 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Instance Segmentation by Grasping
May 10, 2023Instance segmentation is a fundamental skill for many robotic applications. We propose a self-supervised method that uses grasp interactions to collect segmentation supervision for an instance segmentation model. When a robot grasps an item, the mask of that grasped item can be inferred from the images of the scene before and after the grasp. Leveraging this insight, we learn a grasp segmentation model to segment the grasped object from before and after grasp images. Such a model can segment grasped objects from thousands of grasp interactions without costly human annotation. Using the segmented grasped objects, we can "cut" objects from their original scenes and "paste" them into new scenes to generate instance supervision. We show that our grasp segmentation model provides a 5x error reduction when segmenting grasped objects compared with traditional image subtraction approaches. Combined with our "cut-and-paste" generation method, instance segmentation models trained with our method achieve better performance than a model trained with 10x the amount of labeled data. On a real robotic grasping system, our instance segmentation model reduces the rate of grasp errors by over 3x compared to an image subtraction baseline.
Distributional Instance Segmentation: Modeling Uncertainty and High Confidence Predictions with Latent-MaskRCNN
May 03, 2023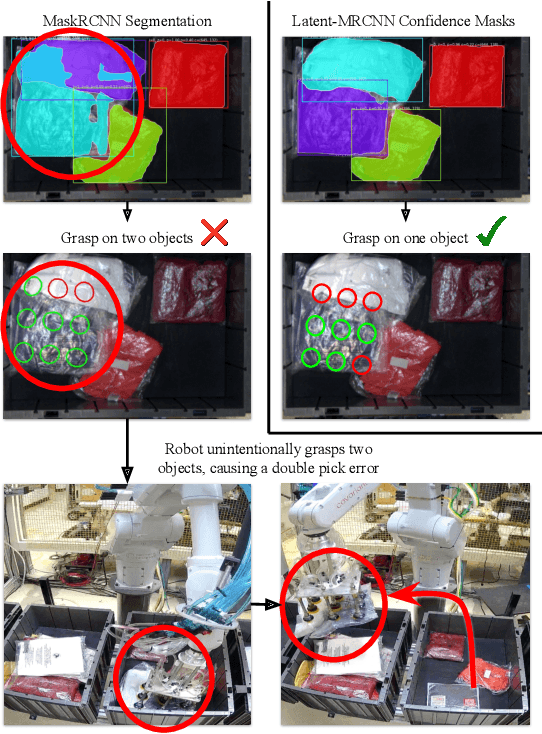

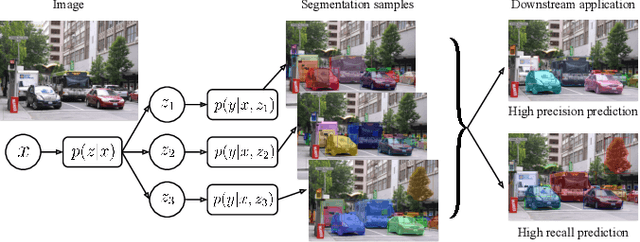
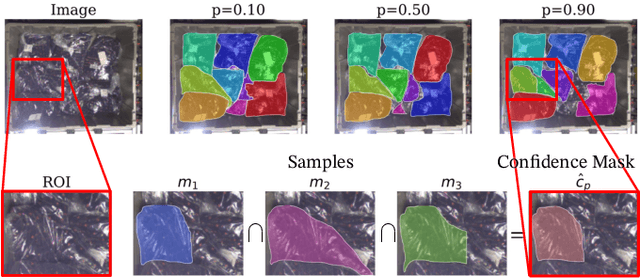
Object recognition and instance segmentation are fundamental skills in any robotic or autonomous system. Existing state-of-the-art methods are often unable to capture meaningful uncertainty in challenging or ambiguous scenes, and as such can cause critical errors in high-performance applications. In this paper, we explore a class of distributional instance segmentation models using latent codes that can model uncertainty over plausible hypotheses of object masks. For robotic picking applications, we propose a confidence mask method to achieve the high precision necessary in industrial use cases. We show that our method can significantly reduce critical errors in robotic systems, including our newly released dataset of ambiguous scenes in a robotic application. On a real-world apparel-picking robot, our method significantly reduces double pick errors while maintaining high performance.
Autoregressive Uncertainty Modeling for 3D Bounding Box Prediction
Oct 13, 2022
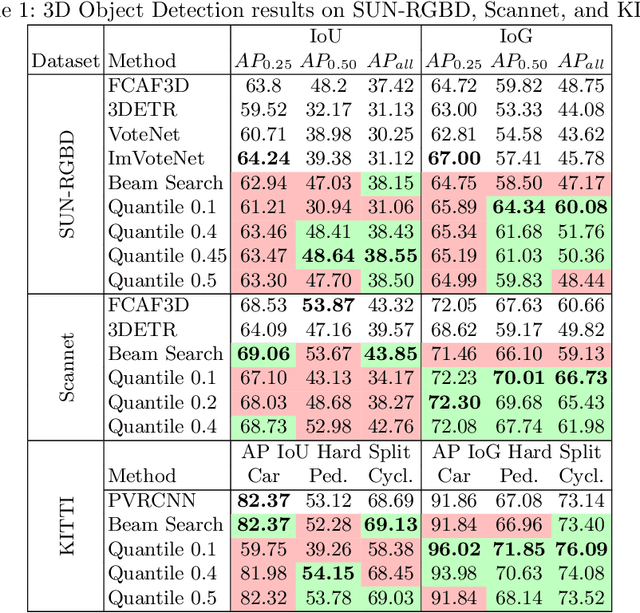
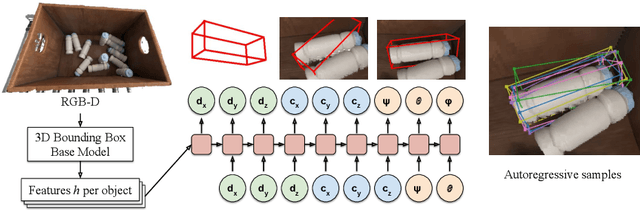
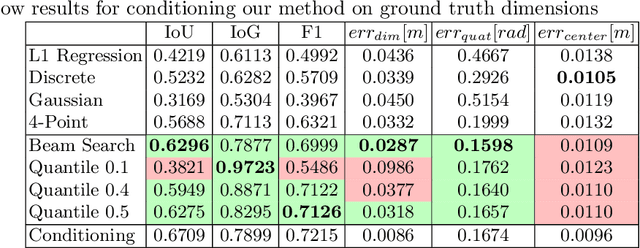
3D bounding boxes are a widespread intermediate representation in many computer vision applications. However, predicting them is a challenging task, largely due to partial observability, which motivates the need for a strong sense of uncertainty. While many recent methods have explored better architectures for consuming sparse and unstructured point cloud data, we hypothesize that there is room for improvement in the modeling of the output distribution and explore how this can be achieved using an autoregressive prediction head. Additionally, we release a simulated dataset, COB-3D, which highlights new types of ambiguity that arise in real-world robotics applications, where 3D bounding box prediction has largely been underexplored. We propose methods for leveraging our autoregressive model to make high confidence predictions and meaningful uncertainty measures, achieving strong results on SUN-RGBD, Scannet, KITTI, and our new dataset.
Imitation from Observation: Learning to Imitate Behaviors from Raw Video via Context Translation
Jun 18, 2018



Imitation learning is an effective approach for autonomous systems to acquire control policies when an explicit reward function is unavailable, using supervision provided as demonstrations from an expert, typically a human operator. However, standard imitation learning methods assume that the agent receives examples of observation-action tuples that could be provided, for instance, to a supervised learning algorithm. This stands in contrast to how humans and animals imitate: we observe another person performing some behavior and then figure out which actions will realize that behavior, compensating for changes in viewpoint, surroundings, object positions and types, and other factors. We term this kind of imitation learning "imitation-from-observation," and propose an imitation learning method based on video prediction with context translation and deep reinforcement learning. This lifts the assumption in imitation learning that the demonstration should consist of observations in the same environment configuration, and enables a variety of interesting applications, including learning robotic skills that involve tool use simply by observing videos of human tool use. Our experimental results show the effectiveness of our approach in learning a wide range of real-world robotic tasks modeled after common household chores from videos of a human demonstrator, including sweeping, ladling almonds, pushing objects as well as a number of tasks in simulation.
Self-Consistent Trajectory Autoencoder: Hierarchical Reinforcement Learning with Trajectory Embeddings
Jun 07, 2018
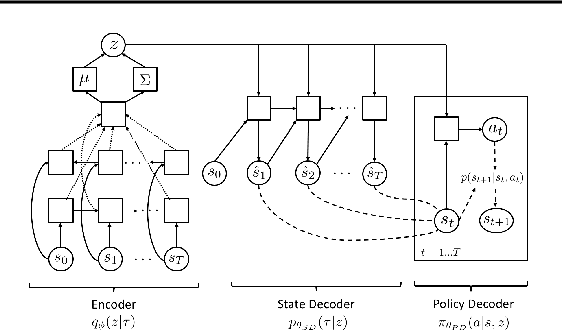

In this work, we take a representation learning perspective on hierarchical reinforcement learning, where the problem of learning lower layers in a hierarchy is transformed into the problem of learning trajectory-level generative models. We show that we can learn continuous latent representations of trajectories, which are effective in solving temporally extended and multi-stage problems. Our proposed model, SeCTAR, draws inspiration from variational autoencoders, and learns latent representations of trajectories. A key component of this method is to learn both a latent-conditioned policy and a latent-conditioned model which are consistent with each other. Given the same latent, the policy generates a trajectory which should match the trajectory predicted by the model. This model provides a built-in prediction mechanism, by predicting the outcome of closed loop policy behavior. We propose a novel algorithm for performing hierarchical RL with this model, combining model-based planning in the learned latent space with an unsupervised exploration objective. We show that our model is effective at reasoning over long horizons with sparse rewards for several simulated tasks, outperforming standard reinforcement learning methods and prior methods for hierarchical reasoning, model-based planning, and exploration.
Meta-Reinforcement Learning of Structured Exploration Strategies
Feb 20, 2018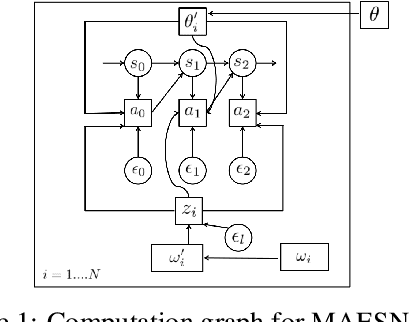

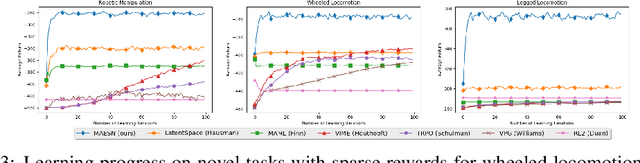

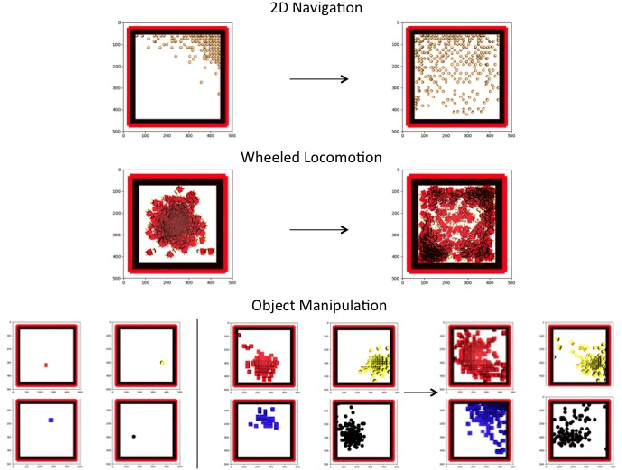
Exploration is a fundamental challenge in reinforcement learning (RL). Many of the current exploration methods for deep RL use task-agnostic objectives, such as information gain or bonuses based on state visitation. However, many practical applications of RL involve learning more than a single task, and prior tasks can be used to inform how exploration should be performed in new tasks. In this work, we explore how prior tasks can inform an agent about how to explore effectively in new situations. We introduce a novel gradient-based fast adaptation algorithm -- model agnostic exploration with structured noise (MAESN) -- to learn exploration strategies from prior experience. The prior experience is used both to initialize a policy and to acquire a latent exploration space that can inject structured stochasticity into a policy, producing exploration strategies that are informed by prior knowledge and are more effective than random action-space noise. We show that MAESN is more effective at learning exploration strategies when compared to prior meta-RL methods, RL without learned exploration strategies, and task-agnostic exploration methods. We evaluate our method on a variety of simulated tasks: locomotion with a wheeled robot, locomotion with a quadrupedal walker, and object manipulation.
Learning Invariant Feature Spaces to Transfer Skills with Reinforcement Learning
Mar 08, 2017



People can learn a wide range of tasks from their own experience, but can also learn from observing other creatures. This can accelerate acquisition of new skills even when the observed agent differs substantially from the learning agent in terms of morphology. In this paper, we examine how reinforcement learning algorithms can transfer knowledge between morphologically different agents (e.g., different robots). We introduce a problem formulation where two agents are tasked with learning multiple skills by sharing information. Our method uses the skills that were learned by both agents to train invariant feature spaces that can then be used to transfer other skills from one agent to another. The process of learning these invariant feature spaces can be viewed as a kind of "analogy making", or implicit learning of partial correspondences between two distinct domains. We evaluate our transfer learning algorithm in two simulated robotic manipulation skills, and illustrate that we can transfer knowledge between simulated robotic arms with different numbers of links, as well as simulated arms with different actuation mechanisms, where one robot is torque-driven while the other is tendon-driven.