 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning for Ordered Three-Dimensional Structures
Nov 22, 2024



Recent work has proven that training large language models with self-supervised tasks and fine-tuning these models to complete new tasks in a transfer learning setting is a powerful idea, enabling the creation of models with many parameters, even with little labeled data; however, the number of domains that have harnessed these advancements has been limited. In this work, we formulate a set of geometric tasks suitable for the large-scale study of ordered three-dimensional structures, without requiring any human intervention in data labeling. We build deep rotation- and permutation-equivariant neural networks based on geometric algebra and use them to solve these tasks on both idealized and simulated three-dimensional structures. Quantifying order in complex-structured assemblies remains a long-standing challenge in materials physics; these models can elucidate the behavior of real self-assembling systems in a variety of ways, from distilling insights from learned tasks without further modification to solving new tasks with smaller amounts of labeled data via transfer learning.
MatSciML: A Broad, Multi-Task Benchmark for Solid-State Materials Modeling
Sep 12, 2023



We propose MatSci ML, a novel benchmark for modeling MATerials SCIence using Machine Learning (MatSci ML) methods focused on solid-state materials with periodic crystal structures. Applying machine learning methods to solid-state materials is a nascent field with substantial fragmentation largely driven by the great variety of datasets used to develop machine learning models. This fragmentation makes comparing the performance and generalizability of different methods difficult, thereby hindering overall research progress in the field. Building on top of open-source datasets, including large-scale datasets like the OpenCatalyst, OQMD, NOMAD, the Carolina Materials Database, and Materials Project, the MatSci ML benchmark provides a diverse set of materials systems and properties data for model training and evaluation, including simulated energies, atomic forces, material bandgaps, as well as classification data for crystal symmetries via space groups. The diversity of properties in MatSci ML makes the implementation and evaluation of multi-task learning algorithms for solid-state materials possible, while the diversity of datasets facilitates the development of new, more generalized algorithms and methods across multiple datasets. In the multi-dataset learning setting, MatSci ML enables researchers to combine observations from multiple datasets to perform joint prediction of common properties, such as energy and forces. Using MatSci ML, we evaluate the performance of different graph neural networks and equivariant point cloud networks on several benchmark tasks spanning single task, multitask, and multi-data learning scenarios. Our open-source code is available at https://github.com/IntelLabs/matsciml.
The Open MatSci ML Toolkit: A Flexible Framework for Machine Learning in Materials Science
Oct 31, 2022



We present the Open MatSci ML Toolkit: a flexible, self-contained, and scalable Python-based framework to apply deep learning models and methods on scientific data with a specific focus on materials science and the OpenCatalyst Dataset. Our toolkit provides: 1. A scalable machine learning workflow for materials science leveraging PyTorch Lightning, which enables seamless scaling across different computation capabilities (laptop, server, cluster) and hardware platforms (CPU, GPU, XPU). 2. Deep Graph Library (DGL) support for rapid graph neural network prototyping and development. By publishing and sharing this toolkit with the research community via open-source release, we hope to: 1. Lower the entry barrier for new machine learning researchers and practitioners that want to get started with the OpenCatalyst dataset, which presently comprises the largest computational materials science dataset. 2. Enable the scientific community to apply advanced machine learning tools to high-impact scientific challenges, such as modeling of materials behavior for clean energy applications. We demonstrate the capabilities of our framework by enabling three new equivariant neural network models for multiple OpenCatalyst tasks and arrive at promising results for compute scaling and model performance.
Geometric Algebra Attention Networks for Small Point Clouds
Oct 05, 2021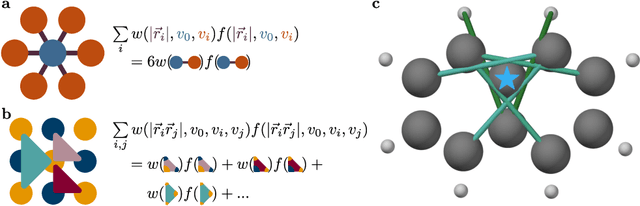

Much of the success of deep learning is drawn from building architectures that properly respect underlying symmetry and structure in the data on which they operate - a set of considerations that have been united under the banner of geometric deep learning. Often problems in the physical sciences deal with relatively small sets of points in two- or three-dimensional space wherein translation, rotation, and permutation equivariance are important or even vital for models to be useful in practice. In this work, we present rotation- and permutation-equivariant architectures for deep learning on these small point clouds, composed of a set of products of terms from the geometric algebra and reductions over those products using an attention mechanism. The geometric algebra provides valuable mathematical structure by which to combine vector, scalar, and other types of geometric inputs in a systematic way to account for rotation invariance or covariance, while attention yields a powerful way to impose permutation equivariance. We demonstrate the usefulness of these architectures by training models to solve sample problems relevant to physics, chemistry, and biology.
Agglomerative Attention
Jul 15, 2019

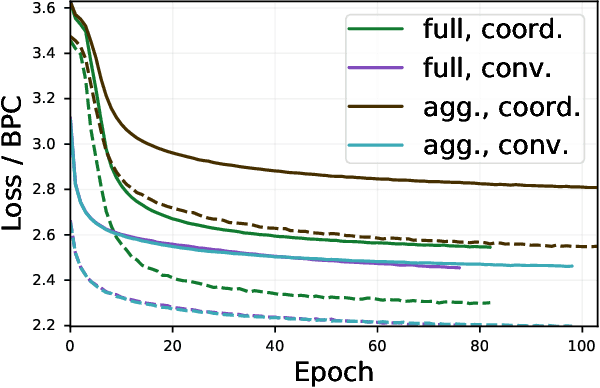

Neural networks using transformer-based architectures have recently demonstrated great power and flexibility in modeling sequences of many types. One of the core components of transformer networks is the attention layer, which allows contextual information to be exchanged among sequence elements. While many of the prevalent network structures thus far have utilized full attention -- which operates on all pairs of sequence elements -- the quadratic scaling of this attention mechanism significantly constrains the size of models that can be trained. In this work, we present an attention model that has only linear requirements in memory and computation time. We show that, despite the simpler attention model, networks using this attention mechanism can attain comparable performance to full attention networks on language modeling tasks.