 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Adapt Category Consistent Meta-Feature of CLIP for Few-Shot Classification
Jul 08, 2024
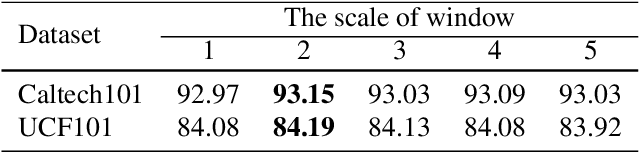
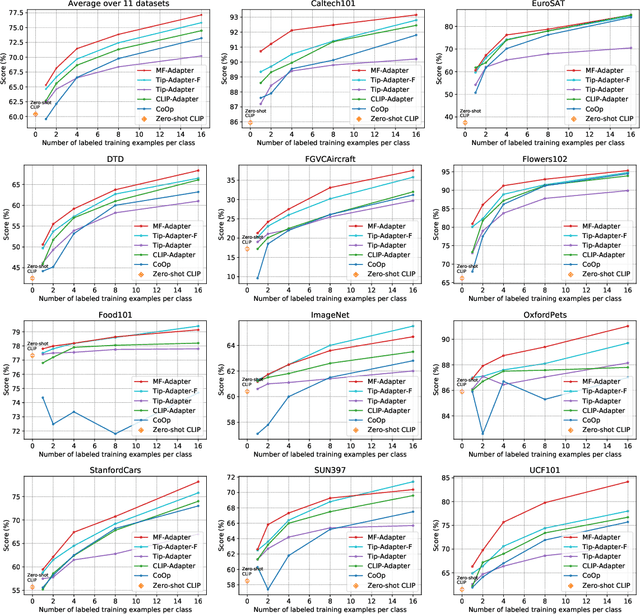
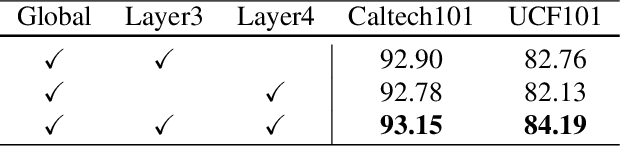
The recent CLIP-based methods have shown promising zero-shot and few-shot performance on image classification tasks. Existing approaches such as CoOp and Tip-Adapter only focus on high-level visual features that are fully aligned with textual features representing the ``Summary" of the image. However, the goal of few-shot learning is to classify unseen images of the same category with few labeled samples. Especially, in contrast to high-level representations, local representations (LRs) at low-level are more consistent between seen and unseen samples. Based on this point, we propose the Meta-Feature Adaption method (MF-Adapter) that combines the complementary strengths of both LRs and high-level semantic representations. Specifically, we introduce the Meta-Feature Unit (MF-Unit), which is a simple yet effective local similarity metric to measure category-consistent local context in an inductive manner. Then we train an MF-Adapter to map image features to MF-Unit for adequately generalizing the intra-class knowledge between unseen images and the support set. Extensive experiments show that our proposed method is superior to the state-of-the-art CLIP downstream few-shot classification methods, even showing stronger performance on a set of challenging visual classification tasks.
Learning Positional Attention for Sequential Recommendation
Jul 03, 2024
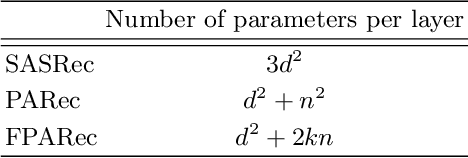

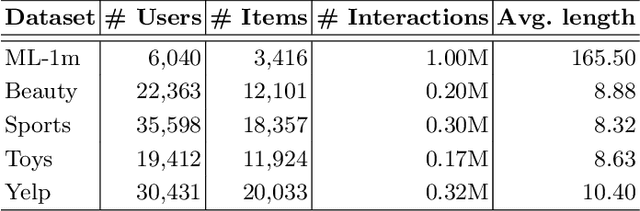
Self-attention-based networks have achieved remarkable performance in sequential recommendation tasks. A crucial component of these models is positional encoding. In this study, we delve into the learned positional embedding, demonstrating that it often captures the distance between tokens. Building on this insight, we introduce novel attention models that directly learn positional relations. Extensive experiments reveal that our proposed models, \textbf{PARec} and \textbf{FPARec} outperform previous self-attention-based approaches.Our code is available at the link for anonymous review: https://anonymous.4open.science/ r/FPARec-2C55/
Heterogeneous Graph-based Framework with Disentangled Representations Learning for Multi-target Cross Domain Recommendation
Jul 01, 2024CDR (Cross-Domain Recommendation), i.e., leveraging information from multiple domains, is a critical solution to data sparsity problem in recommendation system. The majority of previous research either focused on single-target CDR (STCDR) by utilizing data from the source domains to improve the model's performance on the target domain, or applied dual-target CDR (DTCDR) by integrating data from the source and target domains. In addition, multi-target CDR (MTCDR) is a generalization of DTCDR, which is able to capture the link among different domains. In this paper we present HGDR (Heterogeneous Graph-based Framework with Disentangled Representations Learning), an end-to-end heterogeneous network architecture where graph convolutional layers are applied to model relations among different domains, meanwhile utilizes the idea of disentangling representation for domain-shared and domain-specifc information. First, a shared heterogeneous graph is generated by gathering users and items from several domains without any further side information. Second, we use HGDR to compute disentangled representations for users and items in all domains.Experiments on real-world datasets and online A/B tests prove that our proposed model can transmit information among domains effectively and reach the SOTA performance.
Controllable Talking Face Generation by Implicit Facial Keypoints Editing
Jun 05, 2024Audio-driven talking face generation has garnered significant interest within the domain of digital human research. Existing methods are encumbered by intricate model architectures that are intricately dependent on each other, complicating the process of re-editing image or video inputs. In this work, we present ControlTalk, a talking face generation method to control face expression deformation based on driven audio, which can construct the head pose and facial expression including lip motion for both single image or sequential video inputs in a unified manner. By utilizing a pre-trained video synthesis renderer and proposing the lightweight adaptation, ControlTalk achieves precise and naturalistic lip synchronization while enabling quantitative control over mouth opening shape. Our experiments show that our method is superior to state-of-the-art performance on widely used benchmarks, including HDTF and MEAD. The parameterized adaptation demonstrates remarkable generalization capabilities, effectively handling expression deformation across same-ID and cross-ID scenarios, and extending its utility to out-of-domain portraits, regardless of languages.
Cross-Scale Context Extracted Hashing for Fine-Grained Image Binary Encoding
Oct 14, 2022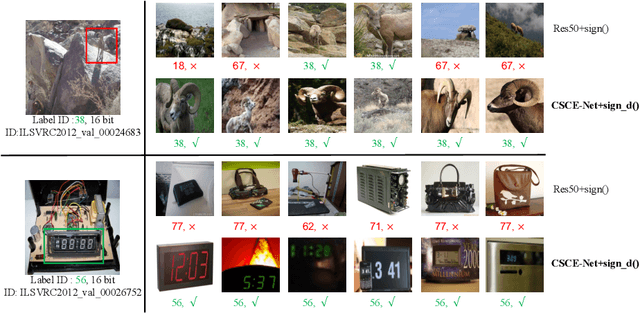
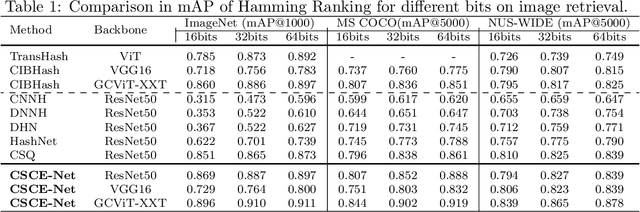
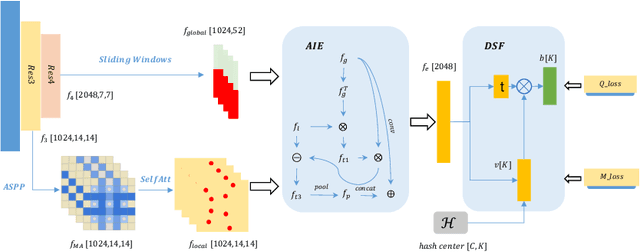
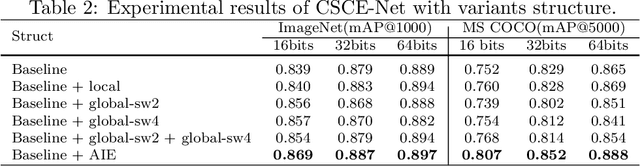
Deep hashing has been widely applied to large-scale image retrieval tasks owing to efficient computation and low storage cost by encoding high-dimensional image data into binary codes. Since binary codes do not contain as much information as float features, the essence of binary encoding is preserving the main context to guarantee retrieval quality. However, the existing hashing methods have great limitations on suppressing redundant background information and accurately encoding from Euclidean space to Hamming space by a simple sign function. In order to solve these problems, a Cross-Scale Context Extracted Hashing Network (CSCE-Net) is proposed in this paper. Firstly, we design a two-branch framework to capture fine-grained local information while maintaining high-level global semantic information. Besides, Attention guided Information Extraction module (AIE) is introduced between two branches, which suppresses areas of low context information cooperated with global sliding windows. Unlike previous methods, our CSCE-Net learns a content-related Dynamic Sign Function (DSF) to replace the original simple sign function. Therefore, the proposed CSCE-Net is context-sensitive and able to perform well on accurate image binary encoding. We further demonstrate that our CSCE-Net is superior to the existing hashing methods, which improves retrieval performance on standard benchmarks.
RANSAC based three points algorithm for ellipse fitting of spherical object's projection
Jan 30, 2015


As the spherical object can be seen everywhere, we should extract the ellipse image accurately and fit it by implicit algebraic curve in order to finish the 3D reconstruction. In this paper, we propose a new ellipse fitting algorithm which only needs three points to fit the projection of spherical object and is different from the traditional algorithms that need at least five point. The fitting procedure is just similar as the estimation of Fundamental Matrix estimation by seven points, and the RANSAC algorithm has also been used to exclude the interference of noise and scattered points.