 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Structured Visual Imitation
Paper and Code


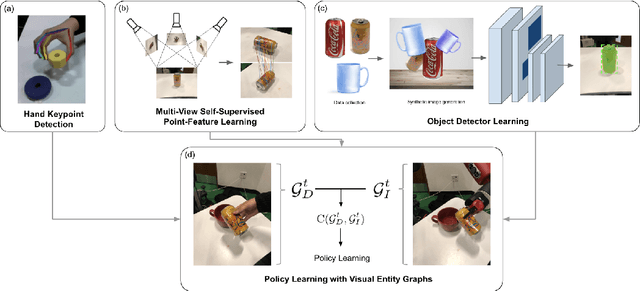
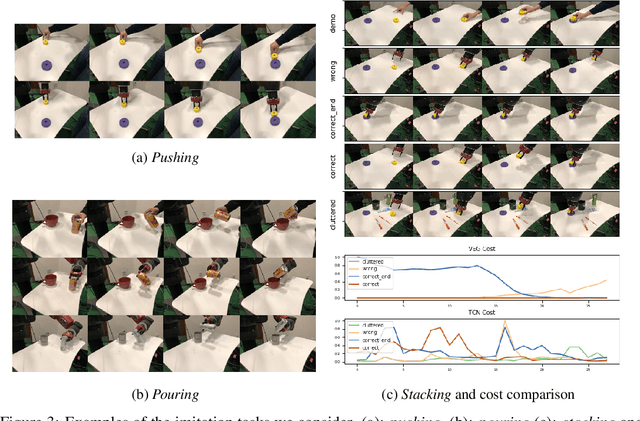
We cast visual imitation as a visual correspondence problem. Our robotic agent is rewarded when its actions result in better matching of relative spatial configurations for corresponding visual entities detected in its workspace and teacher's demonstration. We build upon recent advances in Computer Vision,such as human finger keypoint detectors, object detectors trained on-the-fly with synthetic augmentations, and point detectors supervised by viewpoint changes and learn multiple visual entity detectors for each demonstration without human annotations or robot interactions. We empirically show the proposed factorized visual representations of entities and their spatial arrangements drive successful imitation of a variety of manipulation skills within minutes, using a single demonstration and without any environment instrumentation. It is robust to background clutter and can effectively generalize across environment variations between demonstrator and imitator, greatly outperforming unstructured non-factorized full-frame CNN encodings of previous works.