 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Few-Shot Learning via Language Model Retrieval
Jun 19, 2023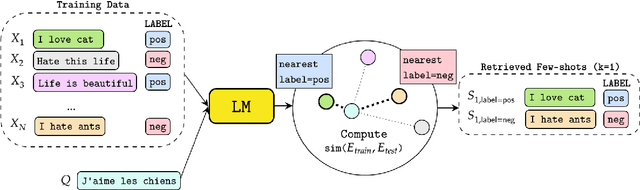
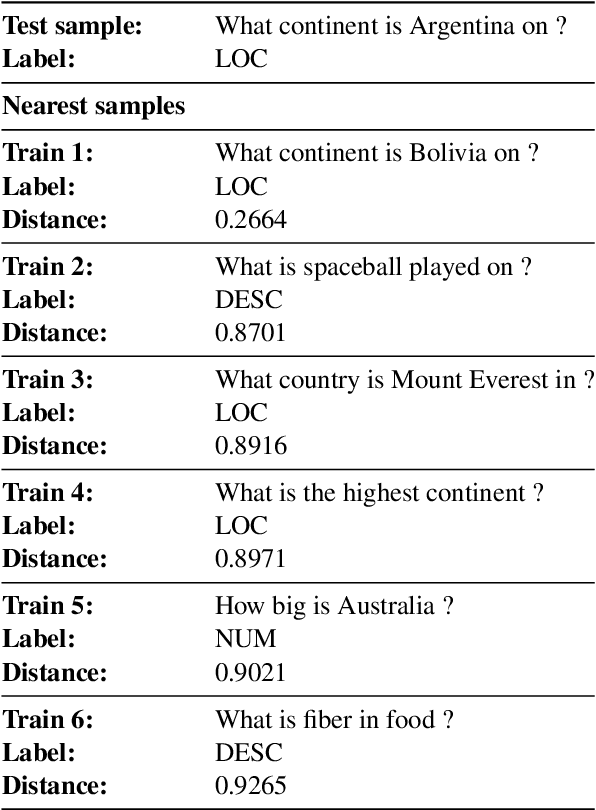
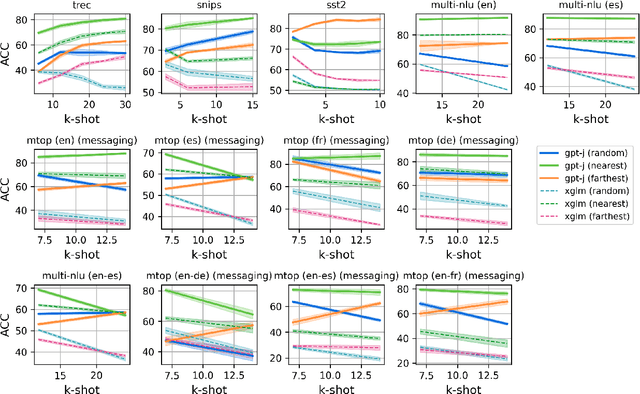
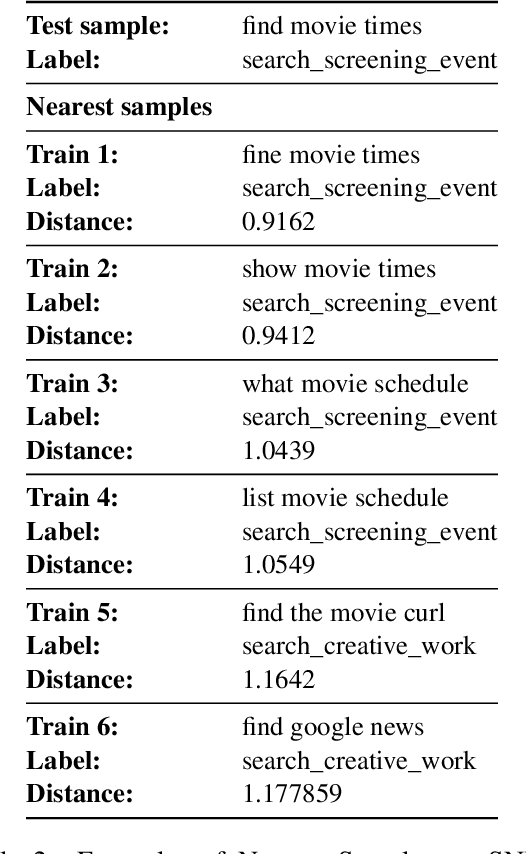
Transformer-based language models have achieved remarkable success in few-shot in-context learning and drawn a lot of research interest. However, these models' performance greatly depends on the choice of the example prompts and also has high variability depending on how samples are chosen. In this paper, we conduct a comprehensive study of retrieving semantically similar few-shot samples and using them as the context, as it helps the model decide the correct label without any gradient update in the multilingual and cross-lingual settings. We evaluate the proposed method on five natural language understanding datasets related to intent detection, question classification, sentiment analysis, and topic classification. The proposed method consistently outperforms random sampling in monolingual and cross-lingual tasks in non-English languages.
Reward Learning from Narrated Demonstrations
Apr 27, 2018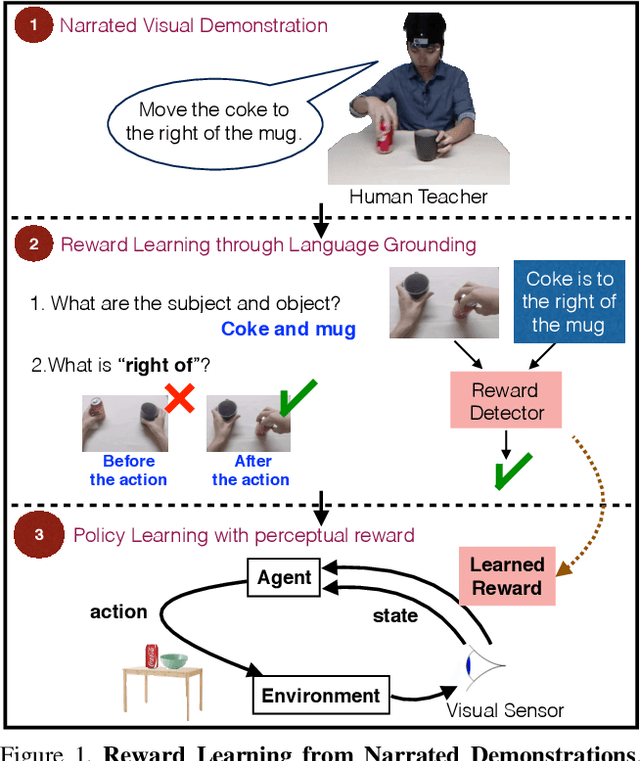
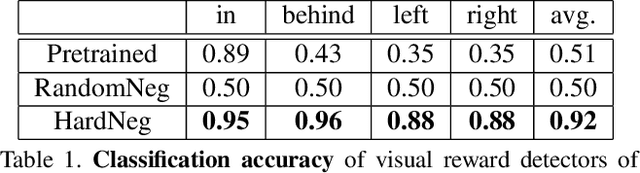

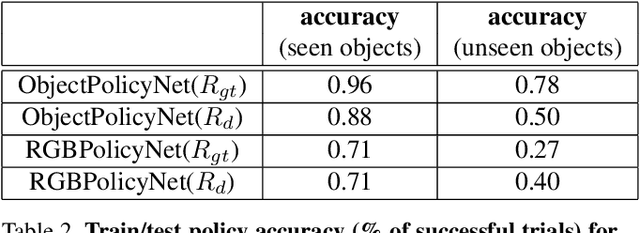
Humans effortlessly "program" one another by communicating goals and desires in natural language. In contrast, humans program robotic behaviours by indicating desired object locations and poses to be achieved, by providing RGB images of goal configurations, or supplying a demonstration to be imitated. None of these methods generalize across environment variations, and they convey the goal in awkward technical terms. This work proposes joint learning of natural language grounding and instructable behavioural policies reinforced by perceptual detectors of natural language expressions, grounded to the sensory inputs of the robotic agent. Our supervision is narrated visual demonstrations(NVD), which are visual demonstrations paired with verbal narration (as opposed to being silent). We introduce a dataset of NVD where teachers perform activities while describing them in detail. We map the teachers' descriptions to perceptual reward detectors, and use them to train corresponding behavioural policies in simulation.We empirically show that our instructable agents (i) learn visual reward detectors using a small number of examples by exploiting hard negative mined configurations from demonstration dynamics, (ii) develop pick-and place policies using learned visual reward detectors, (iii) benefit from object-factorized state representations that mimic the syntactic structure of natural language goal expressions, and (iv) can execute behaviours that involve novel objects in novel locations at test time, instructed by natural language.
Learning Robust Visual-Semantic Embeddings
Mar 20, 2017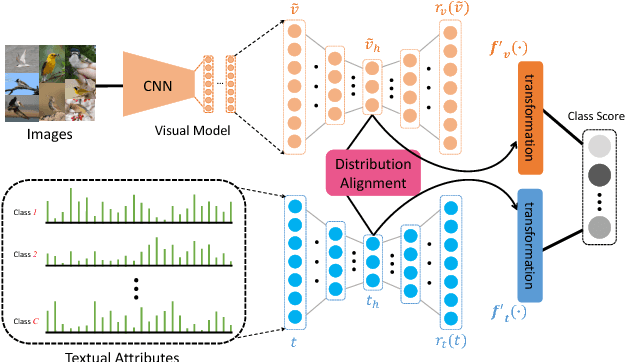
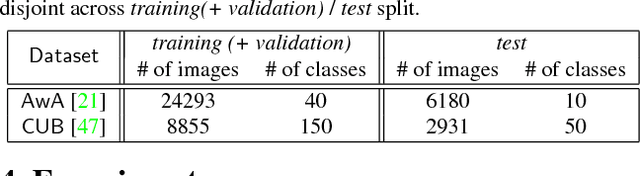
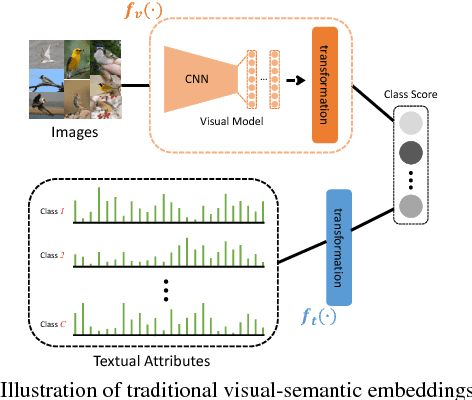
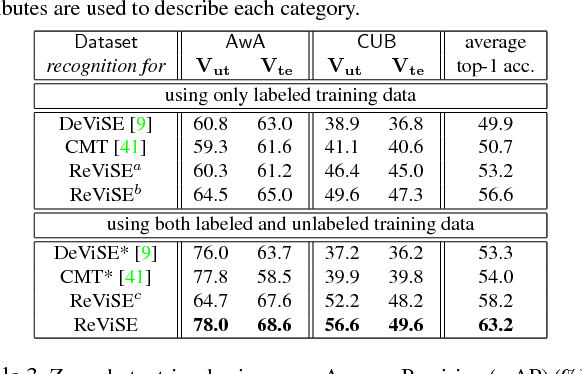
Many of the existing methods for learning joint embedding of images and text use only supervised information from paired images and its textual attributes. Taking advantage of the recent success of unsupervised learning in deep neural networks, we propose an end-to-end learning framework that is able to extract more robust multi-modal representations across domains. The proposed method combines representation learning models (i.e., auto-encoders) together with cross-domain learning criteria (i.e., Maximum Mean Discrepancy loss) to learn joint embeddings for semantic and visual features. A novel technique of unsupervised-data adaptation inference is introduced to construct more comprehensive embeddings for both labeled and unlabeled data. We evaluate our method on Animals with Attributes and Caltech-UCSD Birds 200-2011 dataset with a wide range of applications, including zero and few-shot image recognition and retrieval, from inductive to transductive settings. Empirically, we show that our framework improves over the current state of the art on many of the considered tasks.