 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Reinforcement Learning for Sample-Efficient Multiagent Coordination
Paper and Code
Jun 18, 2019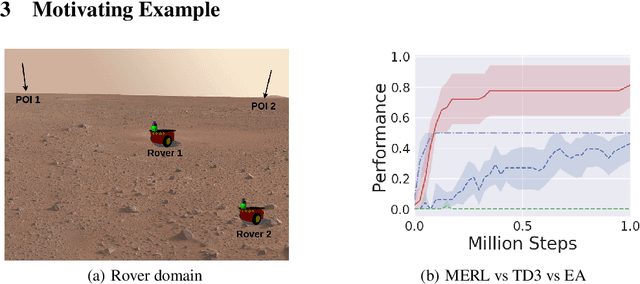

A key challenge for Multiagent RL (Reinforcement Learning) is the design of agent-specific, local rewards that are aligned with sparse global objectives. In this paper, we introduce MERL (Multiagent Evolutionary RL), a hybrid algorithm that does not require an explicit alignment between local and global objectives. MERL uses fast, policy-gradient based learning for each agent by utilizing their dense local rewards. Concurrently, an evolutionary algorithm is used to recruit agents into a team by directly optimizing the sparser global objective. We explore problems that require coupling (a minimum number of agents required to coordinate for success), where the degree of coupling is not known to the agents. We demonstrate that MERL's integrated approach is more sample-efficient and retains performance better with increasing coupling orders compared to MADDPG, the state-of-the-art policy-gradient algorithm for multiagent coordination.