 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRangeLDM: Fast Realistic LiDAR Point Cloud Generation
Mar 15, 2024Autonomous driving demands high-quality LiDAR data, yet the cost of physical LiDAR sensors presents a significant scaling-up challenge. While recent efforts have explored deep generative models to address this issue, they often consume substantial computational resources with slow generation speeds while suffering from a lack of realism. To address these limitations, we introduce RangeLDM, a novel approach for rapidly generating high-quality range-view LiDAR point clouds via latent diffusion models. We achieve this by correcting range-view data distribution for accurate projection from point clouds to range images via Hough voting, which has a critical impact on generative learning. We then compress the range images into a latent space with a variational autoencoder, and leverage a diffusion model to enhance expressivity. Additionally, we instruct the model to preserve 3D structural fidelity by devising a range-guided discriminator. Experimental results on KITTI-360 and nuScenes datasets demonstrate both the robust expressiveness and fast speed of our LiDAR point cloud generation.
Density-Insensitive Unsupervised Domain Adaption on 3D Object Detection
Apr 19, 2023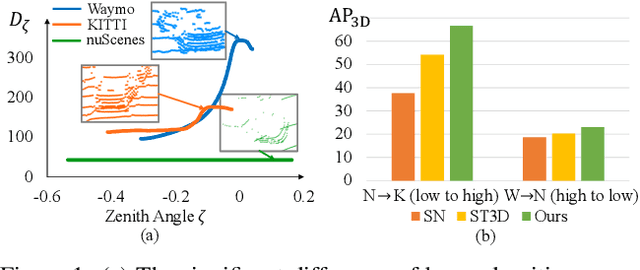



3D object detection from point clouds is crucial in safety-critical autonomous driving. Although many works have made great efforts and achieved significant progress on this task, most of them suffer from expensive annotation cost and poor transferability to unknown data due to the domain gap. Recently, few works attempt to tackle the domain gap in objects, but still fail to adapt to the gap of varying beam-densities between two domains, which is critical to mitigate the characteristic differences of the LiDAR collectors. To this end, we make the attempt to propose a density-insensitive domain adaption framework to address the density-induced domain gap. In particular, we first introduce Random Beam Re-Sampling (RBRS) to enhance the robustness of 3D detectors trained on the source domain to the varying beam-density. Then, we take this pre-trained detector as the backbone model, and feed the unlabeled target domain data into our newly designed task-specific teacher-student framework for predicting its high-quality pseudo labels. To further adapt the property of density-insensitivity into the target domain, we feed the teacher and student branches with the same sample of different densities, and propose an Object Graph Alignment (OGA) module to construct two object-graphs between the two branches for enforcing the consistency in both the attribute and relation of cross-density objects. Experimental results on three widely adopted 3D object detection datasets demonstrate that our proposed domain adaption method outperforms the state-of-the-art methods, especially over varying-density data. Code is available at https://github.com/WoodwindHu/DTS}{https://github.com/WoodwindHu/DTS.
Dynamic Point Cloud Denoising via Gradient Fields
Apr 19, 2022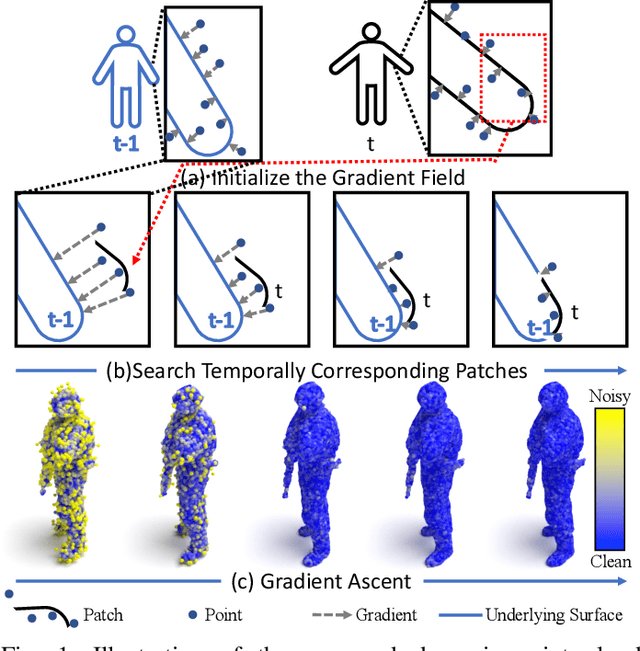


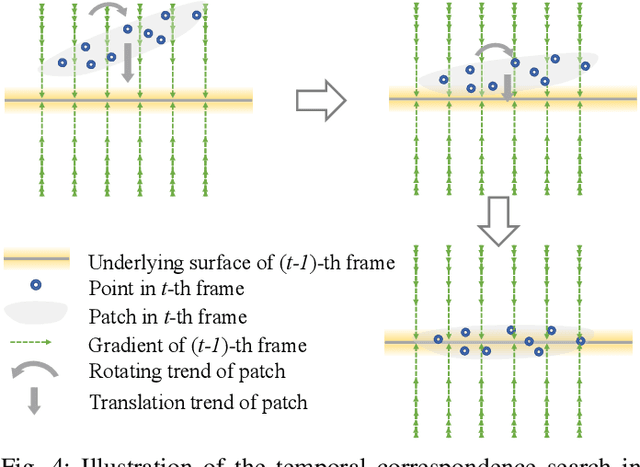
3D dynamic point clouds provide a discrete representation of real-world objects or scenes in motion, which have been widely applied in immersive telepresence, autonomous driving, surveillance, etc. However, point clouds acquired from sensors are usually perturbed by noise, which affects downstream tasks such as surface reconstruction and analysis. Although many efforts have been made for static point cloud denoising, dynamic point cloud denoising remains under-explored. In this paper, we propose a novel gradient-field-based dynamic point cloud denoising method, exploiting the temporal correspondence via the estimation of gradient fields -- a fundamental problem in dynamic point cloud processing and analysis. The gradient field is the gradient of the log-probability function of the noisy point cloud, based on which we perform gradient ascent so as to converge each point to the underlying clean surface. We estimate the gradient of each surface patch and exploit the temporal correspondence, where the temporally corresponding patches are searched leveraging on rigid motion in classical mechanics. In particular, we treat each patch as a rigid object, which moves in the gradient field of an adjacent frame via force until reaching a balanced state, i.e., when the sum of gradients over the patch reaches 0. Since the gradient would be smaller when the point is closer to the underlying surface, the balanced patch would fit the underlying surface well, thus leading to the temporal correspondence. Finally, the position of each point in the patch is updated along the direction of the gradient averaged from corresponding patches in adjacent frames. Experimental results demonstrate that the proposed model outperforms state-of-the-art methods under both synthetic noise and simulated real-world noise.
Exploring the Devil in Graph Spectral Domain for 3D Point Cloud Attacks
Feb 16, 2022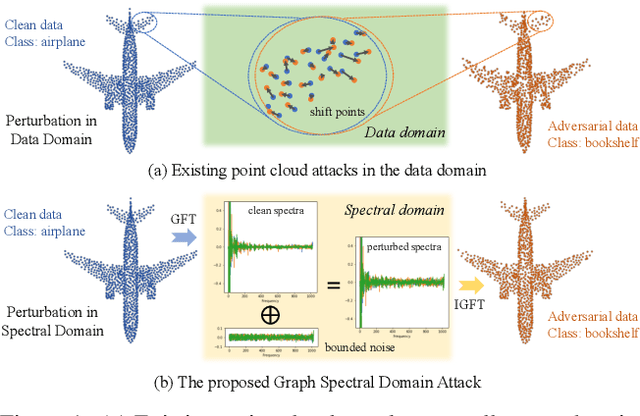
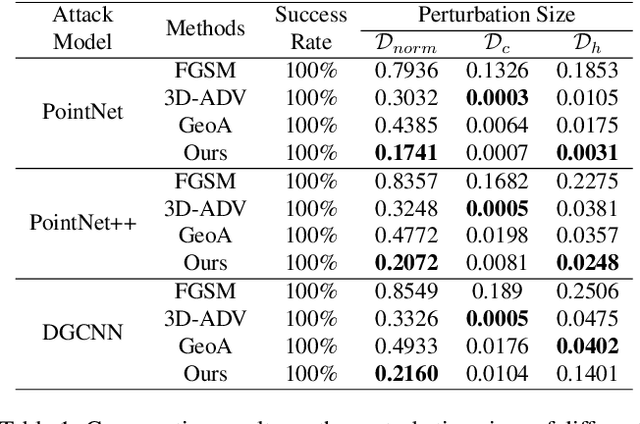
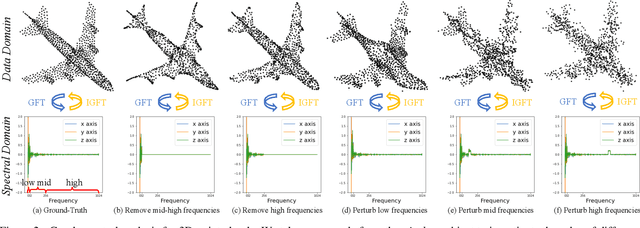
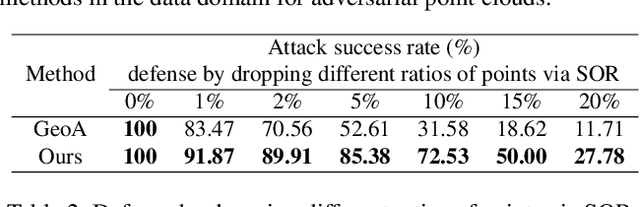
3D dynamic point clouds provide a discrete representation of real-world objects or scenes in motion, which have been widely applied in immersive telepresence, autonomous driving, surveillance, \textit{etc}. However, point clouds acquired from sensors are usually perturbed by noise, which affects downstream tasks such as surface reconstruction and analysis. Although many efforts have been made for static point cloud denoising, few works address dynamic point cloud denoising. In this paper, we propose a novel gradient-based dynamic point cloud denoising method, exploiting the temporal correspondence for the estimation of gradient fields -- also a fundamental problem in dynamic point cloud processing and analysis. The gradient field is the gradient of the log-probability function of the noisy point cloud, based on which we perform gradient ascent so as to converge each point to the underlying clean surface. We estimate the gradient of each surface patch by exploiting the temporal correspondence, where the temporally corresponding patches are searched leveraging on rigid motion in classical mechanics. In particular, we treat each patch as a rigid object, which moves in the gradient field of an adjacent frame via force until reaching a balanced state, i.e., when the sum of gradients over the patch reaches 0. Since the gradient would be smaller when the point is closer to the underlying surface, the balanced patch would fit the underlying surface well, thus leading to the temporal correspondence. Finally, the position of each point in the patch is updated along the direction of the gradient averaged from corresponding patches in adjacent frames. Experimental results demonstrate that the proposed model outperforms state-of-the-art methods.
AdCo: Adversarial Contrast for Efficient Learning of Unsupervised Representations from Self-Trained Negative Adversaries
Nov 23, 2020
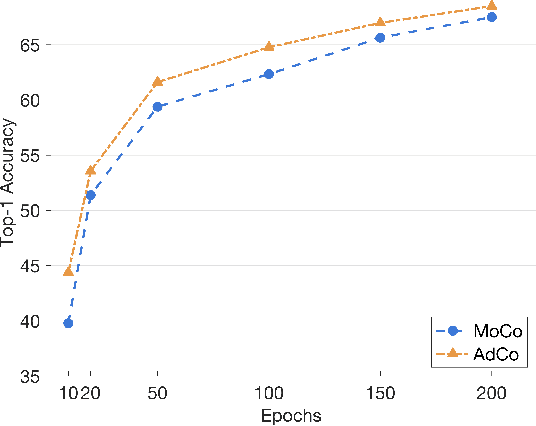
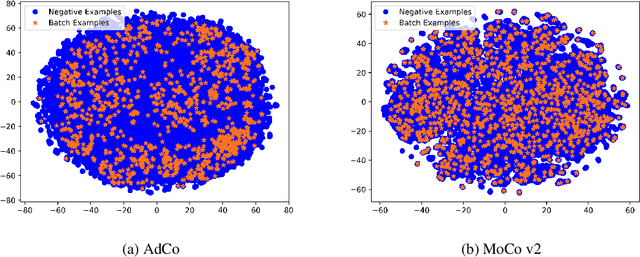
Contrastive learning relies on constructing a collection of negative examples that are sufficiently hard to discriminate against positive queries when their representations are self-trained. Existing contrastive learning methods either maintain a queue of negative samples over minibatches while only a small portion of them are updated in an iteration, or only use the other examples from the current minibatch as negatives. They could not closely track the change of the learned representation over iterations by updating the entire queue as a whole, or discard the useful information from the past minibatches. Alternatively, we present to directly learn a set of negative adversaries playing against the self-trained representation. Two players, the representation network and negative adversaries, are alternately updated to obtain the most challenging negative examples against which the representation of positive queries will be trained to discriminate. We further show that the negative adversaries are updated towards a weighted combination of positive queries by maximizing the adversarial contrastive loss, thereby allowing them to closely track the change of representations over time. Experiment results demonstrate the proposed Adversarial Contrastive (AdCo) model not only achieves superior performances with little computational overhead to the state-of-the-art contrast models, but also can be pretrained more rapidly with fewer epochs.
3D Dynamic Point Cloud Denoising via Spatial-Temporal Graph Learning
Apr 07, 2020

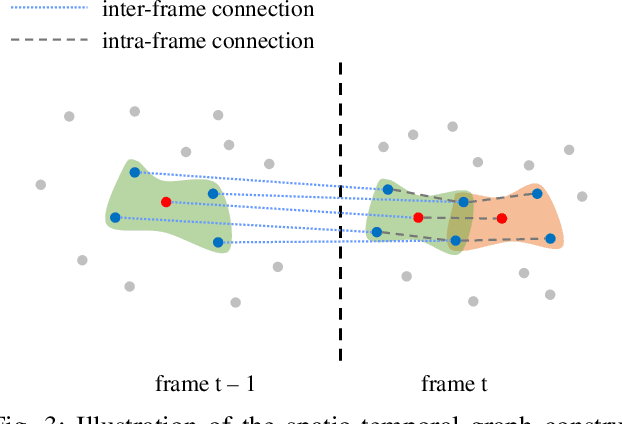
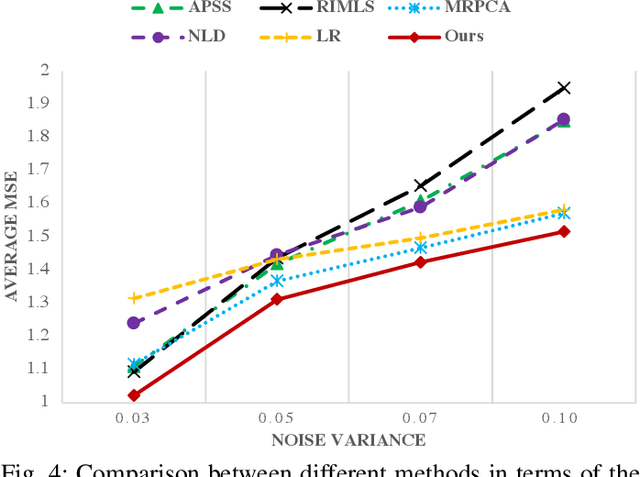
The prevalence of accessible depth sensing and 3D laser scanning techniques has enabled the convenient acquisition of 3D dynamic point clouds, which provide efficient representation of arbitrarily-shaped objects in motion. Nevertheless, dynamic point clouds are often perturbed by noise due to hardware, software or other causes. While a plethora of methods have been proposed for static point cloud denoising, few efforts are made for the denoising of dynamic point clouds with varying number of irregularly-sampled points in each frame. In this paper, we represent dynamic point clouds naturally on graphs and address the denoising problem by inferring the underlying graph via spatio-temporal graph learning, exploiting both the intra-frame similarity and inter-frame consistency. Firstly, assuming the availability of a relevant feature vector per node, we pose spatial-temporal graph learning as optimizing a Mahalanobis distance metric M, which is formulated as the minimization of graph Laplacian regularizer. Secondly, to ease the optimization of the symmetric and positive definite metric matrix M, we decompose it into M = R'*R and solve R instead via proximal gradient. Finally, based on the spatial-temporal graph learning, we formulate dynamic point cloud denoising as the joint optimization of the desired point cloud and underlying spatio-temporal graph, which leverages both intra-frame affinities and inter-frame consistency and is solved via alternating minimization. Experimental results show that the proposed method significantly outperforms independent denoising of each frame from state-of-the-art static point cloud denoising approaches.
3D Dynamic Point Cloud Denoising via Spatio-temporal Graph Modeling
Apr 28, 2019


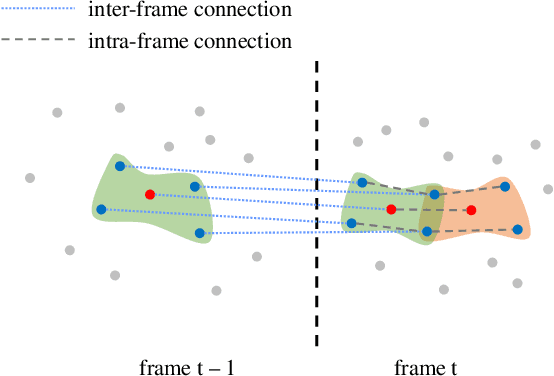
The prevalence of accessible depth sensing and 3D laser scanning techniques has enabled the convenient acquisition of 3D dynamic point clouds, which provide efficient representation of arbitrarily-shaped objects in motion. Nevertheless, dynamic point clouds are often perturbed by noise due to hardware, software or other causes. While many methods have been proposed for the denoising of static point clouds, dynamic point cloud denoising has not been studied in the literature yet. Hence, we address this problem based on the proposed spatio-temporal graph modeling, exploiting both the intra-frame similarity and inter-frame consistency. Specifically, we first represent a point cloud sequence on graphs and model it via spatio-temporal Gaussian Markov Random Fields on defined patches. Then for each target patch, we pose a Maximum a Posteriori estimation, and propose the corresponding likelihood and prior functions via spectral graph theory, leveraging its similar patches within the same frame and corresponding patch in the previous frame. This leads to our problem formulation, which jointly optimizes the underlying dynamic point cloud and spatio-temporal graph. Finally, we propose an efficient algorithm for patch construction, similar/corresponding patch search, intra- and inter-frame graph construction, and the optimization of our problem formulation via alternating minimization. Experimental results show that the proposed method outperforms frame-by-frame denoising from state-of-the-art static point cloud denoising approaches.