 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAKD: Feature Augmented Knowledge Distillation for Semantic Segmentation
Paper and Code
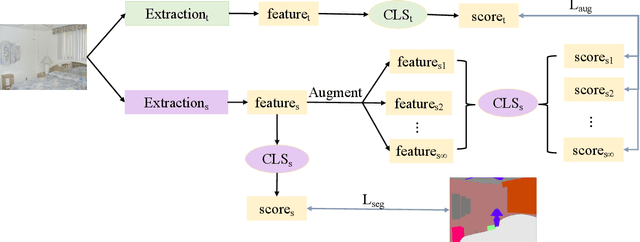
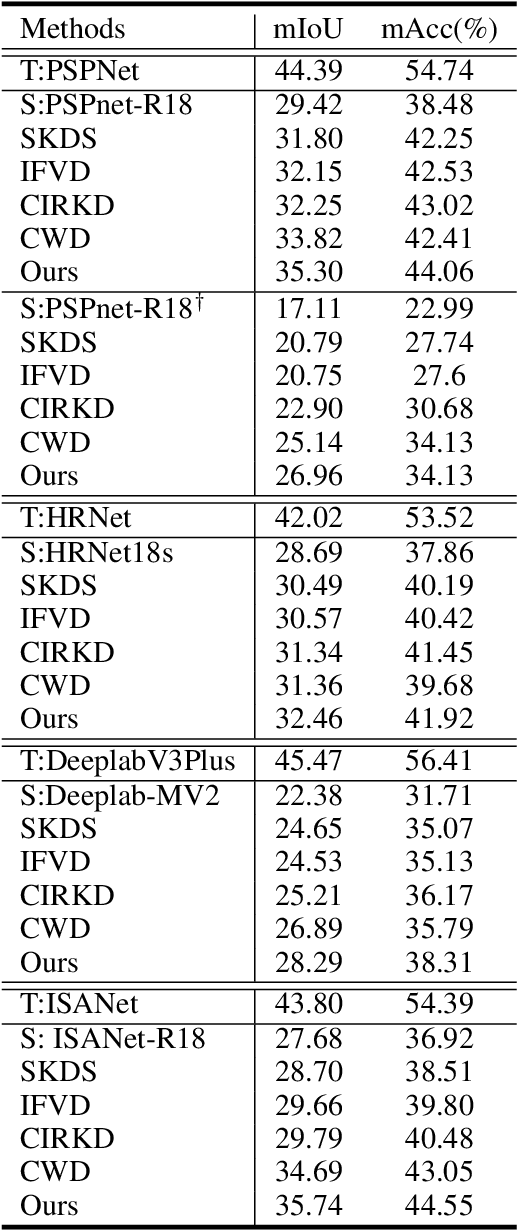
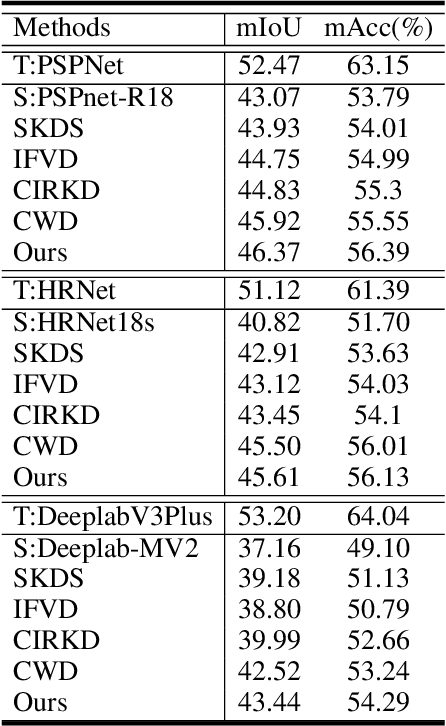
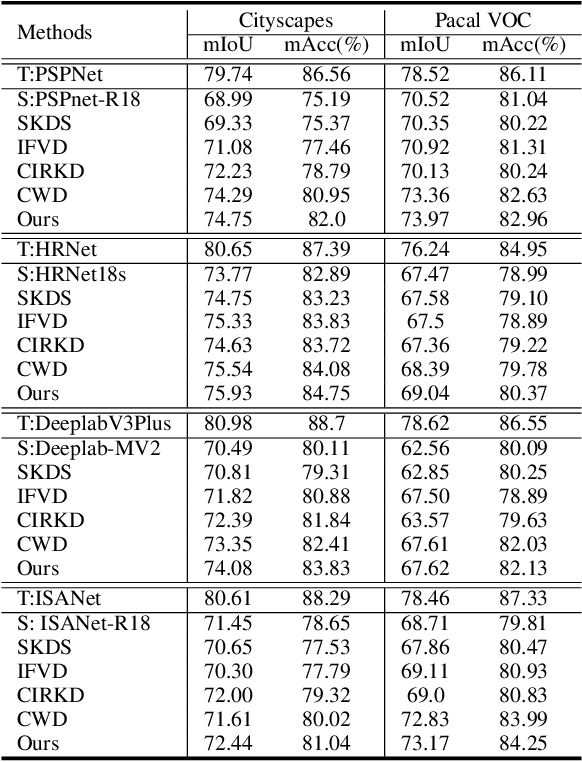
In this work, we explore data augmentations for knowledge distillation on semantic segmentation. To avoid over-fitting to the noise in the teacher network, a large number of training examples is essential for knowledge distillation. Imagelevel argumentation techniques like flipping, translation or rotation are widely used in previous knowledge distillation framework. Inspired by the recent progress on semantic directions on feature-space, we propose to include augmentations in feature space for efficient distillation. Specifically, given a semantic direction, an infinite number of augmentations can be obtained for the student in the feature space. Furthermore, the analysis shows that those augmentations can be optimized simultaneously by minimizing an upper bound for the losses defined by augmentations. Based on the observation, a new algorithm is developed for knowledge distillation in semantic segmentation. Extensive experiments on four semantic segmentation benchmarks demonstrate that the proposed method can boost the performance of current knowledge distillation methods without any significant overhead. Code is available at: https://github.com/jianlong-yuan/FAKD.