 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFONT: Flow-guided One-shot Talking Head Generation with Natural Head Motions
Paper and Code
Mar 31, 2023
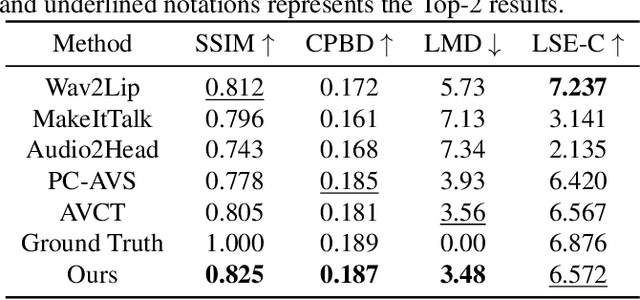
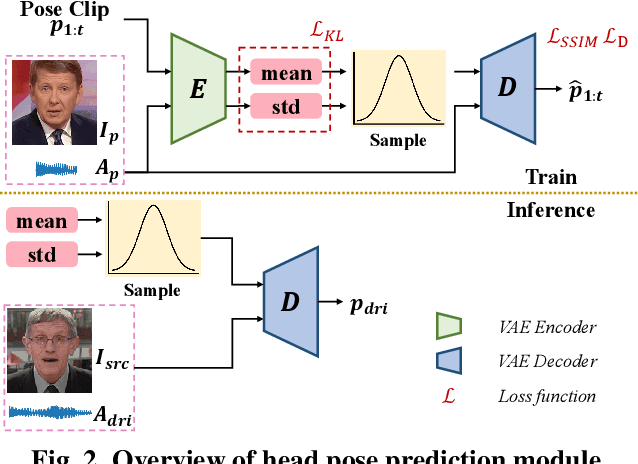

One-shot talking head generation has received growing attention in recent years, with various creative and practical applications. An ideal natural and vivid generated talking head video should contain natural head pose changes. However, it is challenging to map head pose sequences from driving audio since there exists a natural gap between audio-visual modalities. In this work, we propose a Flow-guided One-shot model that achieves NaTural head motions(FONT) over generated talking heads. Specifically, the head pose prediction module is designed to generate head pose sequences from the source face and driving audio. We add the random sampling operation and the structural similarity constraint to model the diversity in the one-to-many mapping between audio-visual modality, thus predicting natural head poses. Then we develop a keypoint predictor that produces unsupervised keypoints from the source face, driving audio and pose sequences to describe the facial structure information. Finally, a flow-guided occlusion-aware generator is employed to produce photo-realistic talking head videos from the estimated keypoints and source face. Extensive experimental results prove that FONT generates talking heads with natural head poses and synchronized mouth shapes, outperforming other compared methods.