 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditing Away the Evidence: Diffusion-Based Image Manipulation and the Failure Modes of Robust Watermarking
Mar 13, 2026Robust invisible watermarks are widely used to support copyright protection, content provenance, and accountability by embedding hidden signals designed to survive common post-processing operations. However, diffusion-based image editing introduces a fundamentally different class of transformations: it injects noise and reconstructs images through a powerful generative prior, often altering semantic content while preserving photorealism. In this paper, we provide a unified theoretical and empirical analysis showing that non-adversarial diffusion editing can unintentionally degrade or remove robust watermarks. We model diffusion editing as a stochastic transformation that progressively contracts off-manifold perturbations, causing the low-amplitude signals used by many watermarking schemes to decay. Our analysis derives bounds on watermark signal-to-noise ratio and mutual information along diffusion trajectories, yielding conditions under which reliable recovery becomes information-theoretically impossible. We further evaluate representative watermarking systems under a range of diffusion-based editing scenarios and strengths. The results indicate that even routine semantic edits can significantly reduce watermark recoverability. Finally, we discuss the implications for content provenance and outline principles for designing watermarking approaches that remain robust under generative image editing.
A Mean-Field Theory of $Θ$-Expectations
Jul 30, 2025The canonical theory of sublinear expectations, a foundation of stochastic calculus under ambiguity, is insensitive to the non-convex geometry of primitive uncertainty models. This paper develops a new stochastic calculus for a structured class of such non-convex models. We introduce a class of fully coupled Mean-Field Forward-Backward Stochastic Differential Equations where the BSDE driver is defined by a pointwise maximization over a law-dependent, non-convex set. Mathematical tractability is achieved via a uniform strong concavity assumption on the driver with respect to the control variable, which ensures the optimization admits a unique and stable solution. A central contribution is to establish the Lipschitz stability of this optimizer from primitive geometric and regularity conditions, which underpins the entire well-posedness theory. We prove local and global well-posedness theorems for the FBSDE system. The resulting valuation functional, the $\Theta$-Expectation, is shown to be dynamically consistent and, most critically, to violate the axiom of sub-additivity. This, along with its failure to be translation invariant, demonstrates its fundamental departure from the convex paradigm. This work provides a rigorous foundation for stochastic calculus under a class of non-convex, endogenous ambiguity.
A Theory of $θ$-Expectations
Jul 27, 2025The canonical theory of stochastic calculus under ambiguity, founded on sub-additivity, is insensitive to non-convex uncertainty structures, leading to an identifiability impasse. This paper develops a mathematical framework for an identifiable calculus sensitive to non-convex geometry. We introduce the $\theta$-BSDE, a class of backward stochastic differential equations where the driver is determined by a pointwise maximization over a primitive, possibly non-convex, uncertainty set. The system's tractability is predicated not on convexity, but on a global analytic hypothesis: the existence of a unique and globally Lipschitz maximizer map for the driver function. Under this hypothesis, which carves out a tractable class of models, we establish well-posedness via a fixed-point argument. For a distinct, geometrically regular class of models, we prove a result of independent interest: under non-degeneracy conditions from Malliavin calculus, the maximizer is unique along any solution path, ensuring the model's internal consistency. We clarify the fundamental logical gap between this pathwise property and the global regularity required by our existence proof. The resulting valuation operator defines a dynamically consistent expectation, and we establish its connection to fully nonlinear PDEs via a Feynman-Kac formula.
Neural Hamiltonian Operator
Jul 02, 2025Stochastic control problems in high dimensions are notoriously difficult to solve due to the curse of dimensionality. An alternative to traditional dynamic programming is Pontryagin's Maximum Principle (PMP), which recasts the problem as a system of Forward-Backward Stochastic Differential Equations (FBSDEs). In this paper, we introduce a formal framework for solving such problems with deep learning by defining a \textbf{Neural Hamiltonian Operator (NHO)}. This operator parameterizes the coupled FBSDE dynamics via neural networks that represent the feedback control and an ansatz for the value function's spatial gradient. We show how the optimal NHO can be found by training the underlying networks to enforce the consistency conditions dictated by the PMP. By adopting this operator-theoretic view, we situate the deep FBSDE method within the rigorous language of statistical inference, framing it as a problem of learning an unknown operator from simulated data. This perspective allows us to prove the universal approximation capabilities of NHOs under general martingale drivers and provides a clear lens for analyzing the significant optimization challenges inherent to this class of models.
Universal Approximation Theorem for Deep Q-Learning via FBSDE System
May 09, 2025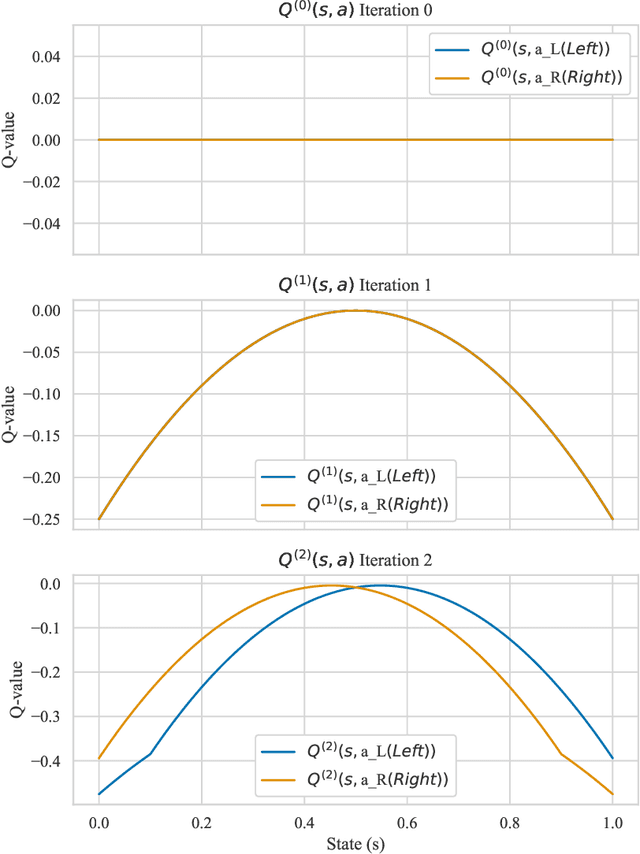
The approximation capabilities of Deep Q-Networks (DQNs) are commonly justified by general Universal Approximation Theorems (UATs) that do not leverage the intrinsic structural properties of the optimal Q-function, the solution to a Bellman equation. This paper establishes a UAT for a class of DQNs whose architecture is designed to emulate the iterative refinement process inherent in Bellman updates. A central element of our analysis is the propagation of regularity: while the transformation induced by a single Bellman operator application exhibits regularity, for which Backward Stochastic Differential Equations (BSDEs) theory provides analytical tools, the uniform regularity of the entire sequence of value iteration iterates--specifically, their uniform Lipschitz continuity on compact domains under standard Lipschitz assumptions on the problem data--is derived from finite-horizon dynamic programming principles. We demonstrate that layers of a deep residual network, conceived as neural operators acting on function spaces, can approximate the action of the Bellman operator. The resulting approximation theorem is thus intrinsically linked to the control problem's structure, offering a proof technique wherein network depth directly corresponds to iterations of value function refinement, accompanied by controlled error propagation. This perspective reveals a dynamic systems view of the network's operation on a space of value functions.
Universal Approximation Theorem of Deep Q-Networks
May 04, 2025
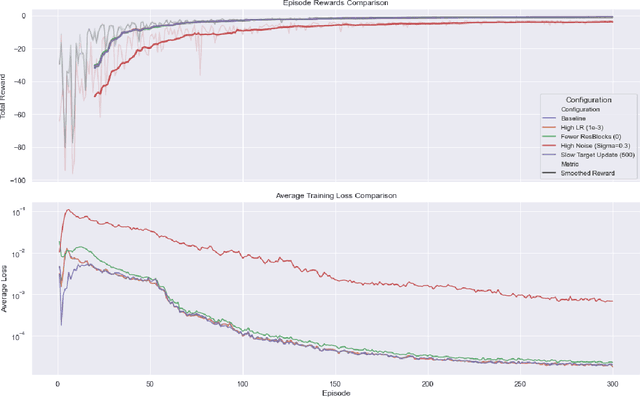
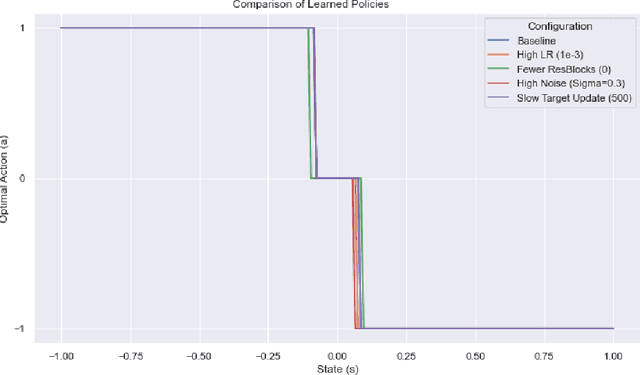
We establish a continuous-time framework for analyzing Deep Q-Networks (DQNs) via stochastic control and Forward-Backward Stochastic Differential Equations (FBSDEs). Considering a continuous-time Markov Decision Process (MDP) driven by a square-integrable martingale, we analyze DQN approximation properties. We show that DQNs can approximate the optimal Q-function on compact sets with arbitrary accuracy and high probability, leveraging residual network approximation theorems and large deviation bounds for the state-action process. We then analyze the convergence of a general Q-learning algorithm for training DQNs in this setting, adapting stochastic approximation theorems. Our analysis emphasizes the interplay between DQN layer count, time discretization, and the role of viscosity solutions (primarily for the value function $V^*$) in addressing potential non-smoothness of the optimal Q-function. This work bridges deep reinforcement learning and stochastic control, offering insights into DQNs in continuous-time settings, relevant for applications with physical systems or high-frequency data.
mPLUG-DocOwl: Modularized Multimodal Large Language Model for Document Understanding
Jul 04, 2023



Document understanding refers to automatically extract, analyze and comprehend information from various types of digital documents, such as a web page. Existing Multi-model Large Language Models (MLLMs), including mPLUG-Owl, have demonstrated promising zero-shot capabilities in shallow OCR-free text recognition, indicating their potential for OCR-free document understanding. Nevertheless, without in-domain training, these models tend to ignore fine-grained OCR features, such as sophisticated tables or large blocks of text, which are essential for OCR-free document understanding. In this paper, we propose mPLUG-DocOwl based on mPLUG-Owl for OCR-free document understanding. Specifically, we first construct a instruction tuning dataset featuring a wide range of visual-text understanding tasks. Then, we strengthen the OCR-free document understanding ability by jointly train the model on language-only, general vision-and-language, and document instruction tuning dataset with our unified instruction tuning strategy. We also build an OCR-free document instruction understanding evaluation set LLMDoc to better compare models' capabilities on instruct compliance and document understanding. Experimental results show that our model outperforms existing multi-modal models, demonstrating its strong ability of document understanding. Besides, without specific fine-tuning, mPLUG-DocOwl generalizes well on various downstream tasks. Our code, models, training data and evaluation set are available at https://github.com/X-PLUG/mPLUG-DocOwl.
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
Apr 27, 2023



Large language models (LLMs) have demonstrated impressive zero-shot abilities on a variety of open-ended tasks, while recent research has also explored the use of LLMs for multi-modal generation. In this study, we introduce mPLUG-Owl, a novel training paradigm that equips LLMs with multi-modal abilities through modularized learning of foundation LLM, a visual knowledge module, and a visual abstractor module. This approach can support multiple modalities and facilitate diverse unimodal and multimodal abilities through modality collaboration. The training paradigm of mPLUG-Owl involves a two-stage method for aligning image and text, which learns visual knowledge with the assistance of LLM while maintaining and even improving the generation abilities of LLM. In the first stage, the visual knowledge module and abstractor module are trained with a frozen LLM module to align the image and text. In the second stage, language-only and multi-modal supervised datasets are used to jointly fine-tune a low-rank adaption (LoRA) module on LLM and the abstractor module by freezing the visual knowledge module. We carefully build a visually-related instruction evaluation set OwlEval. Experimental results show that our model outperforms existing multi-modal models, demonstrating mPLUG-Owl's impressive instruction and visual understanding ability, multi-turn conversation ability, and knowledge reasoning ability. Besides, we observe some unexpected and exciting abilities such as multi-image correlation and scene text understanding, which makes it possible to leverage it for harder real scenarios, such as vision-only document comprehension. Our code, pre-trained model, instruction-tuned models, and evaluation set are available at https://github.com/X-PLUG/mPLUG-Owl. The online demo is available at https://www.modelscope.cn/studios/damo/mPLUG-Owl.
Artificial Intelligence and Dual Contract
Mar 22, 2023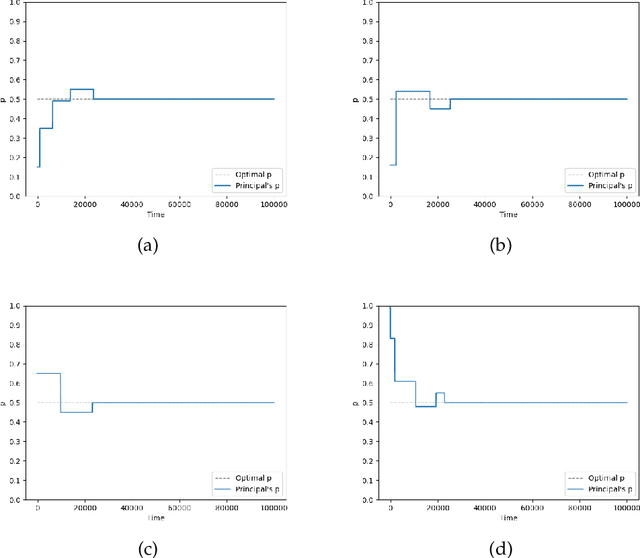
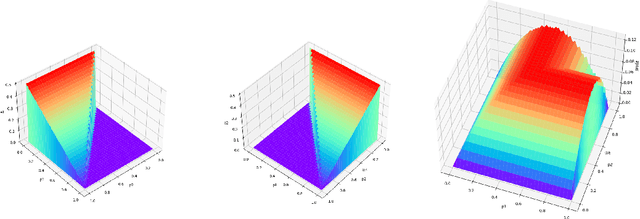
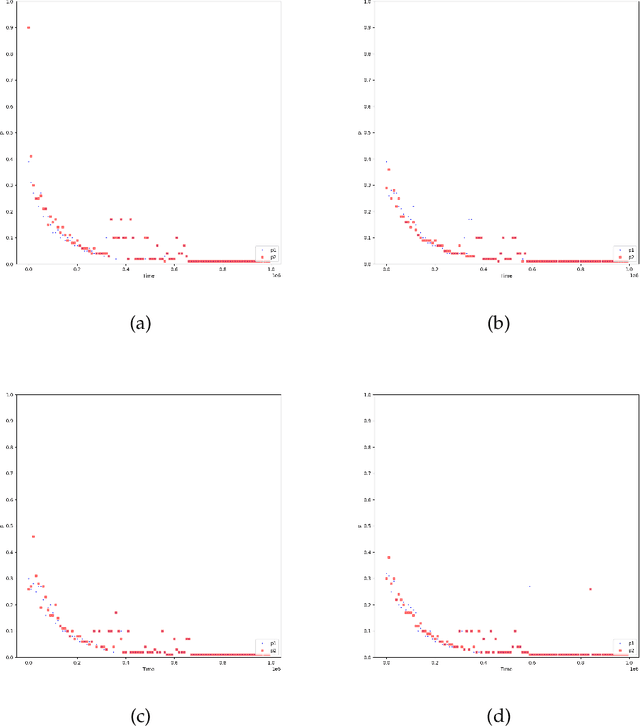
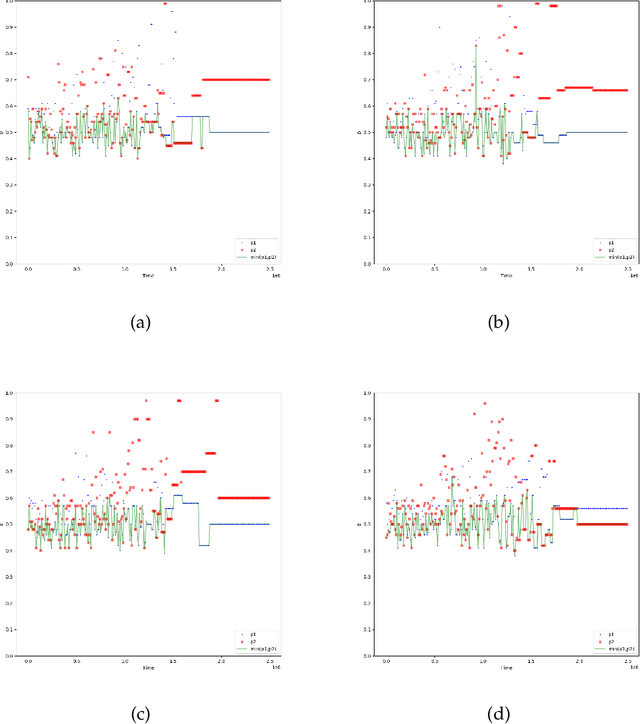
With the dramatic progress of artificial intelligence algorithms in recent times, it is hoped that algorithms will soon supplant human decision-makers in various fields, such as contract design. We analyze the possible consequences by experimentally studying the behavior of algorithms powered by Artificial Intelligence (Multi-agent Q-learning) in a workhorse \emph{dual contract} model for dual-principal-agent problems. We find that the AI algorithms autonomously learn to design incentive-compatible contracts without external guidance or communication among themselves. We emphasize that the principal, powered by distinct AI algorithms, can play mixed-sum behavior such as collusion and competition. We find that the more intelligent principals tend to become cooperative, and the less intelligent principals are endogenizing myopia and tend to become competitive. Under the optimal contract, the lower contract incentive to the agent is sustained by collusive strategies between the principals. This finding is robust to principal heterogeneity, changes in the number of players involved in the contract, and various forms of uncertainty.
FAKD: Feature Augmented Knowledge Distillation for Semantic Segmentation
Aug 30, 2022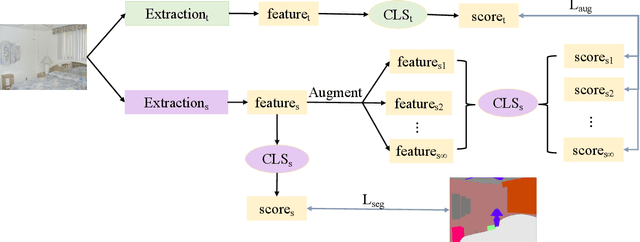
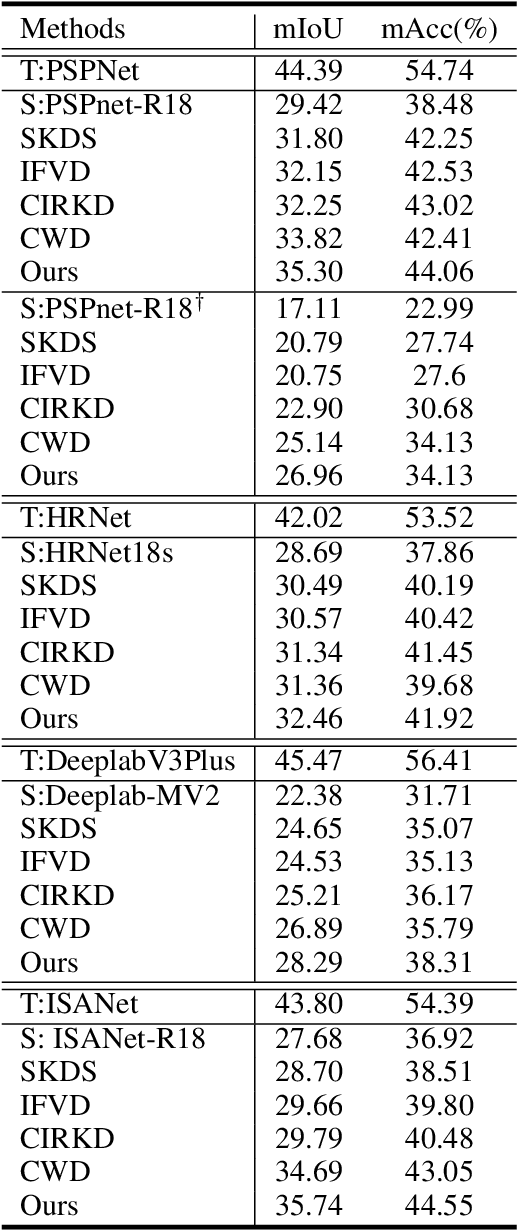
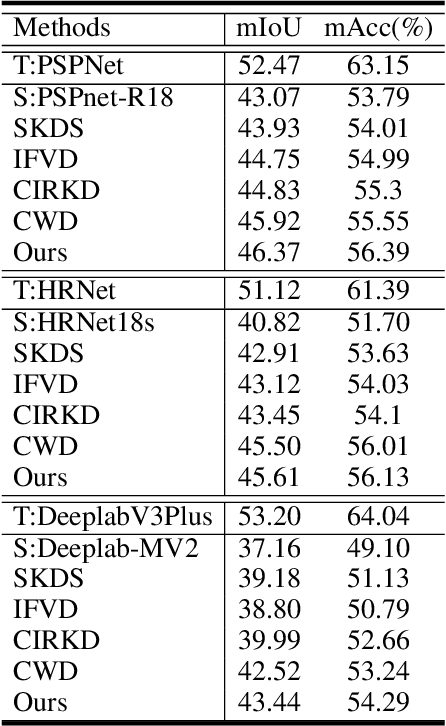
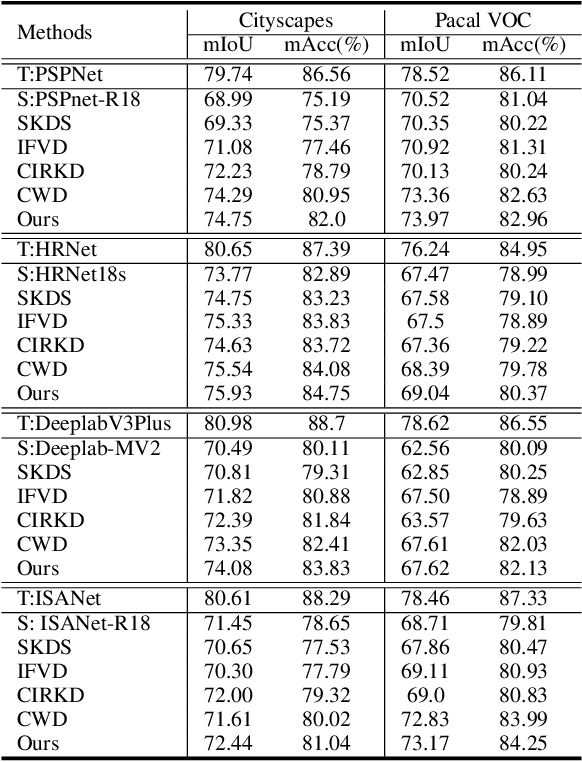
In this work, we explore data augmentations for knowledge distillation on semantic segmentation. To avoid over-fitting to the noise in the teacher network, a large number of training examples is essential for knowledge distillation. Imagelevel argumentation techniques like flipping, translation or rotation are widely used in previous knowledge distillation framework. Inspired by the recent progress on semantic directions on feature-space, we propose to include augmentations in feature space for efficient distillation. Specifically, given a semantic direction, an infinite number of augmentations can be obtained for the student in the feature space. Furthermore, the analysis shows that those augmentations can be optimized simultaneously by minimizing an upper bound for the losses defined by augmentations. Based on the observation, a new algorithm is developed for knowledge distillation in semantic segmentation. Extensive experiments on four semantic segmentation benchmarks demonstrate that the proposed method can boost the performance of current knowledge distillation methods without any significant overhead. Code is available at: https://github.com/jianlong-yuan/FAKD.