 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Q-Network with Proximal Iteration
Paper and Code
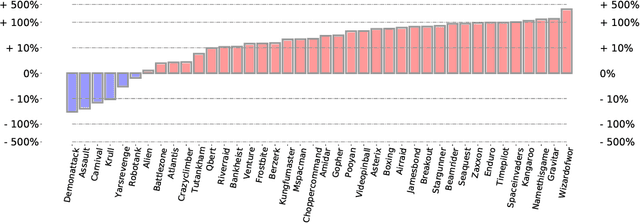

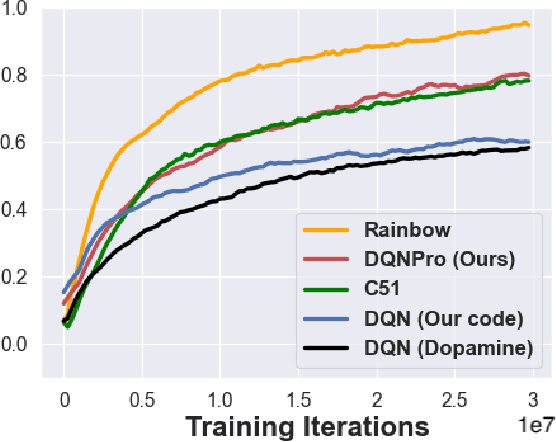

We employ Proximal Iteration for value-function optimization in reinforcement learning. Proximal Iteration is a computationally efficient technique that enables us to bias the optimization procedure towards more desirable solutions. As a concrete application of Proximal Iteration in deep reinforcement learning, we endow the objective function of the Deep Q-Network (DQN) agent with a proximal term to ensure that the online-network component of DQN remains in the vicinity of the target network. The resultant agent, which we call DQN with Proximal Iteration, or DQNPro, exhibits significant improvements over the original DQN on the Atari benchmark. Our results accentuate the power of employing sound optimization techniques for deep reinforcement learning.