Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Positional Attention for Sequential Recommendation
Paper and Code
Jul 03, 2024
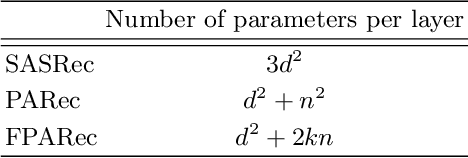

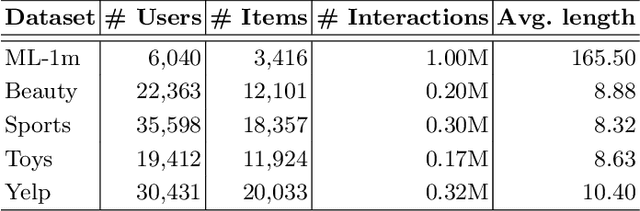
Self-attention-based networks have achieved remarkable performance in sequential recommendation tasks. A crucial component of these models is positional encoding. In this study, we delve into the learned positional embedding, demonstrating that it often captures the distance between tokens. Building on this insight, we introduce novel attention models that directly learn positional relations. Extensive experiments reveal that our proposed models, \textbf{PARec} and \textbf{FPARec} outperform previous self-attention-based approaches.Our code is available at the link for anonymous review: https://anonymous.4open.science/ r/FPARec-2C55/
View paper on