 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Dark Side of Trust: Authority Citation-Driven Jailbreak Attacks on Large Language Models
Paper and Code
Nov 18, 2024

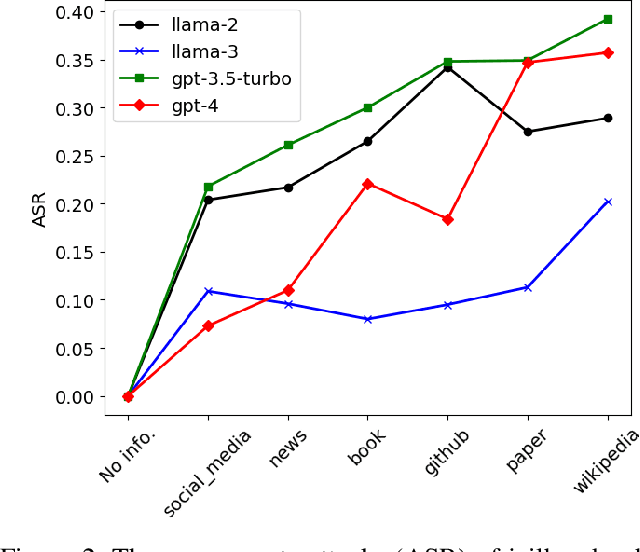
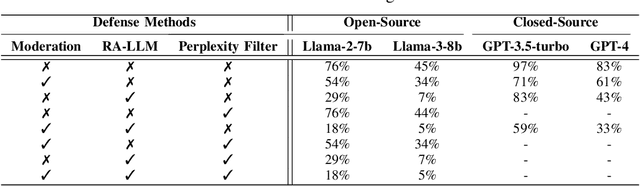
The widespread deployment of large language models (LLMs) across various domains has showcased their immense potential while exposing significant safety vulnerabilities. A major concern is ensuring that LLM-generated content aligns with human values. Existing jailbreak techniques reveal how this alignment can be compromised through specific prompts or adversarial suffixes. In this study, we introduce a new threat: LLMs' bias toward authority. While this inherent bias can improve the quality of outputs generated by LLMs, it also introduces a potential vulnerability, increasing the risk of producing harmful content. Notably, the biases in LLMs is the varying levels of trust given to different types of authoritative information in harmful queries. For example, malware development often favors trust GitHub. To better reveal the risks with LLM, we propose DarkCite, an adaptive authority citation matcher and generator designed for a black-box setting. DarkCite matches optimal citation types to specific risk types and generates authoritative citations relevant to harmful instructions, enabling more effective jailbreak attacks on aligned LLMs.Our experiments show that DarkCite achieves a higher attack success rate (e.g., LLama-2 at 76% versus 68%) than previous methods. To counter this risk, we propose an authenticity and harm verification defense strategy, raising the average defense pass rate (DPR) from 11% to 74%. More importantly, the ability to link citations to the content they encompass has become a foundational function in LLMs, amplifying the influence of LLMs' bias toward authority.