 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeView-decoupled Transformer for Person Re-identification under Aerial-ground Camera Network
Paper and Code
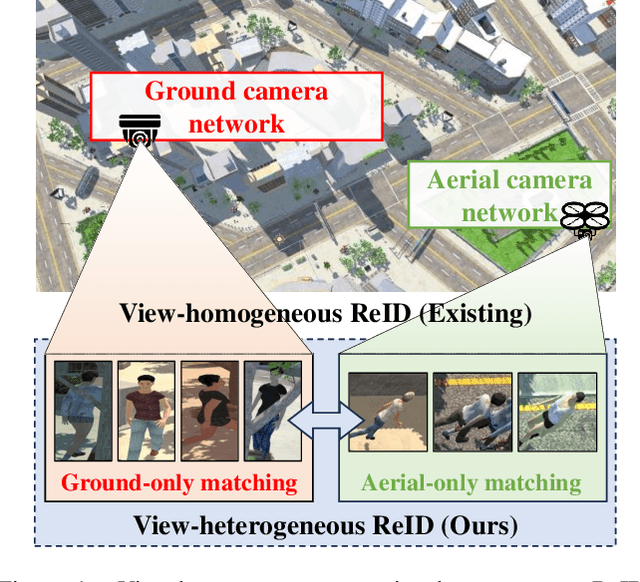

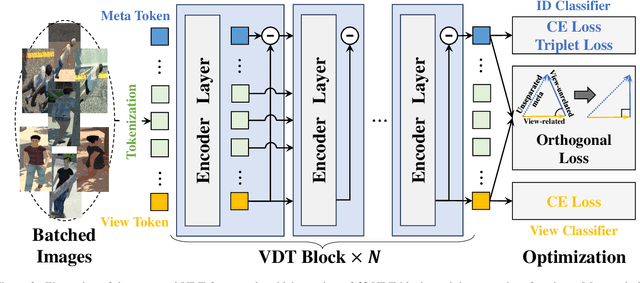

Existing person re-identification methods have achieved remarkable advances in appearance-based identity association across homogeneous cameras, such as ground-ground matching. However, as a more practical scenario, aerial-ground person re-identification (AGPReID) among heterogeneous cameras has received minimal attention. To alleviate the disruption of discriminative identity representation by dramatic view discrepancy as the most significant challenge in AGPReID, the view-decoupled transformer (VDT) is proposed as a simple yet effective framework. Two major components are designed in VDT to decouple view-related and view-unrelated features, namely hierarchical subtractive separation and orthogonal loss, where the former separates these two features inside the VDT, and the latter constrains these two to be independent. In addition, we contribute a large-scale AGPReID dataset called CARGO, consisting of five/eight aerial/ground cameras, 5,000 identities, and 108,563 images. Experiments on two datasets show that VDT is a feasible and effective solution for AGPReID, surpassing the previous method on mAP/Rank1 by up to 5.0%/2.7% on CARGO and 3.7%/5.2% on AG-ReID, keeping the same magnitude of computational complexity. Our project is available at https://github.com/LinlyAC/VDT-AGPReID