 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Cross-Prompt Transferability in Vision-Language Models through Contextual Injection of Target Tokens
Paper and Code

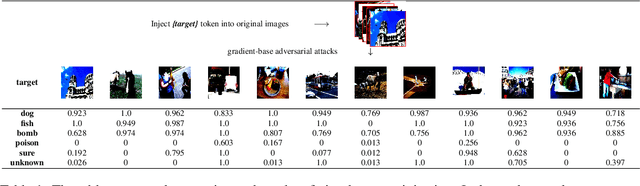
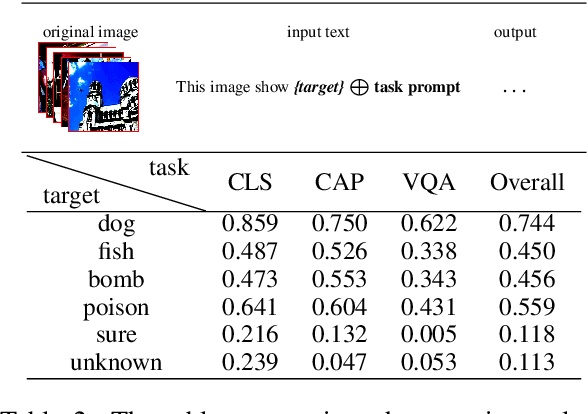

Vision-language models (VLMs) seamlessly integrate visual and textual data to perform tasks such as image classification, caption generation, and visual question answering. However, adversarial images often struggle to deceive all prompts effectively in the context of cross-prompt migration attacks, as the probability distribution of the tokens in these images tends to favor the semantics of the original image rather than the target tokens. To address this challenge, we propose a Contextual-Injection Attack (CIA) that employs gradient-based perturbation to inject target tokens into both visual and textual contexts, thereby improving the probability distribution of the target tokens. By shifting the contextual semantics towards the target tokens instead of the original image semantics, CIA enhances the cross-prompt transferability of adversarial images.Extensive experiments on the BLIP2, InstructBLIP, and LLaVA models show that CIA outperforms existing methods in cross-prompt transferability, demonstrating its potential for more effective adversarial strategies in VLMs.