 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDDPG++: Striving for Simplicity in Continuous-control Off-Policy Reinforcement Learning
Paper and Code
Jun 26, 2020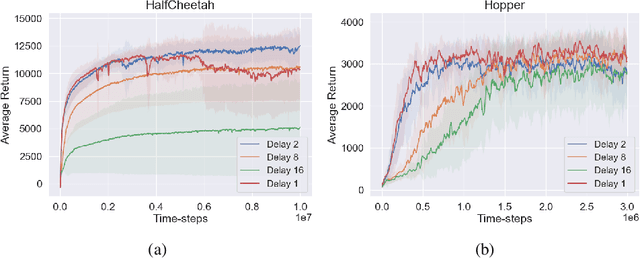
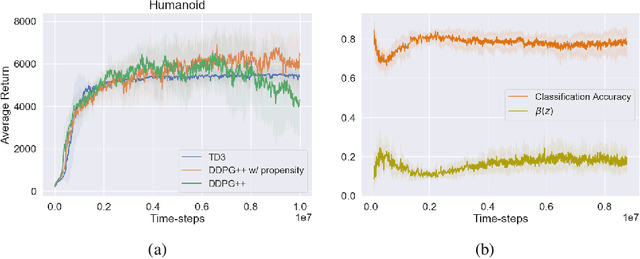
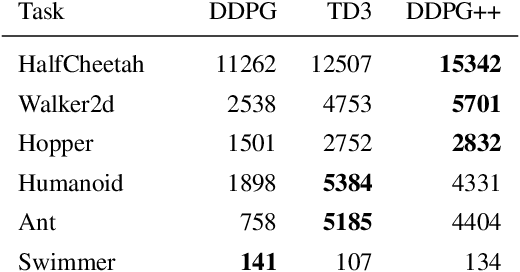
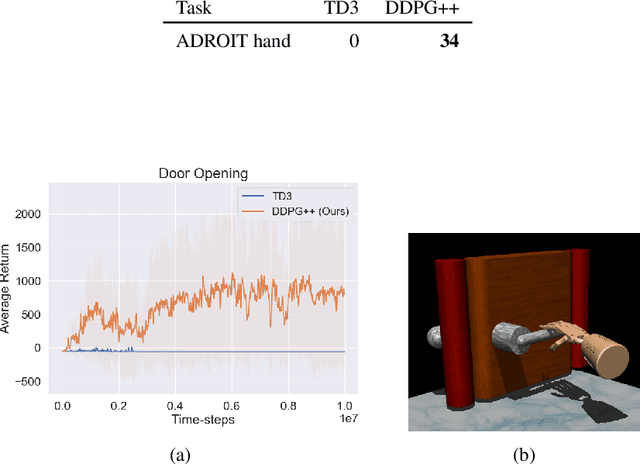
This paper prescribes a suite of techniques for off-policy Reinforcement Learning (RL) that simplify the training process and reduce the sample complexity. First, we show that simple Deterministic Policy Gradient works remarkably well as long as the overestimation bias is controlled. This is contrast to existing literature which creates sophisticated off-policy techniques. Second, we pinpoint training instabilities, typical of off-policy algorithms, to the greedy policy update step; existing solutions such as delayed policy updates do not mitigate this issue. Third, we show that ideas in the propensity estimation literature can be used to importance-sample transitions from the replay buffer and selectively update the policy to prevent deterioration of performance. We make these claims using extensive experimentation on a set of challenging MuJoCo tasks. A short video of our results can be seen at https://tinyurl.com/scs6p5m .