 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Adapt Category Consistent Meta-Feature of CLIP for Few-Shot Classification
Jul 08, 2024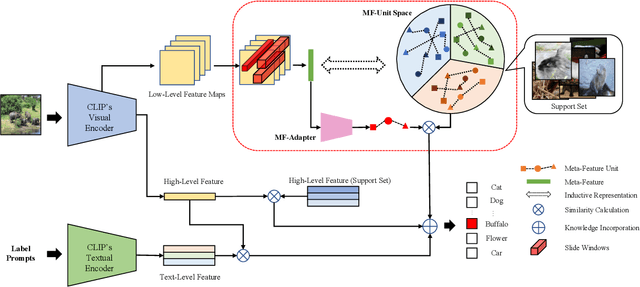
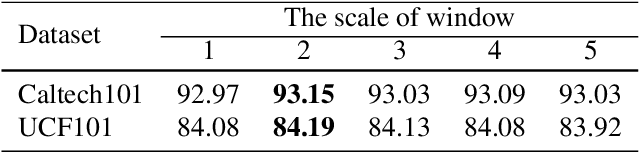
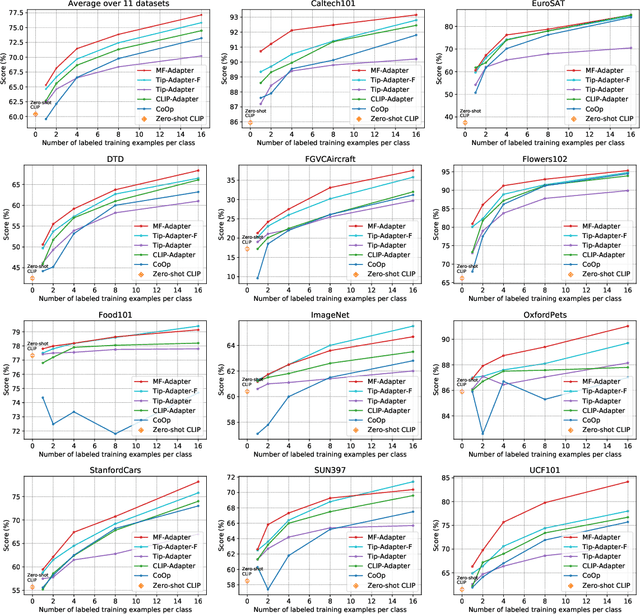
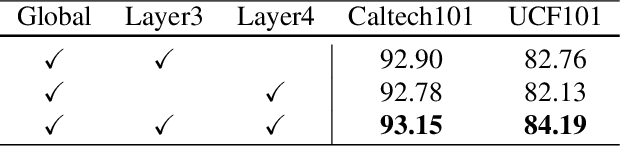
The recent CLIP-based methods have shown promising zero-shot and few-shot performance on image classification tasks. Existing approaches such as CoOp and Tip-Adapter only focus on high-level visual features that are fully aligned with textual features representing the ``Summary" of the image. However, the goal of few-shot learning is to classify unseen images of the same category with few labeled samples. Especially, in contrast to high-level representations, local representations (LRs) at low-level are more consistent between seen and unseen samples. Based on this point, we propose the Meta-Feature Adaption method (MF-Adapter) that combines the complementary strengths of both LRs and high-level semantic representations. Specifically, we introduce the Meta-Feature Unit (MF-Unit), which is a simple yet effective local similarity metric to measure category-consistent local context in an inductive manner. Then we train an MF-Adapter to map image features to MF-Unit for adequately generalizing the intra-class knowledge between unseen images and the support set. Extensive experiments show that our proposed method is superior to the state-of-the-art CLIP downstream few-shot classification methods, even showing stronger performance on a set of challenging visual classification tasks.
MindSemantix: Deciphering Brain Visual Experiences with a Brain-Language Model
May 29, 2024Deciphering the human visual experience through brain activities captured by fMRI represents a compelling and cutting-edge challenge in the field of neuroscience research. Compared to merely predicting the viewed image itself, decoding brain activity into meaningful captions provides a higher-level interpretation and summarization of visual information, which naturally enhances the application flexibility in real-world situations. In this work, we introduce MindSemantix, a novel multi-modal framework that enables LLMs to comprehend visually-evoked semantic content in brain activity. Our MindSemantix explores a more ideal brain captioning paradigm by weaving LLMs into brain activity analysis, crafting a seamless, end-to-end Brain-Language Model. To effectively capture semantic information from brain responses, we propose Brain-Text Transformer, utilizing a Brain Q-Former as its core architecture. It integrates a pre-trained brain encoder with a frozen LLM to achieve multi-modal alignment of brain-vision-language and establish a robust brain-language correspondence. To enhance the generalizability of neural representations, we pre-train our brain encoder on a large-scale, cross-subject fMRI dataset using self-supervised learning techniques. MindSemantix provides more feasibility to downstream brain decoding tasks such as stimulus reconstruction. Conditioned by MindSemantix captioning, our framework facilitates this process by integrating with advanced generative models like Stable Diffusion and excels in understanding brain visual perception. MindSemantix generates high-quality captions that are deeply rooted in the visual and semantic information derived from brain activity. This approach has demonstrated substantial quantitative improvements over prior art. Our code will be released.
Cross-Scale Context Extracted Hashing for Fine-Grained Image Binary Encoding
Oct 14, 2022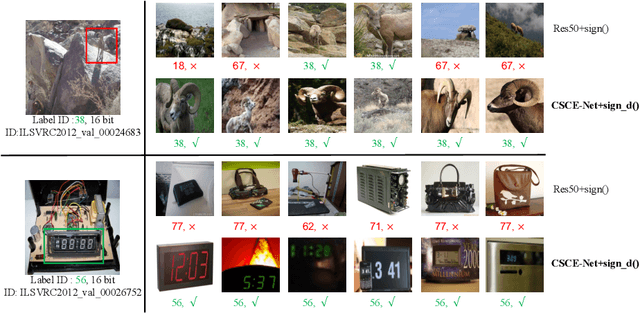
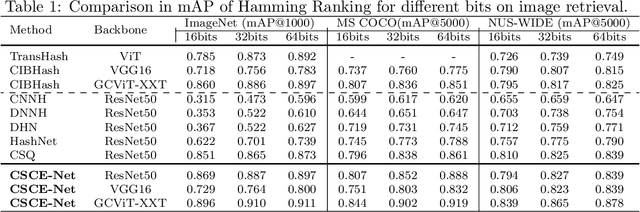
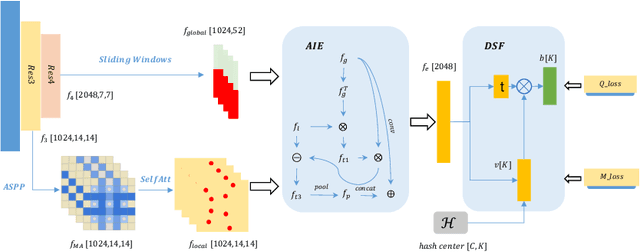
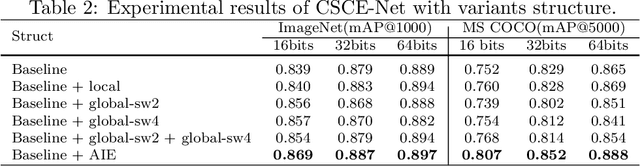
Deep hashing has been widely applied to large-scale image retrieval tasks owing to efficient computation and low storage cost by encoding high-dimensional image data into binary codes. Since binary codes do not contain as much information as float features, the essence of binary encoding is preserving the main context to guarantee retrieval quality. However, the existing hashing methods have great limitations on suppressing redundant background information and accurately encoding from Euclidean space to Hamming space by a simple sign function. In order to solve these problems, a Cross-Scale Context Extracted Hashing Network (CSCE-Net) is proposed in this paper. Firstly, we design a two-branch framework to capture fine-grained local information while maintaining high-level global semantic information. Besides, Attention guided Information Extraction module (AIE) is introduced between two branches, which suppresses areas of low context information cooperated with global sliding windows. Unlike previous methods, our CSCE-Net learns a content-related Dynamic Sign Function (DSF) to replace the original simple sign function. Therefore, the proposed CSCE-Net is context-sensitive and able to perform well on accurate image binary encoding. We further demonstrate that our CSCE-Net is superior to the existing hashing methods, which improves retrieval performance on standard benchmarks.
DOLG: Single-Stage Image Retrieval with Deep Orthogonal Fusion of Local and Global Features
Aug 11, 2021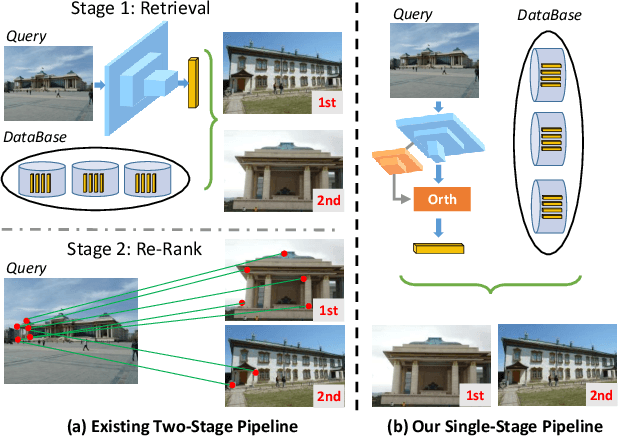
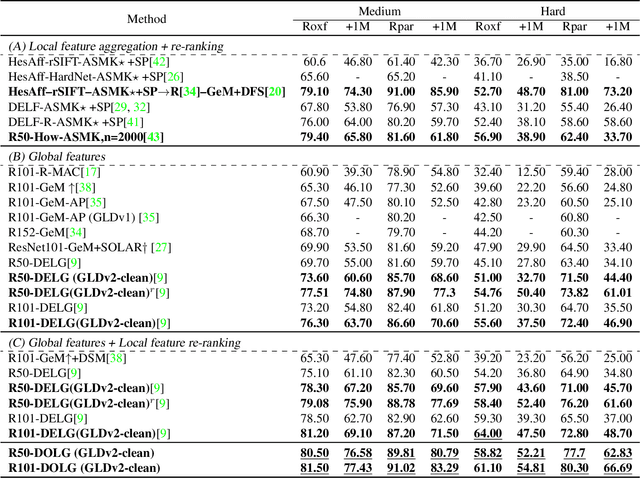
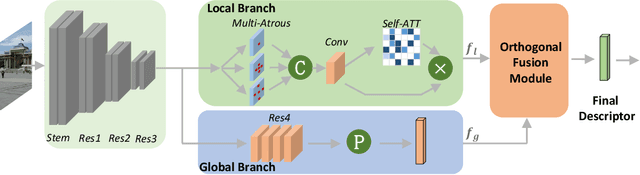
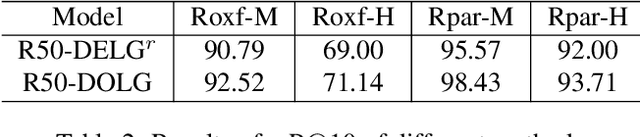
Image Retrieval is a fundamental task of obtaining images similar to the query one from a database. A common image retrieval practice is to firstly retrieve candidate images via similarity search using global image features and then re-rank the candidates by leveraging their local features. Previous learning-based studies mainly focus on either global or local image representation learning to tackle the retrieval task. In this paper, we abandon the two-stage paradigm and seek to design an effective single-stage solution by integrating local and global information inside images into compact image representations. Specifically, we propose a Deep Orthogonal Local and Global (DOLG) information fusion framework for end-to-end image retrieval. It attentively extracts representative local information with multi-atrous convolutions and self-attention at first. Components orthogonal to the global image representation are then extracted from the local information. At last, the orthogonal components are concatenated with the global representation as a complementary, and then aggregation is performed to generate the final representation. The whole framework is end-to-end differentiable and can be trained with image-level labels. Extensive experimental results validate the effectiveness of our solution and show that our model achieves state-of-the-art image retrieval performances on Revisited Oxford and Paris datasets.
Reconstructing Perceived Images from Brain Activity by Visually-guided Cognitive Representation and Adversarial Learning
Jun 27, 2019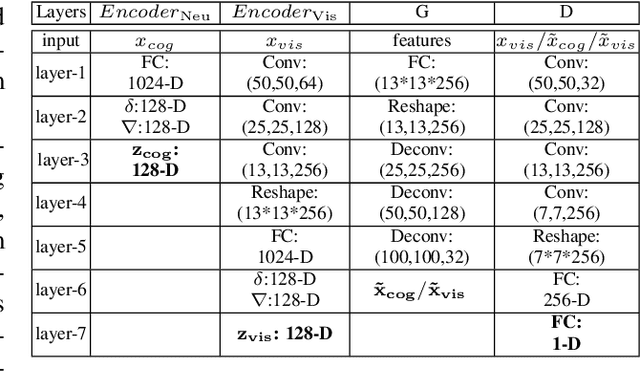
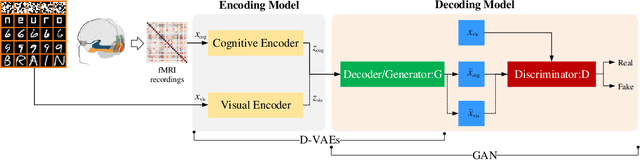
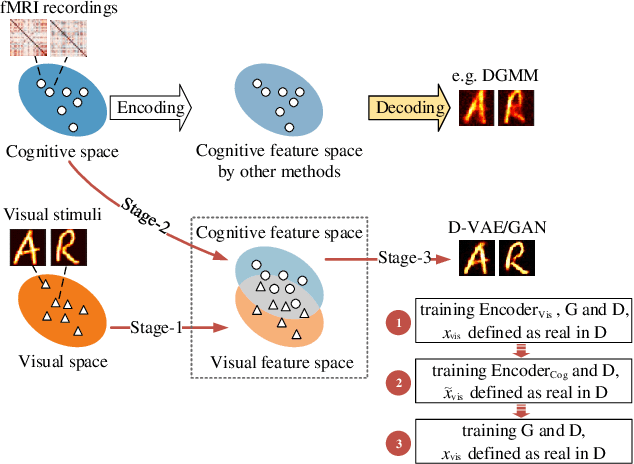
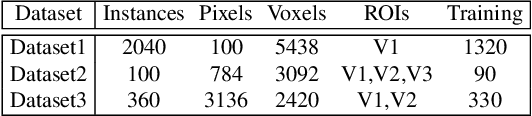
Reconstructing perceived images based on brain signals measured with functional magnetic resonance imaging (fMRI) is a significant and meaningful task in brain-driven computer vision. However, the inconsistent distribution and representation between fMRI signals and visual images cause the heterogeneity gap, which makes it challenging to learn a reliable mapping between them. Moreover, considering that fMRI signals are extremely high-dimensional and contain a lot of visually-irrelevant information, effectively reducing the noise and encoding powerful visual representations for image reconstruction is also an open problem. We show that it is possible to overcome these challenges by learning a visually-relevant latent representation from fMRI signals guided by the corresponding visual features, and recovering the perceived images via adversarial learning. The resulting framework is called Dual-Variational Autoencoder/ Generative Adversarial Network (D-VAE/GAN). By using a novel 3-stage training strategy, it encodes both cognitive and visual features via a dual structure variational autoencoder (D-VAE) to adapt cognitive features to visual feature space, and then learns to reconstruct perceived images with generative adversarial network (GAN). Extensive experiments on three fMRI recording datasets show that D-VAE/GAN achieves more accurate visual reconstruction compared with the state-of-the-art methods.