 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeT: Code Generation with Generated Tests
Paper and Code

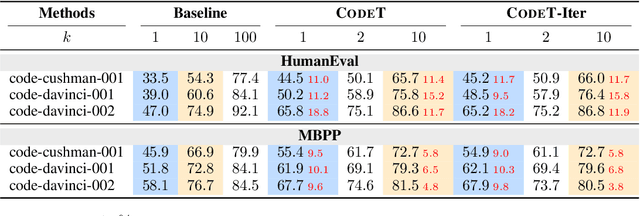

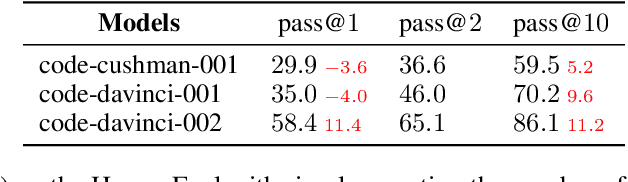
Given a programming problem, pre-trained language models such as Codex have demonstrated the ability to generate multiple different code solutions via sampling. However, selecting a correct or best solution from those samples still remains a challenge. While an easy way to verify the correctness of a code solution is through executing test cases, producing high-quality test cases is prohibitively expensive. In this paper, we explore the use of pre-trained language models to automatically generate test cases, calling our method CodeT: Code generation with generated Tests. CodeT executes the code solutions using the generated test cases, and then chooses the best solution based on a dual execution agreement with both the generated test cases and other generated solutions. We evaluate CodeT on five different pre-trained models with both HumanEval and MBPP benchmarks. Extensive experimental results demonstrate CodeT can achieve significant, consistent, and surprising improvements over previous methods. For example, CodeT improves the pass@1 on HumanEval to 65.8%, an increase of absolute 18.8% on the code-davinci-002 model, and an absolute 20+% improvement over previous state-of-the-art results.