 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Dynamic Inference with Deep Neural Networks
Paper and Code
Jul 29, 2020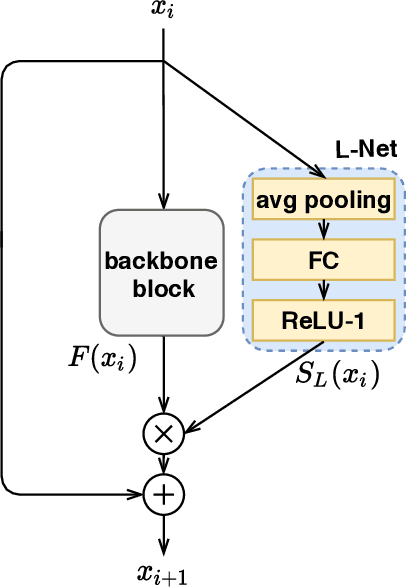
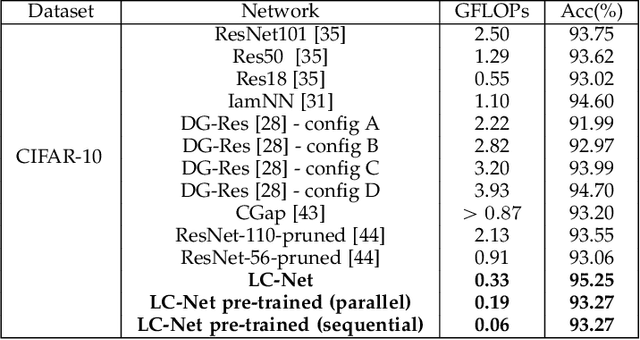
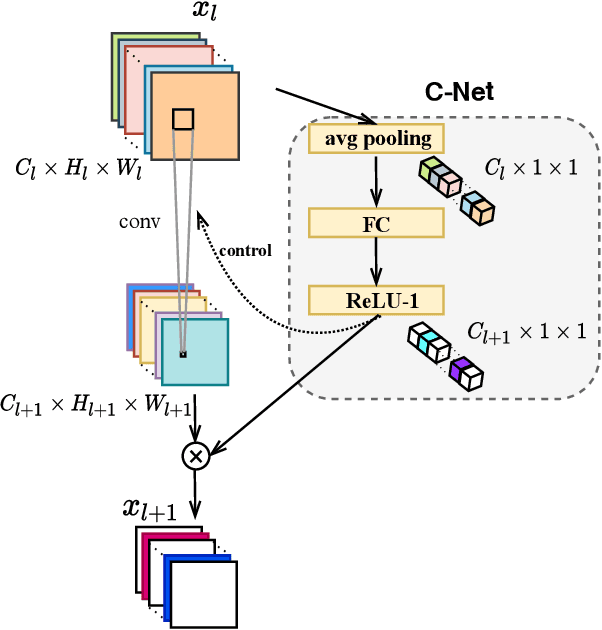

Modern deep neural networks are powerful and widely applicable models that extract task-relevant information through multi-level abstraction. Their cross-domain success, however, is often achieved at the expense of computational cost, high memory bandwidth, and long inference latency, which prevents their deployment in resource-constrained and time-sensitive scenarios, such as edge-side inference and self-driving cars. While recently developed methods for creating efficient deep neural networks are making their real-world deployment more feasible by reducing model size, they do not fully exploit input properties on a per-instance basis to maximize computational efficiency and task accuracy. In particular, most existing methods typically use a one-size-fits-all approach that identically processes all inputs. Motivated by the fact that different images require different feature embeddings to be accurately classified, we propose a fully dynamic paradigm that imparts deep convolutional neural networks with hierarchical inference dynamics at the level of layers and individual convolutional filters/channels. Two compact networks, called Layer-Net (L-Net) and Channel-Net (C-Net), predict on a per-instance basis which layers or filters/channels are redundant and therefore should be skipped. L-Net and C-Net also learn how to scale retained computation outputs to maximize task accuracy. By integrating L-Net and C-Net into a joint design framework, called LC-Net, we consistently outperform state-of-the-art dynamic frameworks with respect to both efficiency and classification accuracy. On the CIFAR-10 dataset, LC-Net results in up to 11.9$\times$ fewer floating-point operations (FLOPs) and up to 3.3% higher accuracy compared to other dynamic inference methods. On the ImageNet dataset, LC-Net achieves up to 1.4$\times$ fewer FLOPs and up to 4.6% higher Top-1 accuracy than the other methods.