 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing Perceived Images from Brain Activity by Visually-guided Cognitive Representation and Adversarial Learning
Paper and Code
Jun 27, 2019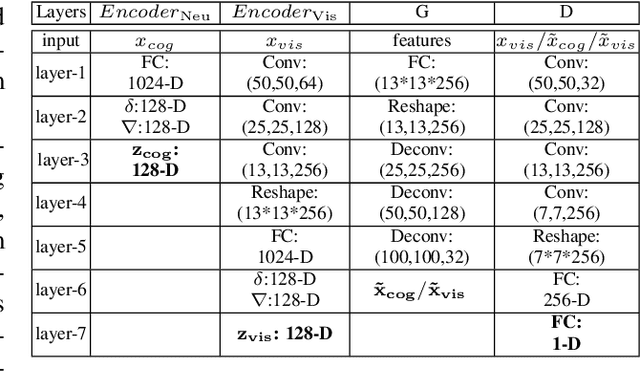
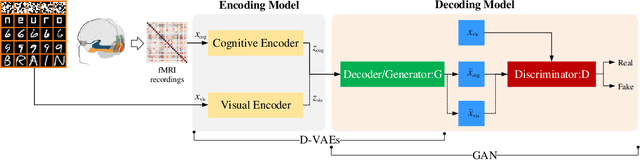
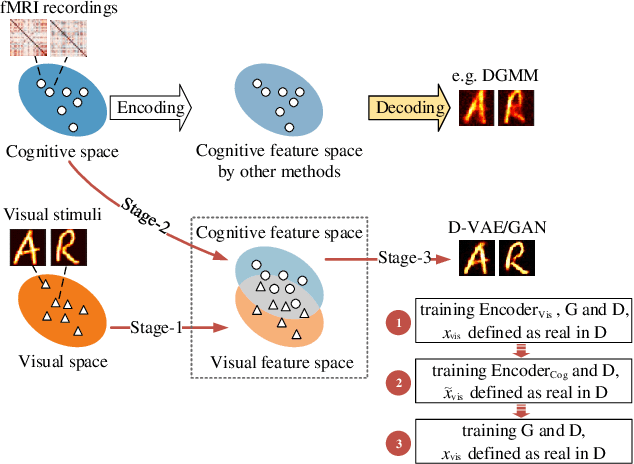
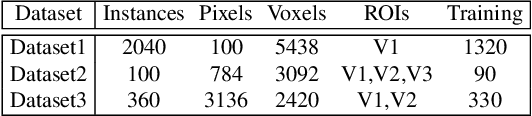
Reconstructing perceived images based on brain signals measured with functional magnetic resonance imaging (fMRI) is a significant and meaningful task in brain-driven computer vision. However, the inconsistent distribution and representation between fMRI signals and visual images cause the heterogeneity gap, which makes it challenging to learn a reliable mapping between them. Moreover, considering that fMRI signals are extremely high-dimensional and contain a lot of visually-irrelevant information, effectively reducing the noise and encoding powerful visual representations for image reconstruction is also an open problem. We show that it is possible to overcome these challenges by learning a visually-relevant latent representation from fMRI signals guided by the corresponding visual features, and recovering the perceived images via adversarial learning. The resulting framework is called Dual-Variational Autoencoder/ Generative Adversarial Network (D-VAE/GAN). By using a novel 3-stage training strategy, it encodes both cognitive and visual features via a dual structure variational autoencoder (D-VAE) to adapt cognitive features to visual feature space, and then learns to reconstruct perceived images with generative adversarial network (GAN). Extensive experiments on three fMRI recording datasets show that D-VAE/GAN achieves more accurate visual reconstruction compared with the state-of-the-art methods.