 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning of Active Vision for Manipulating Objects under Occlusions
Feb 16, 2019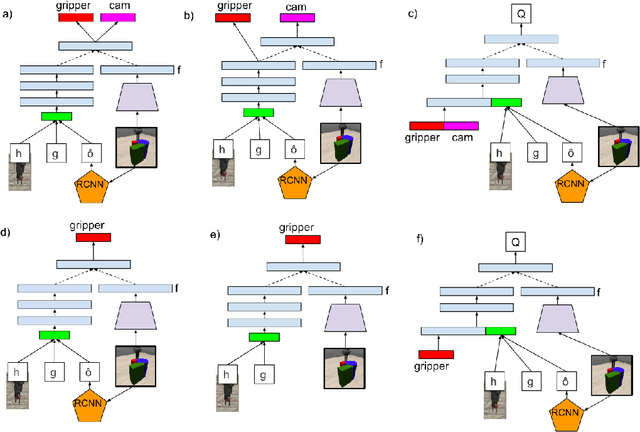


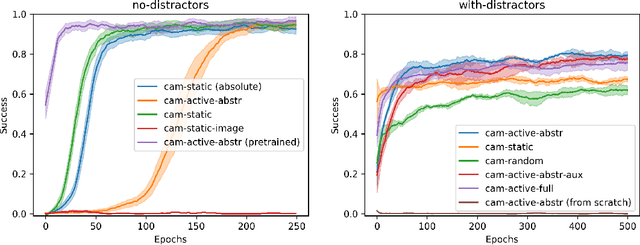
We consider artificial agents that learn to jointly control their gripperand camera in order to reinforcement learn manipulation policies in the presenceof occlusions from distractor objects. Distractors often occlude the object of in-terest and cause it to disappear from the field of view. We propose hand/eye con-trollers that learn to move the camera to keep the object within the field of viewand visible, in coordination to manipulating it to achieve the desired goal, e.g.,pushing it to a target location. We incorporate structural biases of object-centricattention within our actor-critic architectures, which our experiments suggest tobe a key for good performance. Our results further highlight the importance ofcurriculum with regards to environment difficulty. The resulting active vision /manipulation policies outperform static camera setups for a variety of clutteredenvironments.
* The paper was present in Conference of Robot Learning 2018
Learning Spatial Common Sense with Geometry-Aware Recurrent Networks
Dec 31, 2018

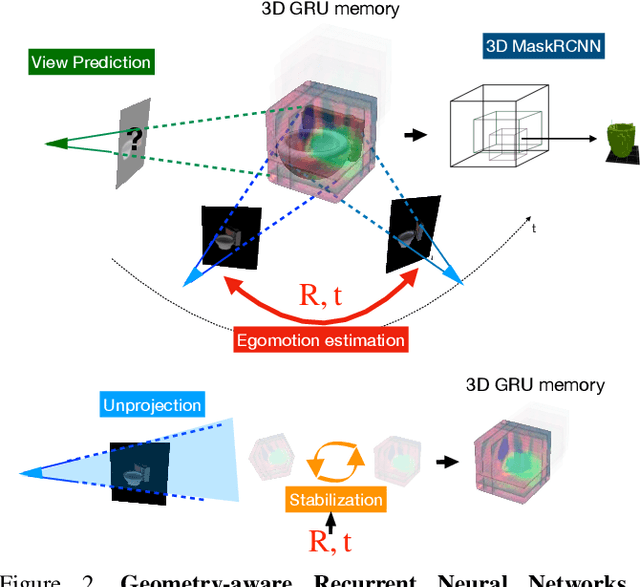
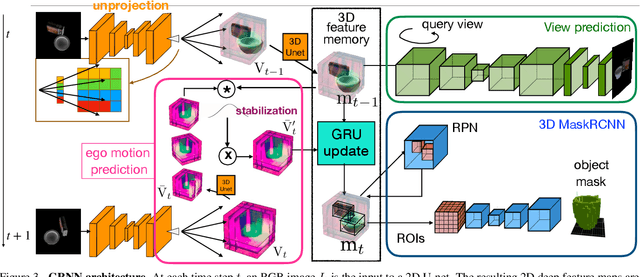
We integrate two powerful ideas, geometry and deep visual representation learning, into recurrent network architectures for mobile visual scene understanding. The proposed networks learn to "lift" 2D visual features and integrate them over time into latent 3D feature maps of the scene. They are equipped with differentiable geometric operations, such as projection, unprojection, egomotion estimation and stabilization, in order to compute a geometrically-consistent mapping between the world scene and their 3D latent feature space. We train the proposed architectures to predict novel image views given short frame sequences as input. Their predictions strongly generalize to scenes with a novel number of objects, appearances and configurations, and greatly outperform predictions of previous works that do not consider egomotion stabilization or a space-aware latent feature space. We train the proposed architectures to detect and segment objects in 3D, using the latent 3D feature map as input--as opposed to any input 2D video frame. The resulting detections are permanent: they continue to exist even when an object gets occluded or leaves the field of view. Our experiments suggest the proposed space-aware latent feature arrangement and egomotion-stabilized convolutions are essential architectural choices for spatial common sense to emerge in artificial embodied visual agents.
Geometry-Aware Recurrent Neural Networks for Active Visual Recognition
Nov 03, 2018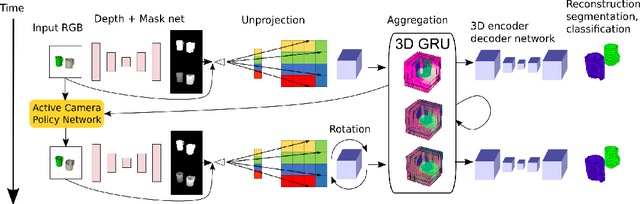
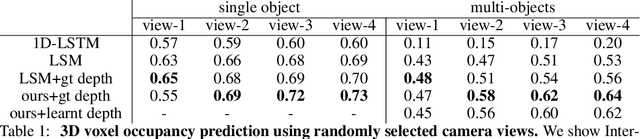


We present recurrent geometry-aware neural networks that integrate visual information across multiple views of a scene into 3D latent feature tensors, while maintaining an one-to-one mapping between 3D physical locations in the world scene and latent feature locations. Object detection, object segmentation, and 3D reconstruction is then carried out directly using the constructed 3D feature memory, as opposed to any of the input 2D images. The proposed models are equipped with differentiable egomotion-aware feature warping and (learned) depth-aware unprojection operations to achieve geometrically consistent mapping between the features in the input frame and the constructed latent model of the scene. We empirically show the proposed model generalizes much better than geometryunaware LSTM/GRU networks, especially under the presence of multiple objects and cross-object occlusions. Combined with active view selection policies, our model learns to select informative viewpoints to integrate information from by "undoing" cross-object occlusions, seamlessly combining geometry with learning from experience.