncertainty. In this study, we introduce Conformal Prediction for Interpretable Neural Networks (CONFINE), a versatile framework that generates prediction sets with statistically robust uncertainty estimates instead of point predictions to enhance model transparency and reliability. CONFINE not only provides example-based explanations and confidence estimates for individual predictions but also boosts accuracy by up to 3.6%. We define a new metric, correct efficiency, to evaluate the fraction of prediction sets that contain precisely the correct label and show that CONFINE achieves correct efficiency of up to 3.3% higher than the original accuracy, matching or exceeding prior methods. CONFINE's marginal and class-conditional coverages attest to its validity across tasks spanning medical image classification to language understanding. Being adaptable to any pre-trained classifier, CONFINE marks a significant advance towards transparent and trustworthy deep learning applications in critical domains.
TAD-SIE: Sample Size Estimation for Clinical Randomized Controlled Trials using a Trend-Adaptive Design with a Synthetic-Intervention-Based Estimator
Jan 08, 2024Phase-3 clinical trials provide the highest level of evidence on drug safety and effectiveness needed for market approval by implementing large randomized controlled trials (RCTs). However, 30-40% of these trials fail mainly because such studies have inadequate sample sizes, stemming from the inability to obtain accurate initial estimates of average treatment effect parameters. To remove this obstacle from the drug development cycle, we present a new algorithm called Trend-Adaptive Design with a Synthetic-Intervention-Based Estimator (TAD-SIE) that appropriately powers a parallel-group trial, a standard RCT design, by leveraging a state-of-the-art hypothesis testing strategy and a novel trend-adaptive design (TAD). Specifically, TAD-SIE uses SECRETS (Subject-Efficient Clinical Randomized Controlled Trials using Synthetic Intervention) for hypothesis testing, which simulates a cross-over trial in order to boost power; doing so, makes it easier for a trial to reach target power within trial constraints (e.g., sample size limits). To estimate sample sizes, TAD-SIE implements a new TAD tailored to SECRETS given that SECRETS violates assumptions under standard TADs. In addition, our TAD overcomes the ineffectiveness of standard TADs by allowing sample sizes to be increased across iterations without any condition while controlling significance level with futility stopping. On a real-world Phase-3 clinical RCT (i.e., a two-arm parallel-group superiority trial with an equal number of subjects per arm), TAD-SIE reaches typical target operating points of 80% or 90% power and 5% significance level in contrast to baseline algorithms that only get at best 59% power and 4% significance level.
SECRETS: Subject-Efficient Clinical Randomized Controlled Trials using Synthetic Intervention
May 08, 2023


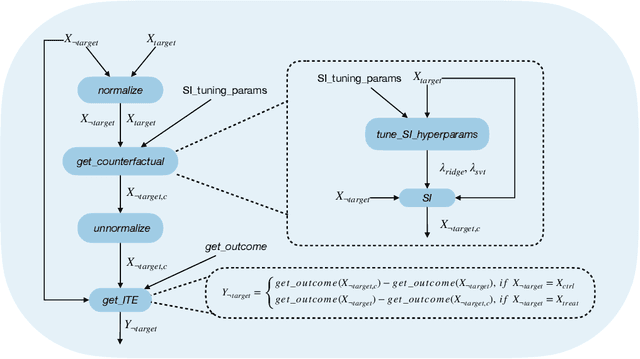
The randomized controlled trial (RCT) is the gold standard for estimating the average treatment effect (ATE) of a medical intervention but requires 100s-1000s of subjects, making it expensive and difficult to implement. While a cross-over trial can reduce sample size requirements by measuring the treatment effect per individual, it is only applicable to chronic conditions and interventions whose effects dissipate rapidly. Another approach is to replace or augment data collected from an RCT with external data from prospective studies or prior RCTs, but it is vulnerable to confounders in the external or augmented data. We propose to simulate the cross-over trial to overcome its practical limitations while exploiting its strengths. We propose a novel framework, SECRETS, which, for the first time, estimates the individual treatment effect (ITE) per patient in the RCT study without using any external data by leveraging a state-of-the-art counterfactual estimation algorithm, called synthetic intervention. It also uses a new hypothesis testing strategy to determine whether the treatment has a clinically significant ATE based on the estimated ITEs. We show that SECRETS can improve the power of an RCT while maintaining comparable significance levels; in particular, on three real-world clinical RCTs (Phase-3 trials), SECRETS increases power over the baseline method by $\boldsymbol{6}$-$\boldsymbol{54\%}$ (average: 21.5%, standard deviation: 15.8%).
Semi-Supervised Learning for Fetal Brain MRI Quality Assessment with ROI consistency
Jun 23, 2020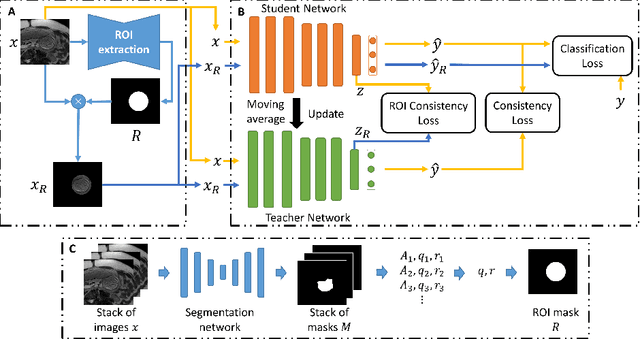
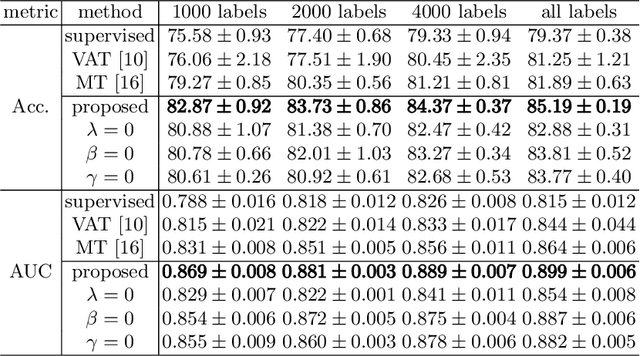
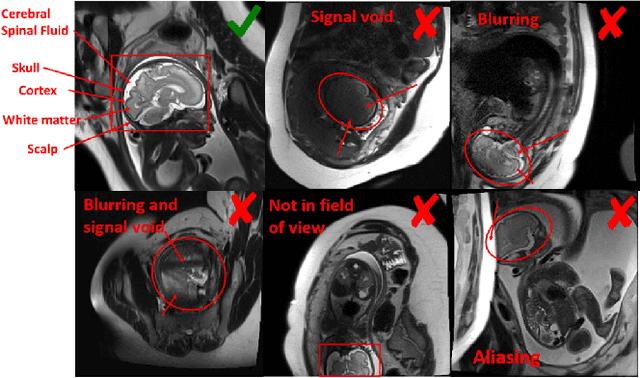
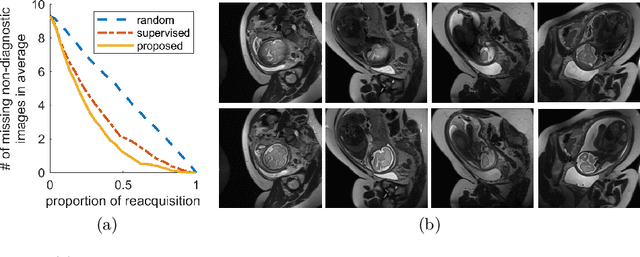
Fetal brain MRI is useful for diagnosing brain abnormalities but is challenged by fetal motion. The current protocol for T2-weighted fetal brain MRI is not robust to motion so image volumes are degraded by inter- and intra- slice motion artifacts. Besides, manual annotation for fetal MR image quality assessment are usually time-consuming. Therefore, in this work, a semi-supervised deep learning method that detects slices with artifacts during the brain volume scan is proposed. Our method is based on the mean teacher model, where we not only enforce consistency between student and teacher models on the whole image, but also adopt an ROI consistency loss to guide the network to focus on the brain region. The proposed method is evaluated on a fetal brain MR dataset with 11,223 labeled images and more than 200,000 unlabeled images. Results show that compared with supervised learning, the proposed method can improve model accuracy by about 6\% and outperform other state-of-the-art semi-supervised learning methods. The proposed method is also implemented and evaluated on an MR scanner, which demonstrates the feasibility of online image quality assessment and image reacquisition during fetal MR scans.