 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
Step-DeepResearch Technical Report
Dec 24, 2025As LLMs shift toward autonomous agents, Deep Research has emerged as a pivotal metric. However, existing academic benchmarks like BrowseComp often fail to meet real-world demands for open-ended research, which requires robust skills in intent recognition, long-horizon decision-making, and cross-source verification. To address this, we introduce Step-DeepResearch, a cost-effective, end-to-end agent. We propose a Data Synthesis Strategy Based on Atomic Capabilities to reinforce planning and report writing, combined with a progressive training path from agentic mid-training to SFT and RL. Enhanced by a Checklist-style Judger, this approach significantly improves robustness. Furthermore, to bridge the evaluation gap in the Chinese domain, we establish ADR-Bench for realistic deep research scenarios. Experimental results show that Step-DeepResearch (32B) scores 61.4% on Scale AI Research Rubrics. On ADR-Bench, it significantly outperforms comparable models and rivals SOTA closed-source models like OpenAI and Gemini DeepResearch. These findings prove that refined training enables medium-sized models to achieve expert-level capabilities at industry-leading cost-efficiency.
Shrinking the Teacher: An Adaptive Teaching Paradigm for Asymmetric EEG-Vision Alignment
Nov 14, 2025Decoding visual features from EEG signals is a central challenge in neuroscience, with cross-modal alignment as the dominant approach. We argue that the relationship between visual and brain modalities is fundamentally asymmetric, characterized by two critical gaps: a Fidelity Gap (stemming from EEG's inherent noise and signal degradation, vs. vision's high-fidelity features) and a Semantic Gap (arising from EEG's shallow conceptual representation, vs. vision's rich semantic depth). Previous methods often overlook this asymmetry, forcing alignment between the two modalities as if they were equal partners and thereby leading to poor generalization. To address this, we propose the adaptive teaching paradigm. This paradigm empowers the ``teacher" modality (vision) to dynamically shrink and adjust its knowledge structure under task guidance, tailoring its semantically dense features to match the ``student" modality (EEG)'s capacity. We implement this paradigm with the ShrinkAdapter, a simple yet effective module featuring a residual-free design and a bottleneck structure. Through extensive experiments, we validate the underlying rationale and effectiveness of our paradigm. Our method achieves a top-1 accuracy of 60.2\% on the zero-shot brain-to-image retrieval task, surpassing previous state-of-the-art methods by a margin of 9.8\%. Our work introduces a new perspective for asymmetric alignment: the teacher must shrink and adapt to bridge the vision-brain gap.
MindSemantix: Deciphering Brain Visual Experiences with a Brain-Language Model
May 29, 2024Deciphering the human visual experience through brain activities captured by fMRI represents a compelling and cutting-edge challenge in the field of neuroscience research. Compared to merely predicting the viewed image itself, decoding brain activity into meaningful captions provides a higher-level interpretation and summarization of visual information, which naturally enhances the application flexibility in real-world situations. In this work, we introduce MindSemantix, a novel multi-modal framework that enables LLMs to comprehend visually-evoked semantic content in brain activity. Our MindSemantix explores a more ideal brain captioning paradigm by weaving LLMs into brain activity analysis, crafting a seamless, end-to-end Brain-Language Model. To effectively capture semantic information from brain responses, we propose Brain-Text Transformer, utilizing a Brain Q-Former as its core architecture. It integrates a pre-trained brain encoder with a frozen LLM to achieve multi-modal alignment of brain-vision-language and establish a robust brain-language correspondence. To enhance the generalizability of neural representations, we pre-train our brain encoder on a large-scale, cross-subject fMRI dataset using self-supervised learning techniques. MindSemantix provides more feasibility to downstream brain decoding tasks such as stimulus reconstruction. Conditioned by MindSemantix captioning, our framework facilitates this process by integrating with advanced generative models like Stable Diffusion and excels in understanding brain visual perception. MindSemantix generates high-quality captions that are deeply rooted in the visual and semantic information derived from brain activity. This approach has demonstrated substantial quantitative improvements over prior art. Our code will be released.
Reconstructing Perceived Images from Brain Activity by Visually-guided Cognitive Representation and Adversarial Learning
Jun 27, 2019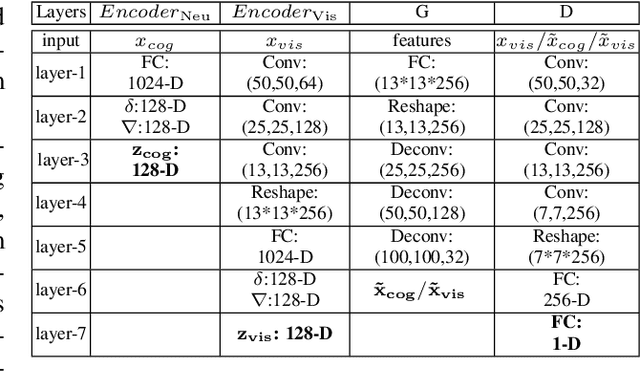
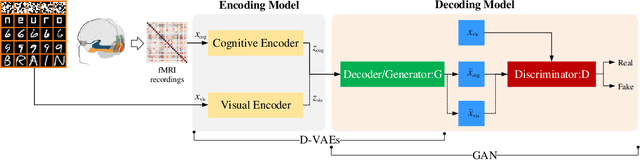
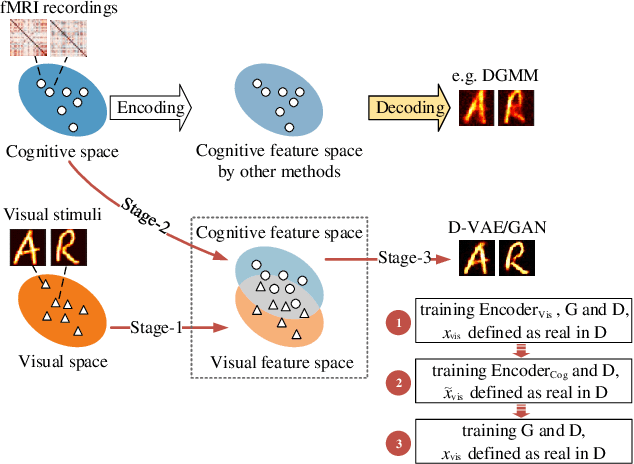
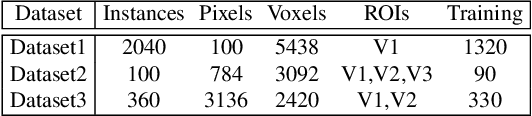
Reconstructing perceived images based on brain signals measured with functional magnetic resonance imaging (fMRI) is a significant and meaningful task in brain-driven computer vision. However, the inconsistent distribution and representation between fMRI signals and visual images cause the heterogeneity gap, which makes it challenging to learn a reliable mapping between them. Moreover, considering that fMRI signals are extremely high-dimensional and contain a lot of visually-irrelevant information, effectively reducing the noise and encoding powerful visual representations for image reconstruction is also an open problem. We show that it is possible to overcome these challenges by learning a visually-relevant latent representation from fMRI signals guided by the corresponding visual features, and recovering the perceived images via adversarial learning. The resulting framework is called Dual-Variational Autoencoder/ Generative Adversarial Network (D-VAE/GAN). By using a novel 3-stage training strategy, it encodes both cognitive and visual features via a dual structure variational autoencoder (D-VAE) to adapt cognitive features to visual feature space, and then learns to reconstruct perceived images with generative adversarial network (GAN). Extensive experiments on three fMRI recording datasets show that D-VAE/GAN achieves more accurate visual reconstruction compared with the state-of-the-art methods.