 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClearSight: Visual Signal Enhancement for Object Hallucination Mitigation in Multimodal Large language Models
Mar 17, 2025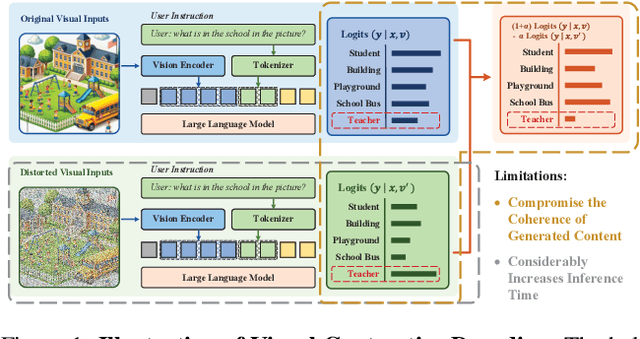

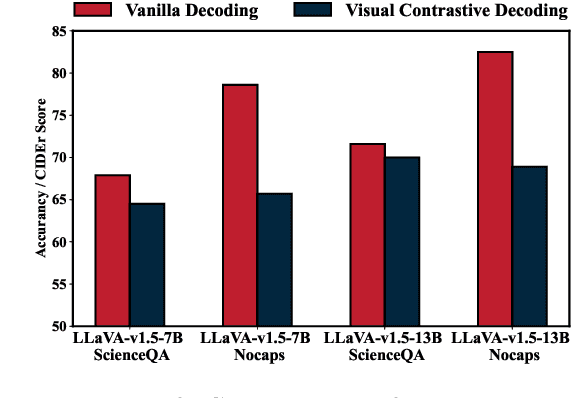

Contrastive decoding strategies are widely used to mitigate object hallucinations in multimodal large language models (MLLMs). By reducing over-reliance on language priors, these strategies ensure that generated content remains closely grounded in visual inputs, producing contextually accurate outputs. Since contrastive decoding requires no additional training or external tools, it offers both computational efficiency and versatility, making it highly attractive. However, these methods present two main limitations: (1) bluntly suppressing language priors can compromise coherence and accuracy of generated content, and (2) processing contrastive inputs adds computational load, significantly slowing inference speed. To address these challenges, we propose Visual Amplification Fusion (VAF), a plug-and-play technique that enhances attention to visual signals within the model's middle layers, where modality fusion predominantly occurs. This approach enables more effective capture of visual features, reducing the model's bias toward language modality. Experimental results demonstrate that VAF significantly reduces hallucinations across various MLLMs without affecting inference speed, while maintaining coherence and accuracy in generated outputs.
Lifting the Veil on Visual Information Flow in MLLMs: Unlocking Pathways to Faster Inference
Mar 17, 2025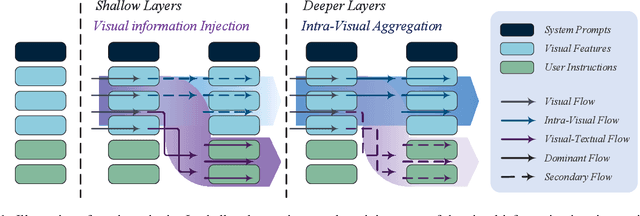
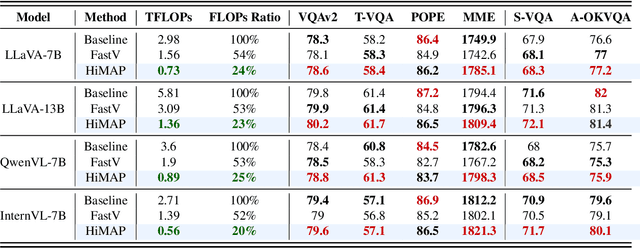
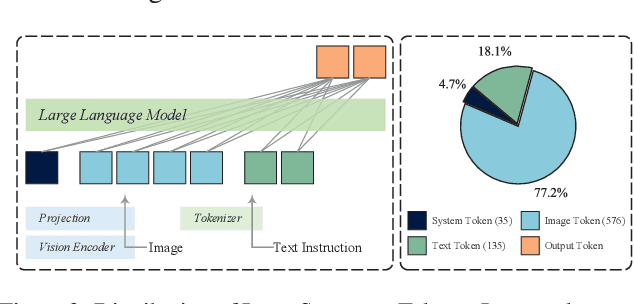
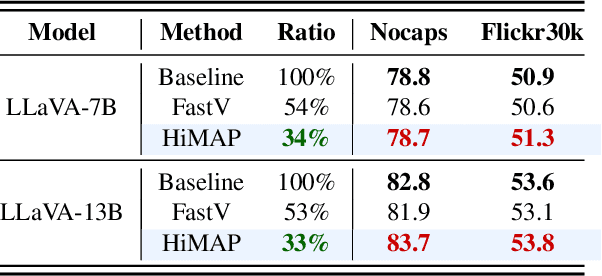
Multimodal large language models (MLLMs) improve performance on vision-language tasks by integrating visual features from pre-trained vision encoders into large language models (LLMs). However, how MLLMs process and utilize visual information remains unclear. In this paper, a shift in the dominant flow of visual information is uncovered: (1) in shallow layers, strong interactions are observed between image tokens and instruction tokens, where most visual information is injected into instruction tokens to form cross-modal semantic representations; (2) in deeper layers, image tokens primarily interact with each other, aggregating the remaining visual information to optimize semantic representations within visual modality. Based on these insights, we propose Hierarchical Modality-Aware Pruning (HiMAP), a plug-and-play inference acceleration method that dynamically prunes image tokens at specific layers, reducing computational costs by approximately 65% without sacrificing performance. Our findings offer a new understanding of visual information processing in MLLMs and provide a state-of-the-art solution for efficient inference.