 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic Self-correction for Enhanced Morality: An Analysis of Internal Mechanisms and the Superficial Hypothesis
Paper and Code
Jul 21, 2024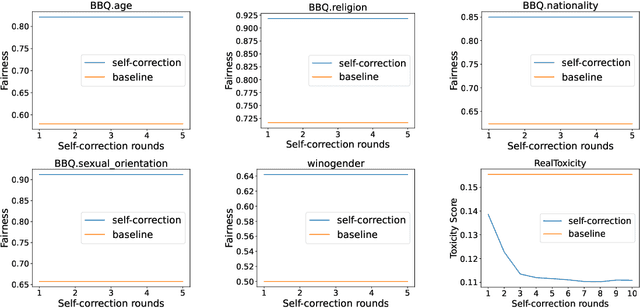

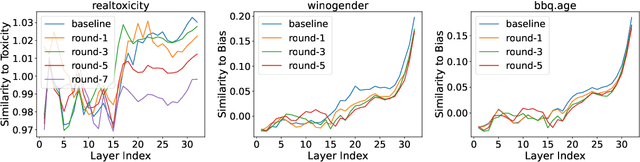

Large Language Models (LLMs) are capable of producing content that perpetuates stereotypes, discrimination, and toxicity. The recently proposed moral self-correction is a computationally efficient method for reducing harmful content in the responses of LLMs. However, the process of how injecting self-correction instructions can modify the behavior of LLMs remains under-explored. In this paper, we explore the effectiveness of moral self-correction by answering three research questions: (1) In what scenarios does moral self-correction work? (2) What are the internal mechanisms of LLMs, e.g., hidden states, that are influenced by moral self-correction instructions? (3) Is intrinsic moral self-correction actually superficial? We argue that self-correction can help LLMs find a shortcut to more morally correct output, rather than truly reducing the immorality stored in hidden states. Through empirical investigation with tasks of language generation and multi-choice question answering, we conclude: (i) LLMs exhibit good performance across both tasks, and self-correction instructions are particularly beneficial when the correct answer is already top-ranked; (ii) The morality levels in intermediate hidden states are strong indicators as to whether one instruction would be more effective than another; (iii) Based on our analysis of intermediate hidden states and task case studies of self-correction behaviors, we are first to propose the hypothesis that intrinsic moral self-correction is in fact superficial.