 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Supervision for Low-light Image Enhancement
Jan 11, 2025With the development of deep learning, numerous methods for low-light image enhancement (LLIE) have demonstrated remarkable performance. Mainstream LLIE methods typically learn an end-to-end mapping based on pairs of low-light and normal-light images. However, normal-light images under varying illumination conditions serve as reference images, making it difficult to define a ``perfect'' reference image This leads to the challenge of reconciling metric-oriented and visual-friendly results. Recently, many cross-modal studies have found that side information from other related modalities can guide visual representation learning. Based on this, we introduce a Natural Language Supervision (NLS) strategy, which learns feature maps from text corresponding to images, offering a general and flexible interface for describing an image under different illumination. However, image distributions conditioned on textual descriptions are highly multimodal, which makes training difficult. To address this issue, we design a Textual Guidance Conditioning Mechanism (TCM) that incorporates the connections between image regions and sentence words, enhancing the ability to capture fine-grained cross-modal cues for images and text. This strategy not only utilizes a wider range of supervised sources, but also provides a new paradigm for LLIE based on visual and textual feature alignment. In order to effectively identify and merge features from various levels of image and textual information, we design an Information Fusion Attention (IFA) module to enhance different regions at different levels. We integrate the proposed TCM and IFA into a Natural Language Supervision network for LLIE, named NaLSuper. Finally, extensive experiments demonstrate the robustness and superior effectiveness of our proposed NaLSuper.
Identification of 4FGL uncertain sources at Higher Resolutions with Inverse Discrete Wavelet Transform
Jan 05, 2024In the forthcoming era of big astronomical data, it is a burden to find out target sources from ground-based and space-based telescopes. Although Machine Learning (ML) methods have been extensively utilized to address this issue, the incorporation of in-depth data analysis can significantly enhance the efficiency of identifying target sources when dealing with massive volumes of astronomical data. In this work, we focused on the task of finding AGN candidates and identifying BL Lac/FSRQ candidates from the 4FGL DR3 uncertain sources. We studied the correlations among the attributes of the 4FGL DR3 catalogue and proposed a novel method, named FDIDWT, to transform the original data. The transformed dataset is characterized as low-dimensional and feature-highlighted, with the estimation of correlation features by Fractal Dimension (FD) theory and the multi-resolution analysis by Inverse Discrete Wavelet Transform (IDWT). Combining the FDIDWT method with an improved lightweight MatchboxConv1D model, we accomplished two missions: (1) to distinguish the Active Galactic Nuclei (AGNs) from others (Non-AGNs) in the 4FGL DR3 uncertain sources with an accuracy of 96.65%, namely, Mission A; (2) to classify blazar candidates of uncertain type (BCUs) into BL Lacertae objects (BL Lacs) or Flat Spectrum Radio Quasars (FSRQs) with an accuracy of 92.03%, namely, Mission B. There are 1354 AGN candidates in Mission A, 482 BL Lacs candidates and 128 FSRQ candidates in Mission B were found. The results show a high consistency of greater than 98% with the results in previous works. In addition, our method has the advantage of finding less variable and relatively faint sources than ordinary methods.
Unsupervised Low Light Image Enhancement Using SNR-Aware Swin Transformer
Jun 03, 2023



Image captured under low-light conditions presents unpleasing artifacts, which debilitate the performance of feature extraction for many upstream visual tasks. Low-light image enhancement aims at improving brightness and contrast, and further reducing noise that corrupts the visual quality. Recently, many image restoration methods based on Swin Transformer have been proposed and achieve impressive performance. However, On one hand, trivially employing Swin Transformer for low-light image enhancement would expose some artifacts, including over-exposure, brightness imbalance and noise corruption, etc. On the other hand, it is impractical to capture image pairs of low-light images and corresponding ground-truth, i.e. well-exposed image in same visual scene. In this paper, we propose a dual-branch network based on Swin Transformer, guided by a signal-to-noise ratio prior map which provides the spatial-varying information for low-light image enhancement. Moreover, we leverage unsupervised learning to construct the optimization objective based on Retinex model, to guide the training of proposed network. Experimental results demonstrate that the proposed model is competitive with the baseline models.
Time-aware Self-Attention Meets Logic Reasoning in Recommender Systems
Aug 29, 2022



At the age of big data, recommender systems have shown remarkable success as a key means of information filtering in our daily life. Recent years have witnessed the technical development of recommender systems, from perception learning to cognition reasoning which intuitively build the task of recommendation as the procedure of logical reasoning and have achieve significant improvement. However, the logical statement in reasoning implicitly admits irrelevance of ordering, even does not consider time information which plays an important role in many recommendation tasks. Furthermore, recommendation model incorporated with temporal context would tend to be self-attentive, i.e., automatically focus more (less) on the relevance (irrelevance), respectively. To address these issues, in this paper, we propose a Time-aware Self-Attention with Neural Collaborative Reasoning (TiSANCR) based recommendation model, which integrates temporal patterns and self-attention mechanism into reasoning-based recommendation. Specially, temporal patterns represented by relative time, provide context and auxiliary information to characterize the user's preference in recommendation, while self-attention is leveraged to distill informative patterns and suppress irrelevances. Therefore, the fusion of self-attentive temporal information provides deeper representation of user's preference. Extensive experiments on benchmark datasets demonstrate that the proposed TiSANCR achieves significant improvement and consistently outperforms the state-of-the-art recommendation methods.
A Deep Optimization Approach for Image Deconvolution
Apr 16, 2019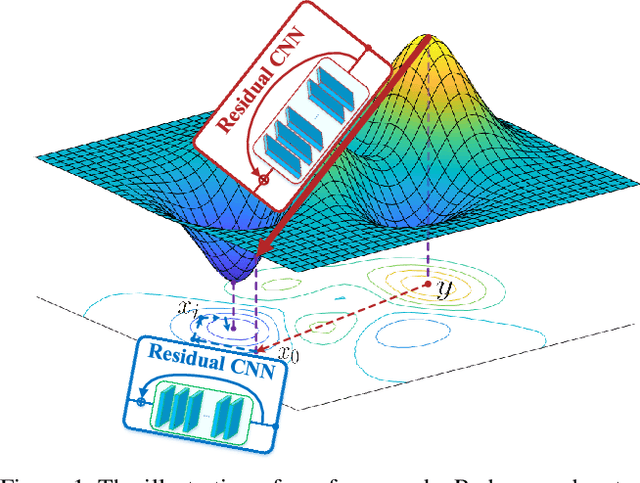
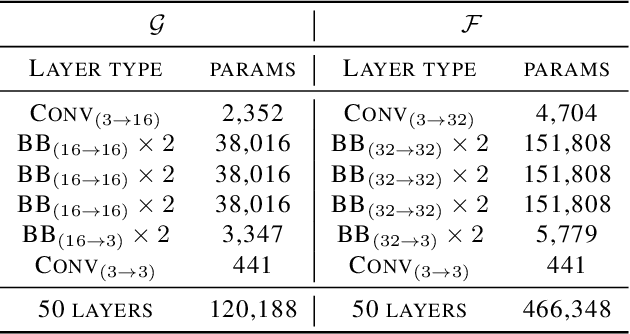

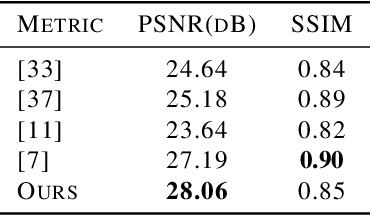
In blind image deconvolution, priors are often leveraged to constrain the solution space, so as to alleviate the under-determinacy. Priors which are trained separately from the task of deconvolution tend to be instable, or ineffective. We propose the Golf Optimizer, a novel but simple form of network that learns deep priors from data with better propagation behavior. Like playing golf, our method first estimates an aggressive propagation towards optimum using one network, and recurrently applies a residual CNN to learn the gradient of prior for delicate correction on restoration. Experiments show that our network achieves competitive performance on GoPro dataset, and our model is extremely lightweight compared with the state-of-art works.