 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStarWhisper Telescope: Agent-Based Observation Assistant System to Approach AI Astrophysicist
Dec 09, 2024



With the rapid advancements in Large Language Models (LLMs), LLM-based agents have introduced convenient and user-friendly methods for leveraging tools across various domains. In the field of astronomical observation, the construction of new telescopes has significantly increased astronomers' workload. Deploying LLM-powered agents can effectively alleviate this burden and reduce the costs associated with training personnel. Within the Nearby Galaxy Supernovae Survey (NGSS) project, which encompasses eight telescopes across three observation sites, aiming to find the transients from the galaxies in 50 mpc, we have developed the \textbf{StarWhisper Telescope System} to manage the entire observation process. This system automates tasks such as generating observation lists, conducting observations, analyzing data, and providing feedback to the observer. Observation lists are customized for different sites and strategies to ensure comprehensive coverage of celestial objects. After manual verification, these lists are uploaded to the telescopes via the agents in the system, which initiates observations upon neutral language. The observed images are analyzed in real-time, and the transients are promptly communicated to the observer. The agent modifies them into a real-time follow-up observation proposal and send to the Xinglong observatory group chat, then add them to the next-day observation lists. Additionally, the integration of AI agents within the system provides online accessibility, saving astronomers' time and encouraging greater participation from amateur astronomers in the NGSS project.
EvSign: Sign Language Recognition and Translation with Streaming Events
Jul 17, 2024


Sign language is one of the most effective communication tools for people with hearing difficulties. Most existing works focus on improving the performance of sign language tasks on RGB videos, which may suffer from degraded recording conditions, such as fast movement of hands with motion blur and textured signer's appearance. The bio-inspired event camera, which asynchronously captures brightness change with high speed, could naturally perceive dynamic hand movements, providing rich manual clues for sign language tasks. In this work, we aim at exploring the potential of event camera in continuous sign language recognition (CSLR) and sign language translation (SLT). To promote the research, we first collect an event-based benchmark EvSign for those tasks with both gloss and spoken language annotations. EvSign dataset offers a substantial amount of high-quality event streams and an extensive vocabulary of glosses and words, thereby facilitating the development of sign language tasks. In addition, we propose an efficient transformer-based framework for event-based SLR and SLT tasks, which fully leverages the advantages of streaming events. The sparse backbone is employed to extract visual features from sparse events. Then, the temporal coherence is effectively utilized through the proposed local token fusion and gloss-aware temporal aggregation modules. Extensive experimental results are reported on both simulated (PHOENIX14T) and EvSign datasets. Our method performs favorably against existing state-of-the-art approaches with only 0.34% computational cost (0.84G FLOPS per video) and 44.2% network parameters. The project is available at https://zhang-pengyu.github.io/EVSign.
DCPT: Darkness Clue-Prompted Tracking in Nighttime UAVs
Sep 19, 2023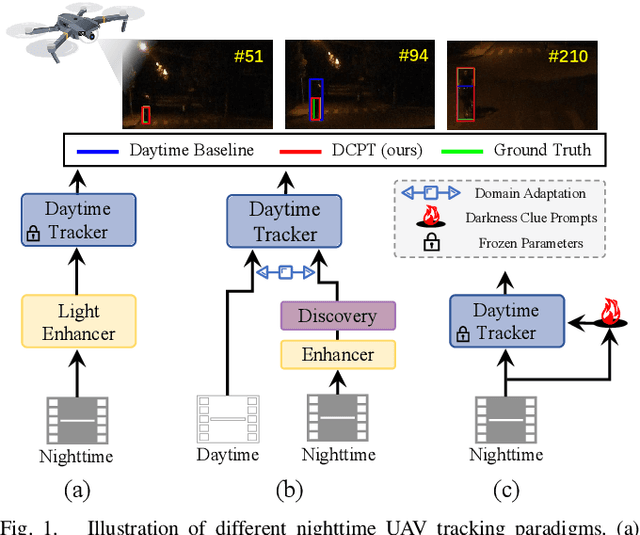
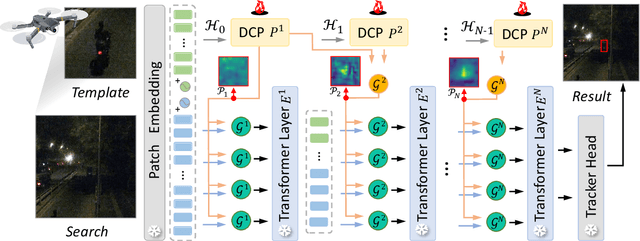
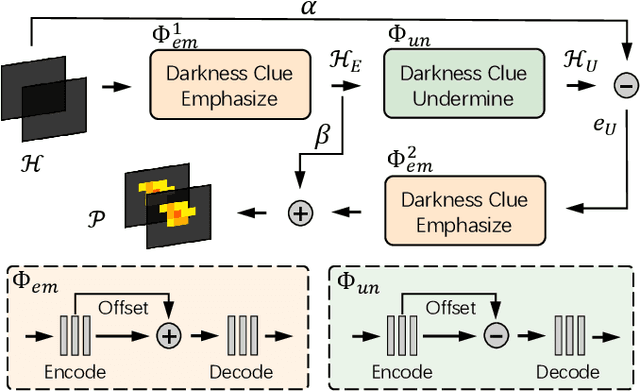
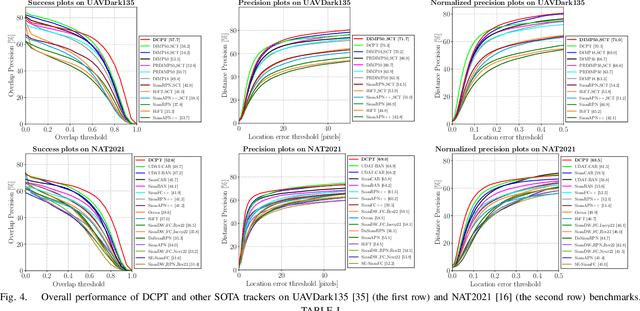
Existing nighttime unmanned aerial vehicle (UAV) trackers follow an "Enhance-then-Track" architecture - first using a light enhancer to brighten the nighttime video, then employing a daytime tracker to locate the object. This separate enhancement and tracking fails to build an end-to-end trainable vision system. To address this, we propose a novel architecture called Darkness Clue-Prompted Tracking (DCPT) that achieves robust UAV tracking at night by efficiently learning to generate darkness clue prompts. Without a separate enhancer, DCPT directly encodes anti-dark capabilities into prompts using a darkness clue prompter (DCP). Specifically, DCP iteratively learns emphasizing and undermining projections for darkness clues. It then injects these learned visual prompts into a daytime tracker with fixed parameters across transformer layers. Moreover, a gated feature aggregation mechanism enables adaptive fusion between prompts and between prompts and the base model. Extensive experiments show state-of-the-art performance for DCPT on multiple dark scenario benchmarks. The unified end-to-end learning of enhancement and tracking in DCPT enables a more trainable system. The darkness clue prompting efficiently injects anti-dark knowledge without extra modules. Code and models will be released.
Entropy-driven Sampling and Training Scheme for Conditional Diffusion Generation
Jun 27, 2022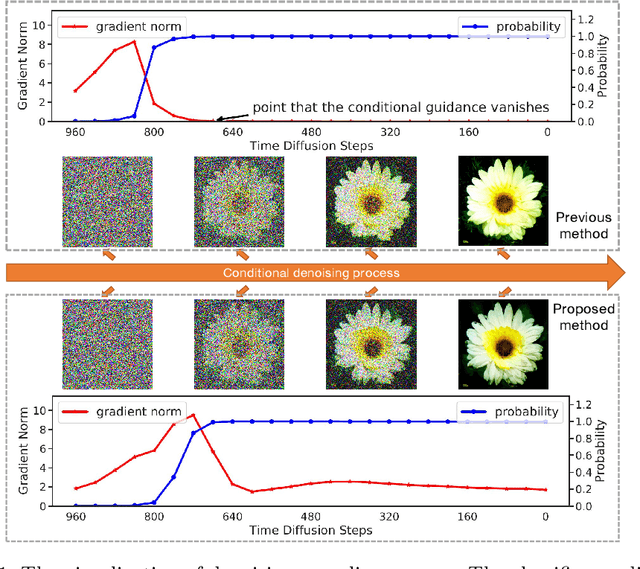
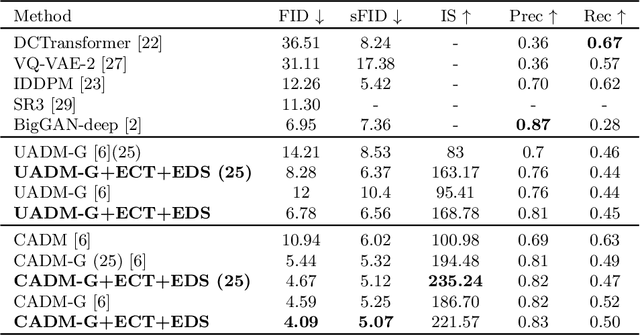
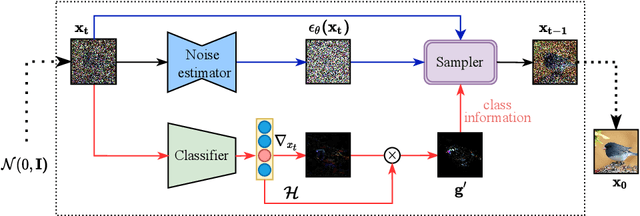
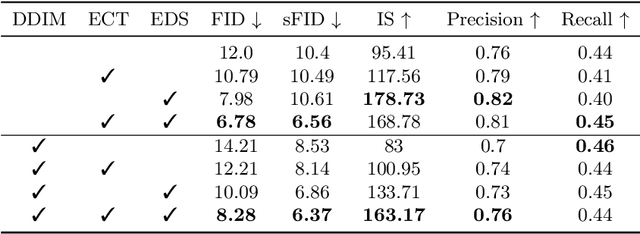
Denoising Diffusion Probabilistic Model (DDPM) is able to make flexible conditional image generation from prior noise to real data, by introducing an independent noise-aware classifier to provide conditional gradient guidance at each time step of denoising process. However, due to the ability of classifier to easily discriminate an incompletely generated image only with high-level structure, the gradient, which is a kind of class information guidance, tends to vanish early, leading to the collapse from conditional generation process into the unconditional process. To address this problem, we propose two simple but effective approaches from two perspectives. For sampling procedure, we introduce the entropy of predicted distribution as the measure of guidance vanishing level and propose an entropy-aware scaling method to adaptively recover the conditional semantic guidance. For training stage, we propose the entropy-aware optimization objectives to alleviate the overconfident prediction for noisy data.On ImageNet1000 256x256, with our proposed sampling scheme and trained classifier, the pretrained conditional and unconditional DDPM model can achieve 10.89% (4.59 to 4.09) and 43.5% (12 to 6.78) FID improvement respectively.