 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust the Batch, On- or Off-Policy: Adaptive Policy Optimization for RL Post-Training
May 12, 2026Reinforcement learning is structurally harder than supervised learning because the policy changes the data distribution it learns from. The resulting fragility is especially visible in large-model training, where the training and rollout systems differ in numerical precision, sampling, and other implementation details. Existing methods manage this fragility by adding hyper-parameters to the training objective, which makes the algorithm more sensitive to its configuration and requires retuning whenever the task, model scale, or distribution mismatch changes. This fragility traces to two concerns that current objectives entangle through hyper-parameters set before training begins: a trust-region concern, that updates should not move the policy too far from its current value, and an off-policy concern, that data from older or different behavior policies should influence the update only to the extent that it remains reliable. Neither concern is a constant to set in advance, and their severity is reflected in the policy-ratio distribution of the current batch. We present a simple yet effective batch-adaptive objective that replaces fixed clipping with the normalized effective sample size of the policy ratios. The same statistic caps the score-function weight and sets the strength of an off-policy regularizer, so the update stays close to the usual on-policy score-function update when ratios are nearly uniform, and tightens automatically when stale or mismatched data cause ratio concentration, while retaining a nonzero learning signal on high-ratio tokens. Experiments across a wide range of settings show that our method matches or exceeds tuned baselines, introducing no new objective hyper-parameters and removing several existing ones. The code is available at https://github.com/FeynRL-project/FeynRL.
Data drift correction via time-varying importance weight estimator
Oct 04, 2022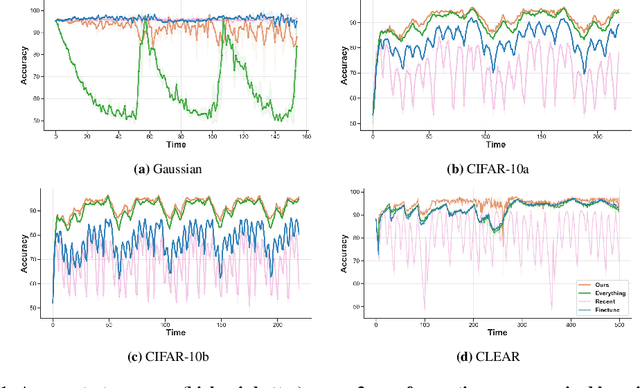

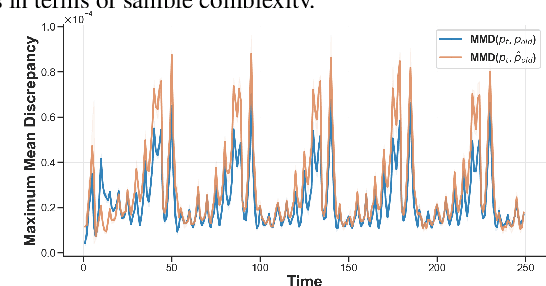
Real-world deployment of machine learning models is challenging when data evolves over time. And data does evolve over time. While no model can work when data evolves in an arbitrary fashion, if there is some pattern to these changes, we might be able to design methods to address it. This paper addresses situations when data evolves gradually. We introduce a novel time-varying importance weight estimator that can detect gradual shifts in the distribution of data. Such an importance weight estimator allows the training method to selectively sample past data -- not just similar data from the past like a standard importance weight estimator would but also data that evolved in a similar fashion in the past. Our time-varying importance weight is quite general. We demonstrate different ways of implementing it that exploit some known structure in the evolution of data. We demonstrate and evaluate this approach on a variety of problems ranging from supervised learning tasks (multiple image classification datasets) where the data undergoes a sequence of gradual shifts of our design to reinforcement learning tasks (robotic manipulation and continuous control) where data undergoes a shift organically as the policy or the task changes.
Deep Q-Network with Proximal Iteration
Dec 10, 2021

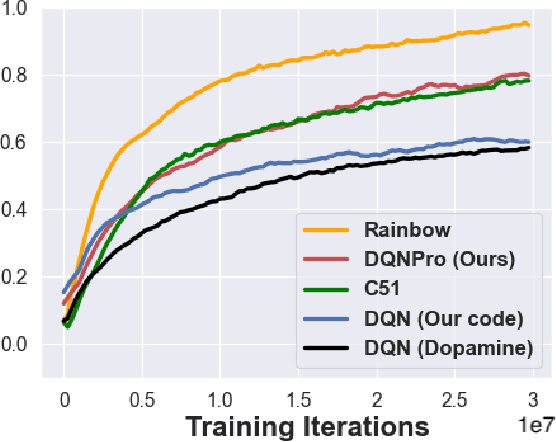

We employ Proximal Iteration for value-function optimization in reinforcement learning. Proximal Iteration is a computationally efficient technique that enables us to bias the optimization procedure towards more desirable solutions. As a concrete application of Proximal Iteration in deep reinforcement learning, we endow the objective function of the Deep Q-Network (DQN) agent with a proximal term to ensure that the online-network component of DQN remains in the vicinity of the target network. The resultant agent, which we call DQN with Proximal Iteration, or DQNPro, exhibits significant improvements over the original DQN on the Atari benchmark. Our results accentuate the power of employing sound optimization techniques for deep reinforcement learning.
Benchmarking Multimodal AutoML for Tabular Data with Text Fields
Nov 04, 2021
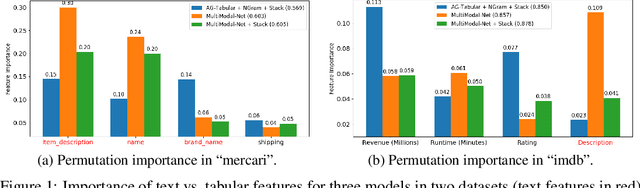
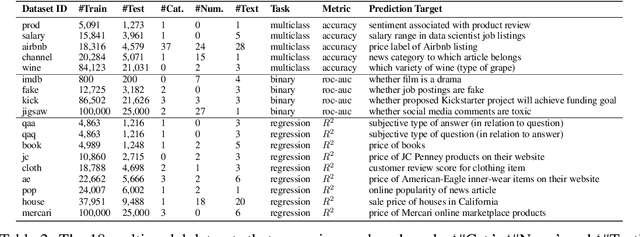
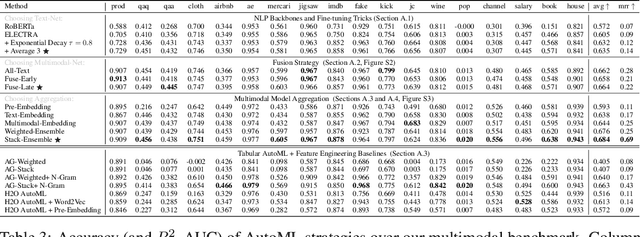
We consider the use of automated supervised learning systems for data tables that not only contain numeric/categorical columns, but one or more text fields as well. Here we assemble 18 multimodal data tables that each contain some text fields and stem from a real business application. Our publicly-available benchmark enables researchers to comprehensively evaluate their own methods for supervised learning with numeric, categorical, and text features. To ensure that any single modeling strategy which performs well over all 18 datasets will serve as a practical foundation for multimodal text/tabular AutoML, the diverse datasets in our benchmark vary greatly in: sample size, problem types (a mix of classification and regression tasks), number of features (with the number of text columns ranging from 1 to 28 between datasets), as well as how the predictive signal is decomposed between text vs. numeric/categorical features (and predictive interactions thereof). Over this benchmark, we evaluate various straightforward pipelines to model such data, including standard two-stage approaches where NLP is used to featurize the text such that AutoML for tabular data can then be applied. Compared with human data science teams, the fully automated methodology that performed best on our benchmark (stack ensembling a multimodal Transformer with various tree models) also manages to rank 1st place when fit to the raw text/tabular data in two MachineHack prediction competitions and 2nd place (out of 2380 teams) in Kaggle's Mercari Price Suggestion Challenge.
Deep Explicit Duration Switching Models for Time Series
Oct 26, 2021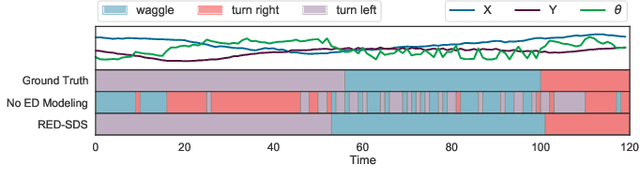
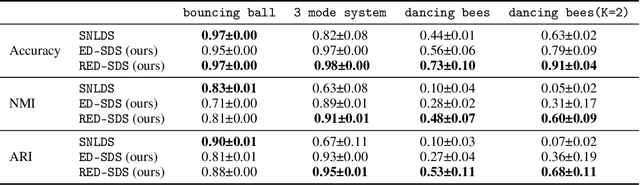
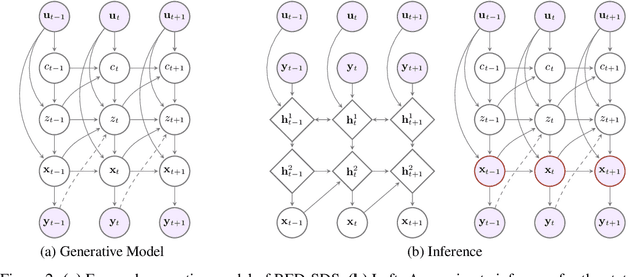
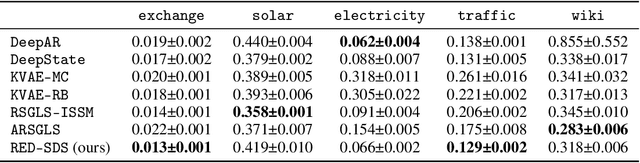
Many complex time series can be effectively subdivided into distinct regimes that exhibit persistent dynamics. Discovering the switching behavior and the statistical patterns in these regimes is important for understanding the underlying dynamical system. We propose the Recurrent Explicit Duration Switching Dynamical System (RED-SDS), a flexible model that is capable of identifying both state- and time-dependent switching dynamics. State-dependent switching is enabled by a recurrent state-to-switch connection and an explicit duration count variable is used to improve the time-dependent switching behavior. We demonstrate how to perform efficient inference using a hybrid algorithm that approximates the posterior of the continuous states via an inference network and performs exact inference for the discrete switches and counts. The model is trained by maximizing a Monte Carlo lower bound of the marginal log-likelihood that can be computed efficiently as a byproduct of the inference routine. Empirical results on multiple datasets demonstrate that RED-SDS achieves considerable improvement in time series segmentation and competitive forecasting performance against the state of the art.
Dive into Deep Learning
Jun 21, 2021
This open-source book represents our attempt to make deep learning approachable, teaching readers the concepts, the context, and the code. The entire book is drafted in Jupyter notebooks, seamlessly integrating exposition figures, math, and interactive examples with self-contained code. Our goal is to offer a resource that could (i) be freely available for everyone; (ii) offer sufficient technical depth to provide a starting point on the path to actually becoming an applied machine learning scientist; (iii) include runnable code, showing readers how to solve problems in practice; (iv) allow for rapid updates, both by us and also by the community at large; (v) be complemented by a forum for interactive discussion of technical details and to answer questions.
Deep Quantile Aggregation
Mar 16, 2021
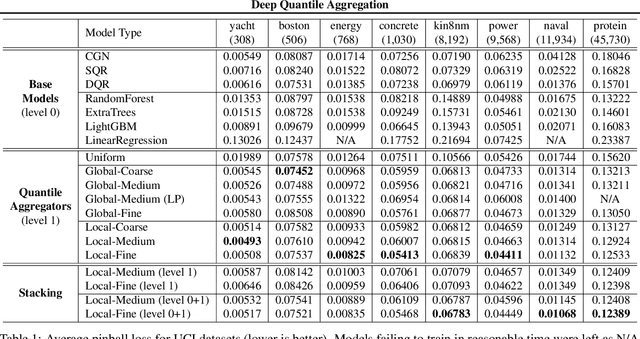
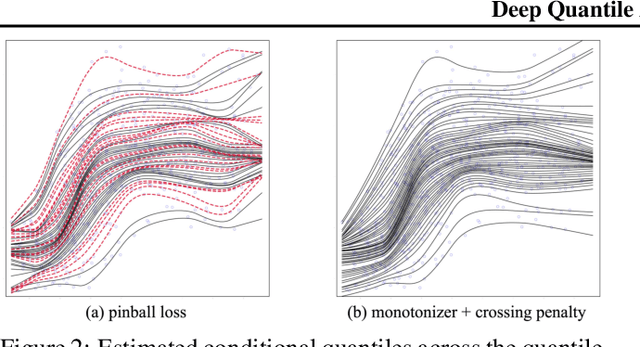
Conditional quantile estimation is a key statistical learning challenge motivated by the need to quantify uncertainty in predictions or to model a diverse population without being overly reductive. As such, many models have been developed for this problem. Adopting a meta viewpoint, we propose a general framework (inspired by neural network optimization) for aggregating any number of conditional quantile models in order to boost predictive accuracy. We consider weighted ensembling strategies of increasing flexibility where the weights may vary over individual models, quantile levels, and feature values. An appeal of our approach is its portability: we ensure that estimated quantiles at adjacent levels do not cross by applying simple transformations through which gradients can be backpropagated, and this allows us to leverage the modern deep learning toolkit for building quantile ensembles. Our experiments confirm that ensembling can lead to big gains in accuracy, even when the constituent models are themselves powerful and flexible.
Continuous Doubly Constrained Batch Reinforcement Learning
Feb 23, 2021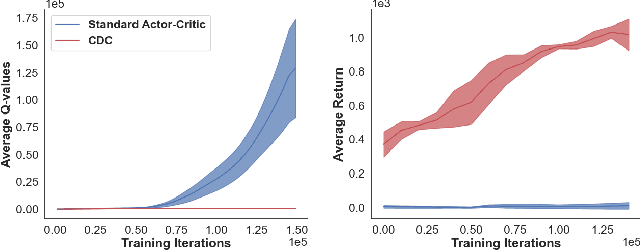


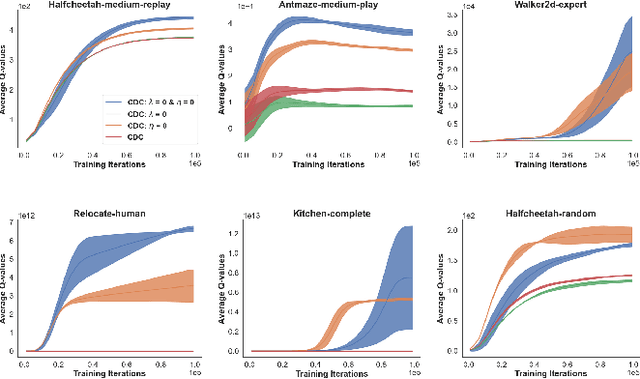
Reliant on too many experiments to learn good actions, current Reinforcement Learning (RL) algorithms have limited applicability in real-world settings, which can be too expensive to allow exploration. We propose an algorithm for batch RL, where effective policies are learned using only a fixed offline dataset instead of online interactions with the environment. The limited data in batch RL produces inherent uncertainty in value estimates of states/actions that were insufficiently represented in the training data. This leads to particularly severe extrapolation when our candidate policies diverge from one that generated the data. We propose to mitigate this issue via two straightforward penalties: a policy-constraint to reduce this divergence and a value-constraint that discourages overly optimistic estimates. Over a comprehensive set of 32 continuous-action batch RL benchmarks, our approach compares favorably to state-of-the-art methods, regardless of how the offline data were collected.
DDPG++: Striving for Simplicity in Continuous-control Off-Policy Reinforcement Learning
Jun 26, 2020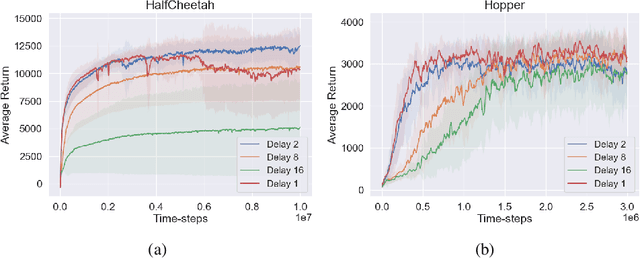
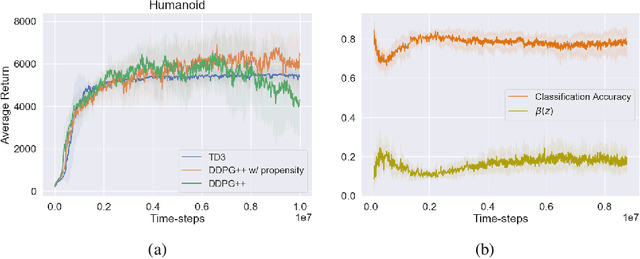
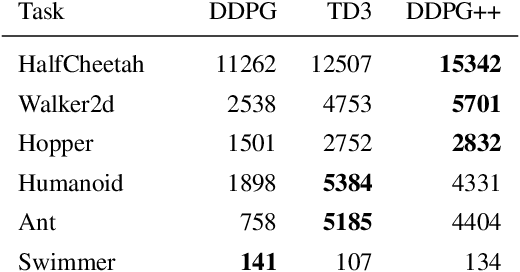
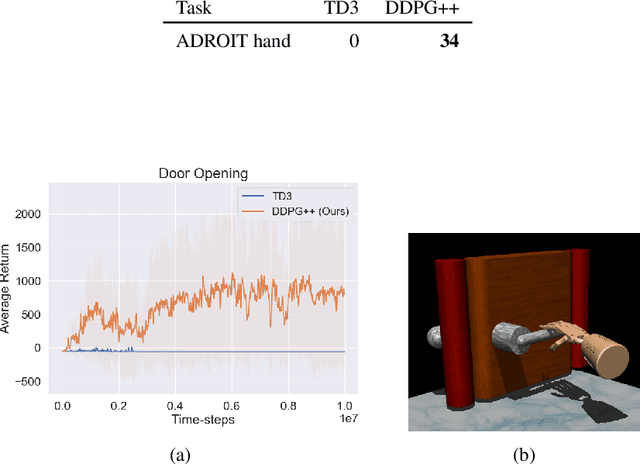
This paper prescribes a suite of techniques for off-policy Reinforcement Learning (RL) that simplify the training process and reduce the sample complexity. First, we show that simple Deterministic Policy Gradient works remarkably well as long as the overestimation bias is controlled. This is contrast to existing literature which creates sophisticated off-policy techniques. Second, we pinpoint training instabilities, typical of off-policy algorithms, to the greedy policy update step; existing solutions such as delayed policy updates do not mitigate this issue. Third, we show that ideas in the propensity estimation literature can be used to importance-sample transitions from the replay buffer and selectively update the policy to prevent deterioration of performance. We make these claims using extensive experimentation on a set of challenging MuJoCo tasks. A short video of our results can be seen at https://tinyurl.com/scs6p5m .
Fast, Accurate, and Simple Models for Tabular Data via Augmented Distillation
Jun 25, 2020


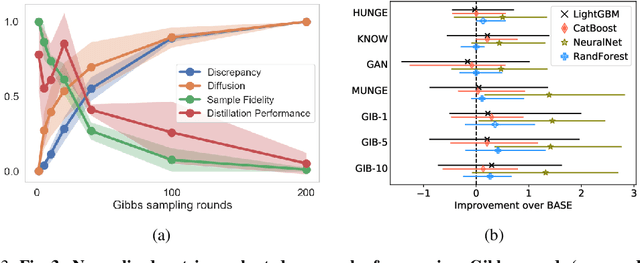
Automated machine learning (AutoML) can produce complex model ensembles by stacking, bagging, and boosting many individual models like trees, deep networks, and nearest neighbor estimators. While highly accurate, the resulting predictors are large, slow, and opaque as compared to their constituents. To improve the deployment of AutoML on tabular data, we propose FAST-DAD to distill arbitrarily complex ensemble predictors into individual models like boosted trees, random forests, and deep networks. At the heart of our approach is a data augmentation strategy based on Gibbs sampling from a self-attention pseudolikelihood estimator. Across 30 datasets spanning regression and binary/multiclass classification tasks, FAST-DAD distillation produces significantly better individual models than one obtains through standard training on the original data. Our individual distilled models are over 10x faster and more accurate than ensemble predictors produced by AutoML tools like H2O/AutoSklearn.